Clear Sky Science · de
ADAT neuartige zeitserienbewusste adaptive Transformator-Architektur für Gebärdensprachübersetzung
Die Kommunikation klären
Für Millionen gehörloser und schwerhöriger Menschen sind alltägliche Aufgaben wie ein Arztbesuch oder das Anschauen eines Wetterberichts oft schwieriger als nötig, einfach weil qualifizierte Gebärdensprachdolmetscher selten sind. Diese Arbeit stellt ein neues System der Künstlichen Intelligenz namens ADAT vor, das Gebärdensprachvideos genauer und effizienter in geschriebene Sätze übersetzt als viele bestehende Systeme und uns so näher an eine Echtzeit- und breit verfügbare Gebärdensprachübersetzung auf Telefonen, Tablets und Krankenhausrechnern bringt.
Warum Gebärdensprache für Computer schwer ist
Gebärdensprachen sind reichhaltige, komplexe Sprachen mit eigener Grammatik und basieren auf weit mehr als der Bewegung der Hände. Mimik, Körperhaltung und feine zeitliche Abstimmungen verändern die Bedeutung eines gebärdeten Satzes. Moderne Übersetzungssysteme verwenden oft ein leistungsfähiges KI-Design, das als Transformator bekannt ist und sehr gut darin ist, lange Sätze in gesprochener oder geschriebener Sprache zu erfassen. Bei hochfrequentem Video—30 bis 60 Bilder pro Sekunde—können diese Systeme jedoch langsam werden und Schwierigkeiten haben, die schnellen, feinen Bewegungen zu erkennen, die ein Zeichen vom anderen unterscheiden. Außerdem benötigen sie viel Rechenleistung und Trainingszeit, was die Aktualisierung erschwert, wenn sich Gebärdensprachen weiterentwickeln.
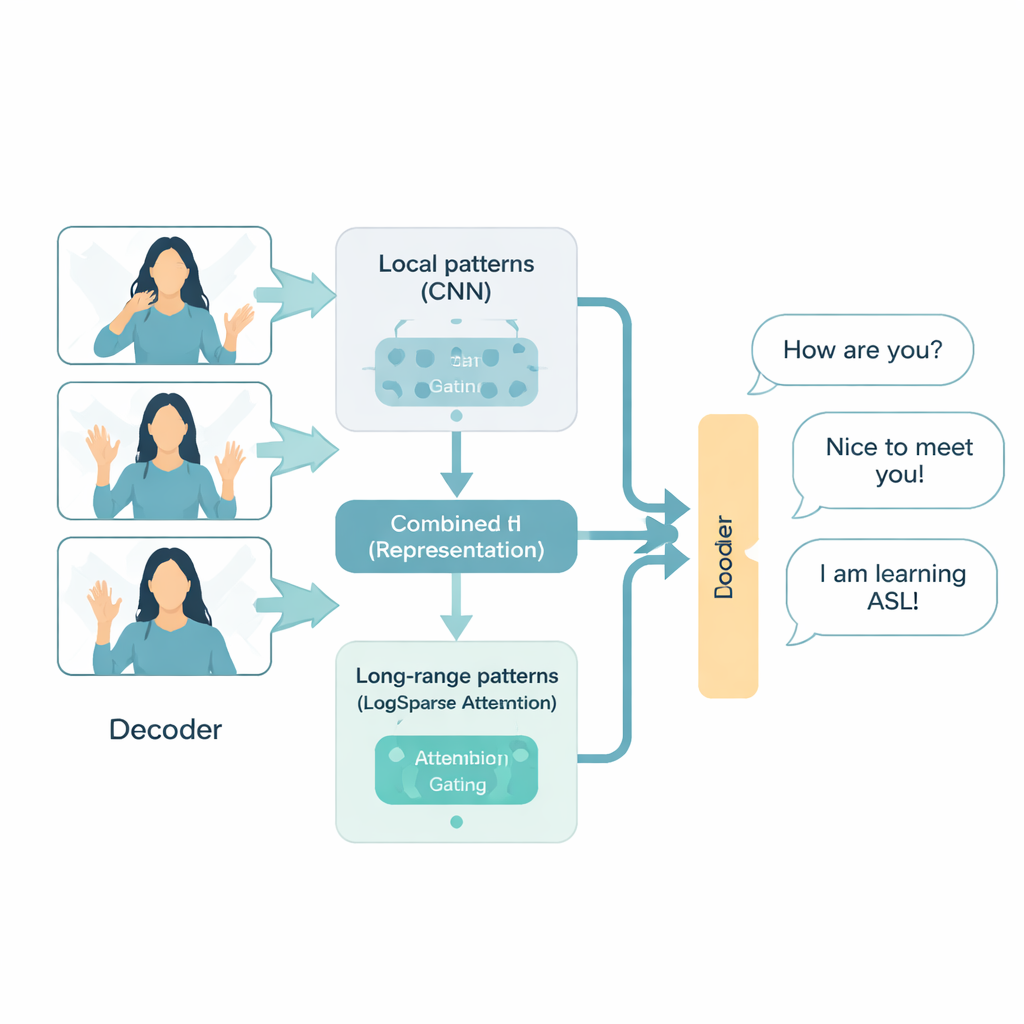
Eine intelligentere Art, Gebärden zu lesen
Die ADAT-Architektur ist speziell für Gebärdensprachvideo entworfen und behandelt es als Zeitreihe: einen schnellen Strom visueller Ereignisse, die sich über die Zeit entfalten. Sie kombiniert drei Ideen. Erstens nutzt sie Faltungsneuronale Netze, eine bewährte Bildtechnik, um lokale Muster wie Handformen und Gesichtssignale zu fokussieren. Zweitens verwendet sie eine effizientere Form der Attention, die selektiv auf Schlüsselmomente im Video zurückblickt, anstatt jedes Bild