Clear Sky Science · de
Meta-Lernen für Few-Shot-Erkennung offener Aufgaben
Warum es wichtig ist, KI mit sehr wenigen Beispielen zu lehren
Moderne KI-Systeme können Gesichter, Tiere und Alltagsgegenstände mit bemerkenswerter Genauigkeit erkennen – meist jedoch erst, nachdem sie Millionen von beschrifteten Bildern gesehen haben. In vielen realen Situationen, etwa bei der Diagnose einer seltenen Krankheit oder beim Erkennen eines neuen Defekttyps in einer Produktionslinie, stehen solche Datenmengen nicht zur Verfügung. Dieses Papier untersucht, wie man KI-Modelle so trainiert, dass sie neue visuelle Aufgaben aus nur einer Handvoll Beispiele lernen können, selbst wenn diese Aufgaben deutlich anders aussehen als das, worauf das Modell ursprünglich trainiert wurde. Vorgestellt wird eine Methode namens Open-MAML, die darauf abzielt, diese Art von flexiblem Lernen mit wenigen Daten zuverlässiger und vorhersehbarer zu machen.
Von festen Klassenübungen zu offenen Kurztests
Die meisten Studien zum „Few-Shot-Lernen“ bewerten KI-Systeme unter streng kontrollierten Bedingungen. Das Modell wird auf sehr ähnlichen Aufgaben trainiert und getestet, zum Beispiel immer mit genau fünf Kategorien (sogenannte „5-way“) und einem Beispiel pro Kategorie („1-shot“). Das ist vergleichbar damit, einen Schüler nur mit Fünf-Fragen-Tests zu trainieren, bei denen pro Fragetyp nur ein Übungsbeispiel gegeben ist. Reale Einsätze sind deutlich unordentlicher: Die Anzahl der Kategorien kann sich ändern, und die Menge der beschrifteten Daten pro Kategorie kann steigen oder fallen. Die Autoren bezeichnen diese realistischere Situation als das open-task-Setting, in dem Modelle Aufgaben mit unterschiedlichen Klassenzahlen und unterschiedlichen Beispielmengen bewältigen müssen, als sie jemals während des Trainings gesehen haben. 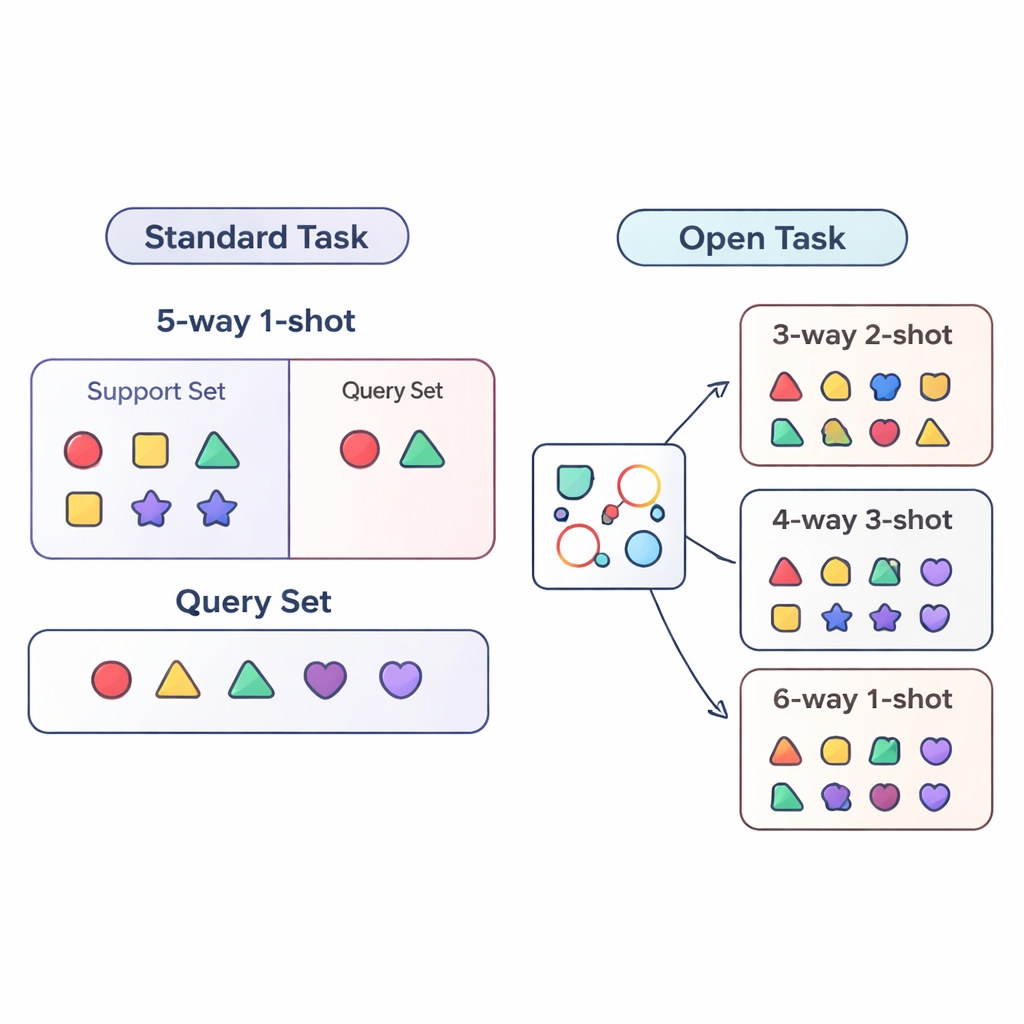
Neu definieren, wie wir Few-Shot-Lerner testen
