Clear Sky Science · de
IASUNet: Gebäudeerkennung basierend auf verbessertem Attention Swin-UperNet
Warum jedes Gebäude aus dem All zu erkennen wichtig ist
Mit dem Wachstum von Städten und dem Klimawandel ist es entscheidend geworden, genau zu wissen, wo Gebäude stehen — und wie sie sich im Laufe der Zeit verändern. Von der Planung sichererer Wohnviertel und der Aufdeckung illegaler Bebauung bis hin zur Unterstützung der Katastrophenhilfe nach Überschwemmungen oder Erdbeben sind detaillierte Gebäudekarten heute ein zentraler Baustein für intelligente, widerstandsfähige Städte. Dieses Papier stellt IASUNet vor, ein neues KI‑System, das automatisch Gebäude aus hochauflösenden Satellitenbildern mit bemerkenswerter Genauigkeit erkennt, selbst in unordentlichen, dicht bebauten Realweltszenen.
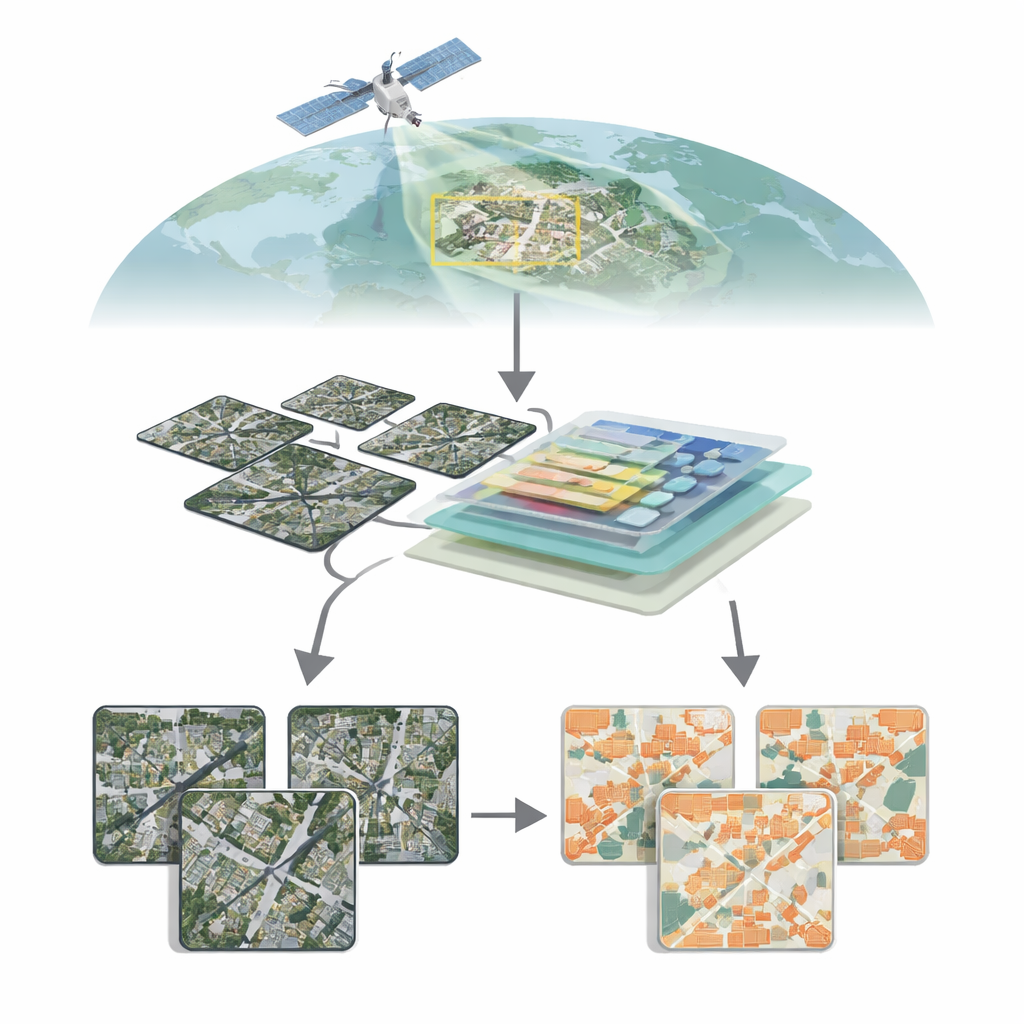
Städte von oben sehen
Moderne Satelliten können die Erde mit außergewöhnlicher Detailgenauigkeit abbilden und einzelne Dachflächen, Straßen und sogar schmale Gassen sichtbar machen. Aus diesem Pixelmeer saubere Gebäudekarten zu erstellen, ist jedoch alles andere als trivial. Gebäude unterscheiden sich stark in Größe, Form, Farbe und Umfeld: Glastürme in Innenstädten, eingeschossige Häuser in Vororten, verstreute landwirtschaftliche Gebäude auf dem Land. In ländlichen oder gemischten Gebieten nehmen Gebäude oft nur einen winzigen Bruchteil des Bildes ein, während Vegetation, Boden und Wasser dominieren. Traditionelle Methoden der Computer Vision, hauptsächlich auf Convolutional Neural Networks basierend, tun sich schwer damit, das große Ganze einer Szene zu erfassen und zugleich feine Begrenzungen zu respektieren, was zu übersehenen kleinen Strukturen oder verwaschenen Kanten führen kann.
