Clear Sky Science · de
Unsicherheit und Inkonsistenz der Effekte nicht‑pharmazeutischer COVID‑19‑Maßnahmen bei mehreren konkurrierenden statistischen Modellen
Warum diese Studie gerade jetzt wichtig ist
Die COVID‑19‑Pandemie veränderte das Alltagsleben durch Schulschließungen, Ausgangsbeschränkungen, Maskenpflichten und viele andere Regeln. Regierungen argumentierten, diese nicht‑pharmazeutischen Interventionen (NPIs) seien nötig, um das Virus zu bremsen. Aber wie belastbar war die Evidenz dafür, dass jede einzelne Maßnahme tatsächlich wirkte, und wie sicher waren Wissenschaftler in ihren Schätzungen? Diese Studie nimmt die offizielle Analyse der deutschen COVID‑19‑Politik erneut in den Blick und zeigt, dass ein Großteil der vermeintlichen Genauigkeit darüber, was half und um wie viel, eine Illusion war.
Ein neuer Blick auf Deutschlands Pandemie‑Fahrplan
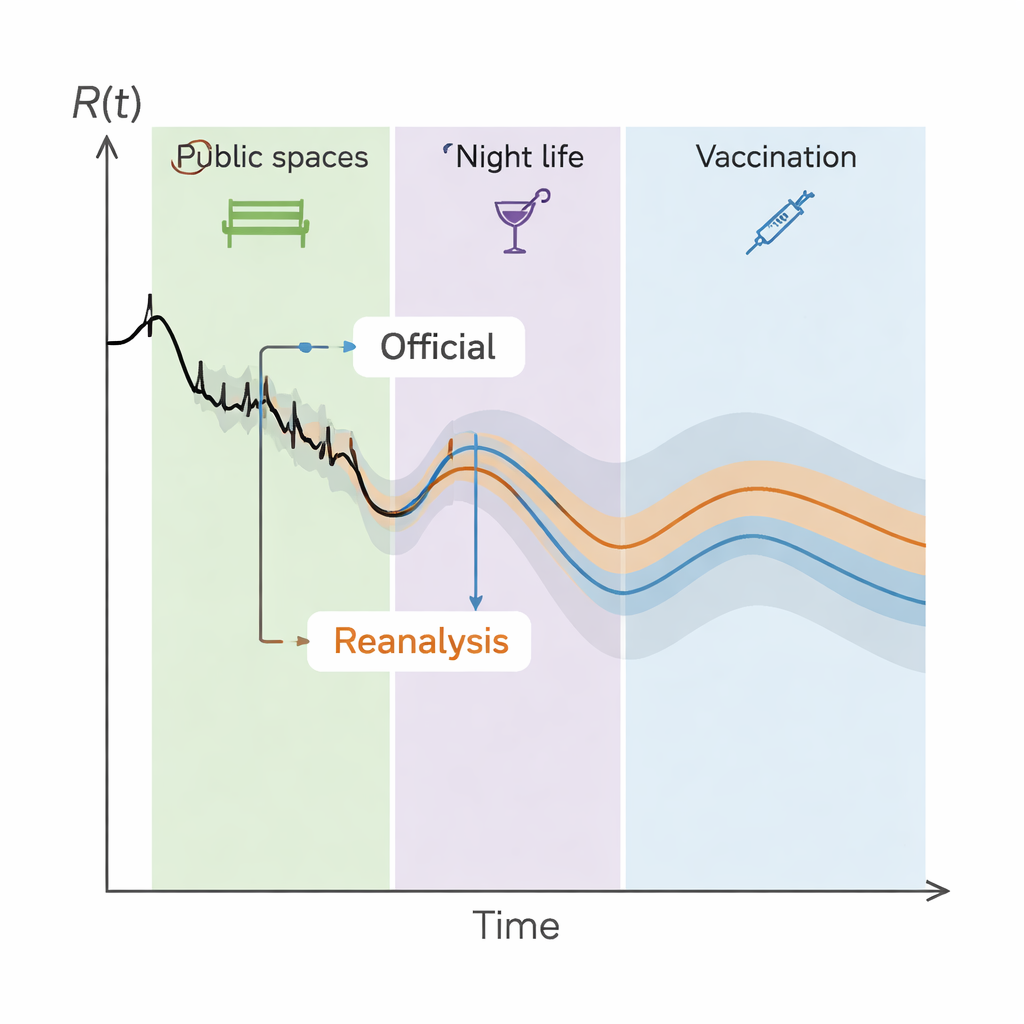
Das deutsche Gesundheitsministerium beauftragte eine umfangreiche Analyse, die StopptCOVID‑Studie, um abzuschätzen, wie verschiedene Maßnahmen die Ausbreitung des Virus in den Bundesländern beeinflussten. Die ursprüngliche Arbeit nutzte ein statistisches Modell, das die zeitlich veränderliche Reproduktionszahl R(t) – wie viele Neuinfektionen ein Fall im Mittel verursacht – mit mehr als 50 Politik‑ und Kontextvariablen verband, darunter Impfungen und Jahreszeit. Das Modell lieferte präzise Zahlen dazu, wie sehr etwa Schließungen öffentlicher Räume, Einschränkungen des Nachtlebens oder Maskenpflichten R(t) senkten, und diese Zahlen wurden mit scheinbar engen Konfidenzintervallen berichtet, was große Gewissheit suggerierte.
Was die Reanalyse prüfen wollte
Das neue Forscherteam betrachtete den deutschen Bericht als Gegenstand einer unabhängigen Prüfung. Sie behielten dieselben grundlegenden Eingangsdaten und epidemiologischen Annahmen bei, verwendeten jedoch neun verschiedene, weithin akzeptierte statistische Ansätze, um zu prüfen, wie robust die ursprünglichen Ergebnisse tatsächlich waren. Ihr Fokus war bewusst eng: Statt darüber zu streiten, welches biologische Epidemiemodell das beste sei, fragten sie, wie stark sich die Antworten änderten, wenn man statistische Unsicherheiten ernst nahm, insbesondere bei Zeitreihen, die viele Regionen über lange Zeiträume verfolgen und Dutzende sich überlappender Maßnahmen enthalten.