Um diese open-task-Welt systematisch zu untersuchen, schlägt das Papier drei Bewertungsregime vor. Im cross-way-Regime ändert sich nur die Anzahl der Klassen: Das Modell könnte auf fünf Klassen trainiert werden, aber auf drei oder fünfzehn getestet werden. Im cross-shot-Regime variiert die Anzahl der Beispiele pro Klasse, von einem einzelnen beschrifteten Bild bis zu mehreren. Der schwierigste Fall ist cross-way–cross-shot, bei dem sowohl die Anzahl der Klassen als auch die Datenmenge pro Klasse gleichzeitig variieren. Die Autoren prüfen außerdem, was passiert, wenn sich der visuelle Stil der Daten verschiebt, etwa beim Training auf einem generischen Objekt-Datensatz und Testen auf einem feingliedrigen Vogel-Datensatz. Diese Szenarien sind so gestaltet, dass sie offenlegen, ob eine Methode wirklich über ein einziges, festes Trainingsrezept generalisieren kann.
Wie Open-MAML sich unterwegs anpasst
Open-MAML baut auf einer verbreiteten Meta-Learning-Strategie namens Model-Agnostic Meta-Learning (MAML) auf, die ein Modell so trainiert, dass es sich mit wenigen Gradienten-Schritten schnell an eine neue Aufgabe anpassen kann. Standard-MAML setzt jedoch voraus, dass die Anzahl der Kategorien zur Testzeit mit der des Trainings übereinstimmt, und verwendet eine feste letzte Klassifikationsschicht. Open-MAML führt drei zentrale Anpassungen ein, um diese Einschränkung zu überwinden. Erstens verwendet es dynamische Klassifikator-Konstruktion: Wenn eine neue Aufgabe mehr Klassen hat als zuvor, erzeugt es zusätzliche Ausgabeeinheiten, indem es den Durchschnitt der vorhandenen Einheiten kopiert und dem Modell so einen neutralen, aber sinnvollen Startpunkt gibt. Zweitens passt es die innere Lernrate basierend auf der Anzahl der Klassen und Beispiele der Aufgabe an, sodass die Anpassung stabil bleibt, unabhängig davon, ob die Daten knapp oder reichlich sind. Drittens ergänzt es einen Regularisierer namens AdaDropBlock, der während des Trainings vorübergehend zusammenhängende Regionen in den Merkmalskarten ausblendet und das Modell dazu anregt, vielfältigere visuelle Hinweise zu nutzen, statt sich auf kleine, spröde Details zu überanpassen. 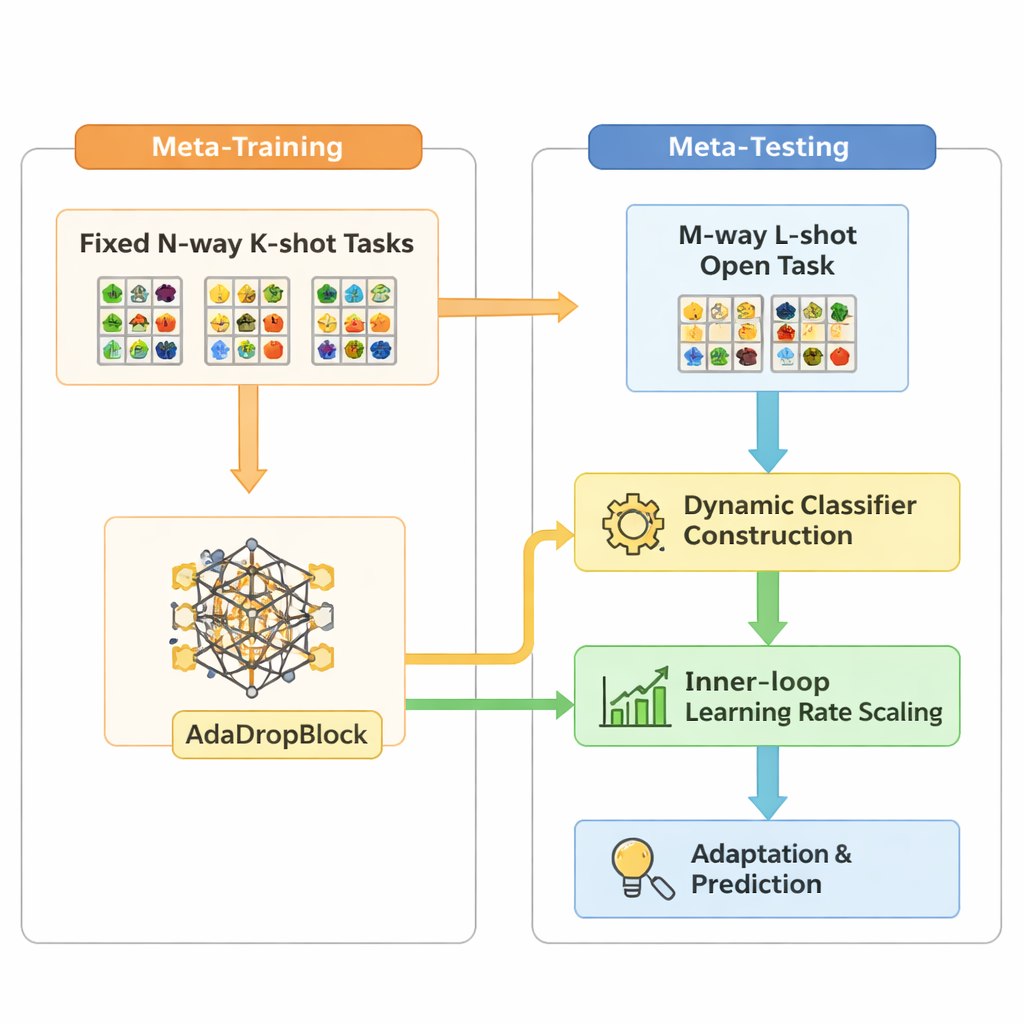
Flexible Lernverfahren auf die Probe gestellt