mit jedem anderen zu vergleichen. Drittens lernt ein adaptives „Tor“, wie detaillierte kurzfristige Informationen mit breiterem langfristigem Kontext zu verbinden sind und entscheidet im Lauf, was für jeden Satzteil wichtiger ist. Zusammen ermöglichen diese Komponenten ADAT, sowohl das schnelle Zucken eines Fingers als auch die Gesamtstruktur eines Gesprächs zu erfassen, ohne Rechenleistung zu verschwenden.
Von Gebärden zu Wörtern auf zwei Wegen
Die Gebärdensprachübersetzung kann in zwei Hauptschritte organisiert werden: zuerst die Erkennung der grundlegenden Einheiten des Gebärdens, sogenannte Glosses, und dann die Umwandlung dieser Glosses in gesprochene oder geschriebene Sprache. Dies wird als sign-to-gloss-to-text bezeichnet. Alternativ kann ein System versuchen, direkt in einem Schritt vom Video zum Text zu gelangen, sign-to-text genannt. Die Autoren testen ADAT in beiden Varianten. Sie vergleichen es mit mehreren starken Transformator-basierten Baselines, darunter ein bekanntes System namens SLTUNET, über drei Datensätze: ein großes deutsches Wettervorhersagekorpus, eine Sammlung der Indian Sign Language und einen neuen amerikanischen Gebärdensprach-Medizin-Datensatz, den die Autoren erstellt haben, um realistische Arzt–Patient-Interaktionen abzubilden.
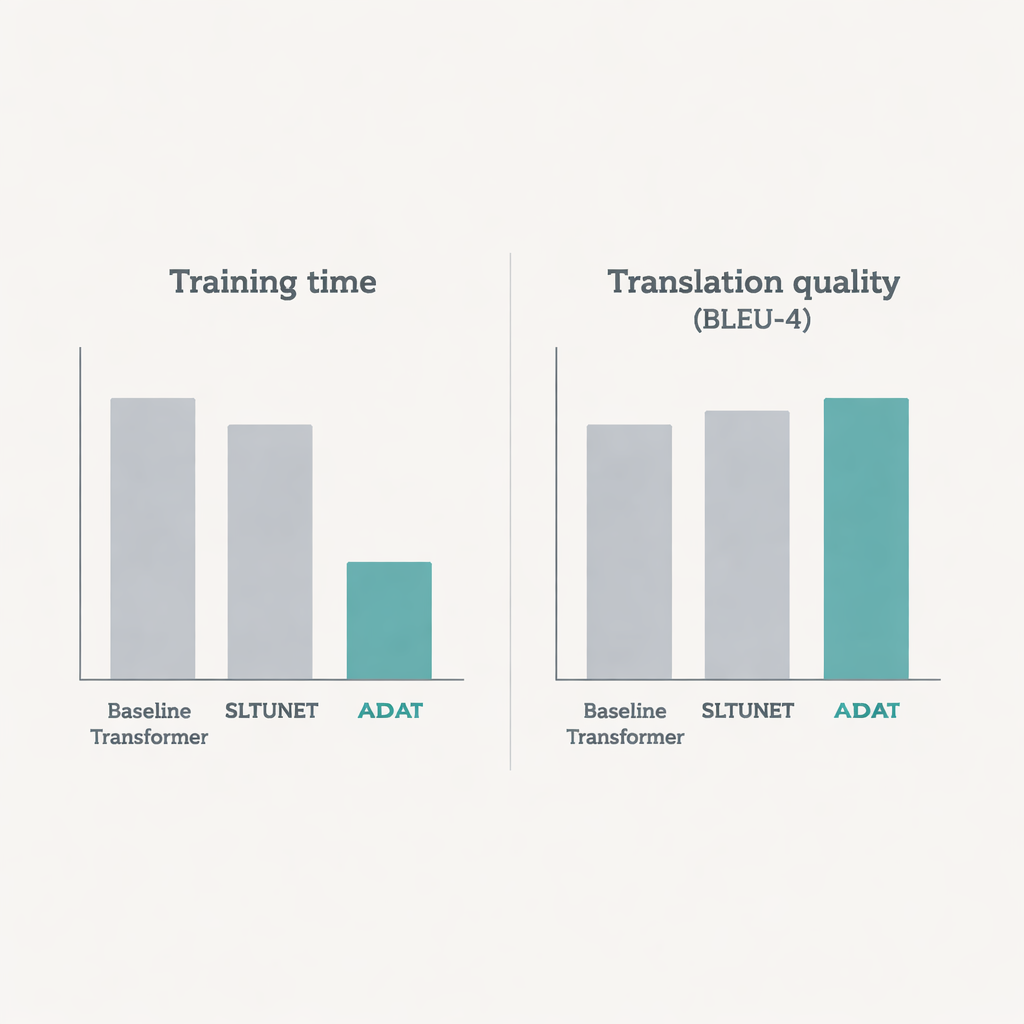
Schnelleres Training und präzisere Übersetzungen
In diesen Tests erreicht ADAT entweder die besten konkurrierenden Modelle oder übertrifft sie in der Übersetzungsqualität, gemessen mit den standardmäßigen BLEU-Werten, und trainiert dabei merklich schneller. Im zweistufigen sign-to-gloss-to-text-Setup liefert es ähnliche oder leicht bessere Werte als ein klassischer Transformator, reduziert aber die Trainingszeit im Mittel um etwa ein Fünftel. Im anspruchsvolleren direkten sign-to-text-Setup schlägt ADAT deutlich Encoder-only-, Decoder-only- und einheitliche Transformator-Baselines und verbessert oft die Genauigkeit um etwa einen Prozentpunkt oder mehr, wiederum bei rund 20 % schnellerem Training. Detaillierte Analysen der zugrundeliegenden Mathematik zeigen, dass ADATs selektivere Attention und Dual-Path-Design die Anzahl der erforderlichen Operationen deutlich reduzieren, insbesondere bei langen oder hochbildratenreichen Videos.