Eine schlauere Aufmerksamkeit für Details
IASUNet geht diese Herausforderungen an, indem es zwei leistungsfähige Ideen kombiniert: einen auf Transformern basierenden Encoder namens Swin Transformer und einen flexiblen Decoder namens UperNet. Der Swin Transformer zerlegt ein Bild in viele kleine Patches und lernt, wie diese über die gesamte Szene hinweg zueinander in Beziehung stehen, statt nur durch ein festes Fenster zu schauen. Das hilft dem Modell, breiteren Kontext zu erfassen — zum Beispiel ob ein helles Rechteck innerhalb eines dichten Stadtblocks oder in einem isolierten Feld liegt — und dabei dennoch Details zu erhalten. Darüber hinaus integrieren die Autorinnen und Autoren an mehreren Stellen einen Aufmerksamkeitsmechanismus namens Convolutional Block Attention Module (CBAM). CBAM lernt, Kanal für Kanal und Region für Region, welche Bildmerkmale wahrscheinlich zu Gebäuden gehören und welche Hintergrundstörung sind, hebt erstere hervor und unterdrückt letztere, bevor der Decoder alles wieder zu einer vollständigen Gebäudekarte zusammensetzt.
Die Waage ausgleichen, wenn Gebäude selten sind
Ein weiteres praktisches Hindernis ist die Klassenungleichheit: In vielen Satellitenszenen zeigen die meisten Pixel Straßen, Felder, Bäume oder Wasser, während Gebäude nur kleine Inseln einnehmen. Standard‑Trainingsmethoden neigen dazu, das zu bevorzugen, was am häufigsten vorkommt, wodurch das Risiko besteht, dass seltenere Gebäude nur nachrangig behandelt werden. Um dem entgegenzuwirken, passen die Autorinnen und Autoren eine Verlustfunktion namens Focal Cross‑Entropy an. Diese Strategie reduziert den Einfluss „einfacher“ Hintergrundpixel und verstärkt die Wirkung schwer zu klassifizierender Gebäudepixel während des Trainings. Infolgedessen schenkt das Modell kleinen, schwachen oder ungewöhnlichen Strukturen, die sonst übersehen würden, mehr Aufmerksamkeit und verbessert so die Erkennungsrate, ohne die Karte mit vielen Fehlalarmen zu überfluten.
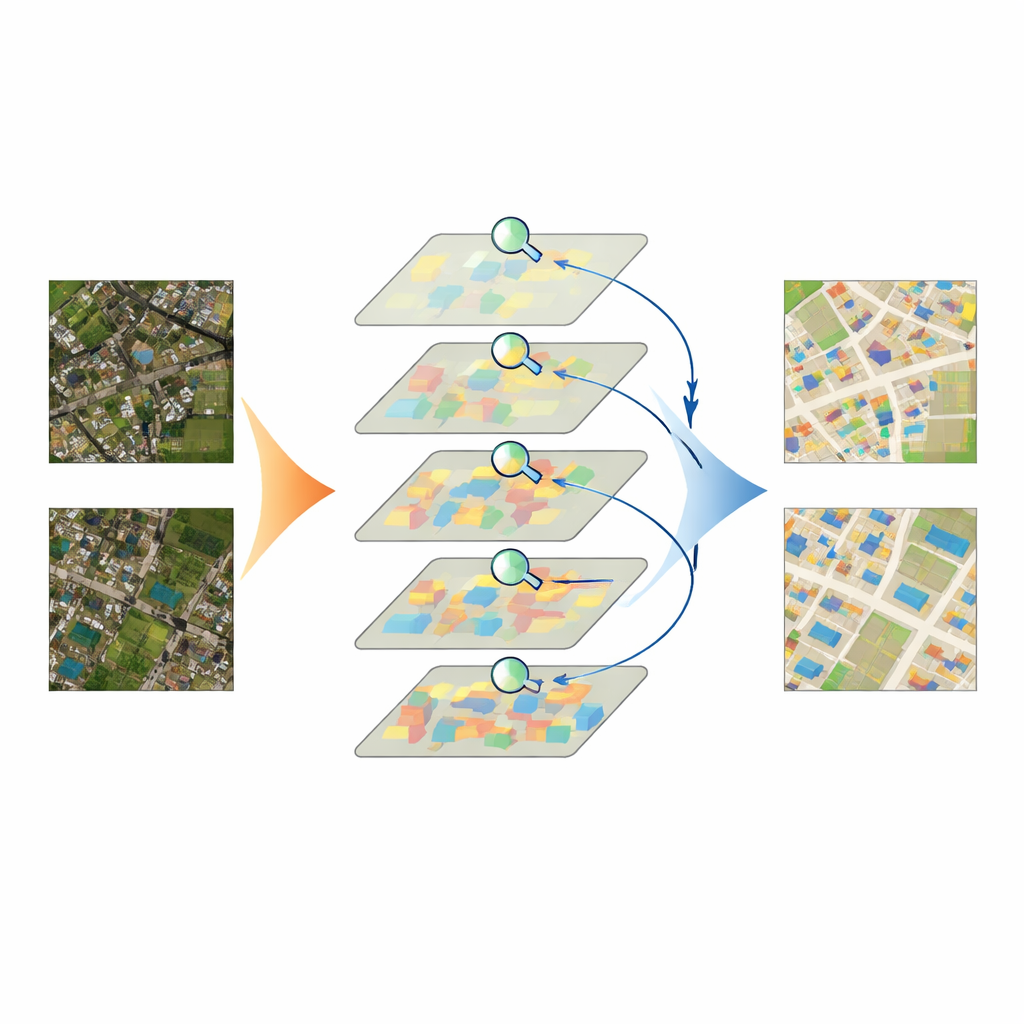
Das Modell auf die Probe stellen