Die Forschenden bewerten Open-MAML auf standardisierten Few-Shot-Benchmarks und in den neuen open-task-Szenarien und vergleichen es mit mehreren bekannten Baselines. Dazu gehören Modelle, die pro Aufgabe von Grund auf neu trainiert werden, Modelle mit stark vortrainiertem Feature-Extraktor plus feinabgestimmtem Klassifikator und metrische Methoden, die Bilder anhand ihrer Entfernung zu Klassen-„Prototypen“ klassifizieren. Alle Methoden nutzen dasselbe Backbone-Netzwerk, sodass Unterschiede aus der Lernstrategie und nicht aus der Architektur resultieren. Über zehntausende Testaufgaben hinweg erzielt Open-MAML konsequent höhere Genauigkeit—typischerweise 1–7 Prozentpunkte besser, wenn sich nur die Anzahl der Klassen oder der Beispiele ändert, und 3–6 Punkte besser, wenn beides variiert. Die Zugewinne sind auf schwierigeren Settings mit mehr Klassen, mehr Shots oder einem Wechsel zum Vogel-Datensatz noch ausgeprägter, was darauf hindeutet, dass seine Adaptationsmechanismen in komplexem, unbekanntem Terrain tatsächlich helfen.
Was das für reale KI-Systeme bedeutet
Für eine allgemeine Leserschaft lautet die Kernbotschaft: Nicht alle Few-Shot-Lerner sind gleich, sobald man das Laborumfeld verlässt. Eine Methode, die auf einem einzigen, festen Benchmark glänzt, kann straucheln, wenn sich die Anzahl der Kategorien oder die Menge der beschrifteten Daten ändert. Open-MAML zeigt, dass durch explizites Planen für solche strukturellen Änderungen—etwa den Klassifikator wachsen oder schrumpfen zu lassen, die Lernrate mit der Aufgabengröße zu skalieren und Merkmale auf aufgabenunabhängige Weise zu regularisieren—KI-Systeme besser mit den wechselnden Bedingungen zurechtkommen können, denen sie in der Praxis begegnen. In Bereichen wie der medizinischen Bildgebung, der Satellitenüberwachung oder der industriellen Inspektion, wo sowohl die Kategorien als auch die Verfügbarkeit von Labels ständig im Fluss sind, könnte diese Art von Open-Task-Robustheit Few-Shot-Learning deutlich nützlicher außerhalb sorgfältig kuratierter Forschungsbenchmarks machen.
Zitation: Han, X., Shi, D., Wang, Z. et al. Meta-learning for few-shot open task recognition. Sci Rep 16, 5624 (2026). https://doi.org/10.1038/s41598-026-36291-x
Schlüsselwörter: Few-Shot-Lernen, Meta-Lernen, Erkennung offener Aufgaben, Bildklassifikation, Generalisierung