Neue Daten für kritische Gespräche
Um sicherzustellen, dass diese Methoden über Laborbedingungen hinaus anwendbar sind, führen die Autoren MedASL ein, den ersten amerikanischen Gebärdensprach-Datensatz mit Schwerpunkt auf medizinischer Kommunikation. Er besteht aus 500 einzigartigen, sorgfältig gestalteten Sätzen, die reale Interaktionen zwischen Patienten und Gesundheitsfachkräften simulieren, und enthält sowohl Gloss- als auch Textannotationen. Dieser medizinische Fokus ist wichtig, weil Missverständnisse in Krankenhaus oder Klinik ernste Folgen haben können und existierende Datensätze dieses Feld selten abdecken. ADAT erzielt starke Ergebnisse auf MedASL, wobei die Resultate gleichzeitig zeigen, wie herausfordernd es für jedes System ist, perfekt auf neue, realweltliche Sätze zu generalisieren.
Was das für den Alltag bedeutet
Kurz gesagt zeigt die Studie, dass wir Gebärdensprachübersetzungssysteme bauen können, die sowohl intelligenter als auch sparsamer sind: Sie benötigen weniger Zeit und Rechenleistung zum Training und erfassen dennoch die Feinheiten des Gebärdens besser. ADAT ist noch kein universell einsetzbarer Dolmetscher für jede Gebärdensprache in jeder Situation und liegt weiterhin hinter Systemen mit riesigen vortrainierten Modellen zurück. Aber indem es sich auf zeitkritische Videomuster und Effizienz konzentriert, weist es den Weg zu praktischen Werkzeugen, die eines Tages auf Alltagsgeräten laufen, mehrere Gebärdensprachen unterstützen und gehörlosen Nutzern in kritischen Situationen wie Gesundheitswesen, Notfallhilfe und öffentlichen Diensten die Kommunikation erleichtern könnten.
Zitation: Shahin, N., Ismail, L. ADAT novel time-series-aware adaptive transformer architecture for sign language translation. Sci Rep 16, 6551 (2026). https://doi.org/10.1038/s41598-026-36293-9
Schlüsselwörter: Gebärdensprachübersetzung, adaptiver Transformator, Zeitreihen-Attention, medizinisches ASL, zugängliche KI