Das Team testete IASUNet auf drei bekannten Gebäudedatensätzen aus Deutschland, Neuseeland und den Vereinigten Staaten sowie auf einer sorgfältig kuratierten Sammlung chinesischer Satellitenbilder, die sie selbst vorbereitet und qualitätsgeprüft haben. Über diese Benchmarks hinweg erreichte IASUNet durchgängig vergleichbare oder bessere Ergebnisse als führende Ansätze, einschließlich starker Faltungsnetzwerke und anderer Transformer‑basierter Modelle. Auf dem ultra‑detaillierten Potsdam‑Datensatz erzielte es nahezu perfekte Überlappung zwischen vorhergesagten und tatsächlichen Gebäuderegionen, während es gleichzeitig mit praktischen Geschwindigkeiten auf moderner Grafikhardware lief. Selbst in unregelmäßigeren Landschaften, in denen Gebäude verstreut, teilweise verdeckt oder eng beieinander liegen, zeichnete IASUNet sauberere Umrisse, erfasste mehr kleine Ziele und vermied viele der Auslassungen und Randfehler, die bei konkurrierenden Methoden auftreten.
Von Pixeln zu besseren Städten
Alltäglich formuliert zeigt die Studie, dass wir Computern inzwischen beibringen können, Stadtbilder aus dem Orbit mit bislang unerreichter Klarheit zu lesen. Indem das Modell die „Aufmerksamkeit“ gezielt auf die richtigen Bildbereiche richtet und seltene, aber entscheidende Gebäudepixel bewusst höher gewichtet, verwandelt IASUNet rohe Satellitenbilder in genaue, aktuelle Gebäudekarten bei moderatem zusätzlichem Rechenaufwand. Solche Karten können in die Stadtplanung, Energie‑ und Heat‑Island‑Analysen, Flächennutzungsregelungen und in schnelle Schadensbewertungen nach Katastrophen einfließen. Obwohl die Arbeit technisch ist, ist ihre Schlussfolgerung einfach: Intelligentere KI kann Entscheidungsträgern ein schärferes, verlässlicheres Bild der bebauten Umwelt liefern und so helfen, Städte sicherer und nachhaltiger wachsen zu lassen.
Zitation: Zhang, H., Ma, Y., Wang, G. et al. IASUNet: building extraction based on impoved attention Swin-UperNet. Sci Rep 16, 7969 (2026). https://doi.org/10.1038/s41598-026-36270-2
Schlüsselwörter: Fernerkundung, Gebäudeerkennung, Semantische Segmentierung, Transformer-Netzwerke, Stadtplanung