Versteckte statistische Fallstricke in der Originalstudie
Zwei Probleme erwiesen sich als zentral. Erstens nahm das offizielle Modell an, dass der unerklärte Anteil der Daten – die Residuen – von Tag zu Tag zufällig sei. Tatsächlich zeigten die Residuen, wenn man sie zeitlich für jedes Bundesland darstellte, klare Laufmuster und starke Autokorrelation. Das bedeutet, dass die Fehler von gestern mit denen von heute verknüpft waren, wodurch grundlegende Regressionannahmen verletzt wurden und die Fehlerbalken aus Standardformeln viel zu optimistisch sind. Zweitens wurden viele Maßnahmen zeitgleich oder kurz nacheinander im ganzen Land eingeführt oder verschärft. Das erzeugte starke Multikollinearität: Die Aktivierungsmuster verschiedener NPIs waren so ähnlich, dass das Modell Mühe hatte, sie auseinanderzuhalten. Unter diesen Bedingungen können Schätzungen für einzelne politische Effekte stark schwanken oder bei kleinen Modelländerungen sogar ihr Vorzeichen wechseln, was erneut jede Eindruck von Präzision untergräbt.
Was belastbar bleibt und was nicht
Über die konkurrierende Modellauswahl hinweg fanden die Forschenden, dass die offiziellen Konfidenzintervalle deutlich breiter hätten sein müssen. Wenn Autokorrelation und Kollinearität rigoroser behandelt werden, lassen sich die meisten NPIs nicht zuverlässig mit Veränderungen von R(t) verbinden. Das bedeutet nicht, dass die Maßnahmen keine Wirkung hatten; es bedeutet, dass die verfügbaren Daten und Methoden sie nicht zuverlässig auseinanderhalten können. Einige Assoziationen sind robuster: Impfungen stechen als klare Reduktion der Transmission hervor, und es gibt starke, konsistente Hinweise auf ein saisonales Muster von COVID‑19. Einschränkungen für öffentliche Räume, Nachtleben und bestimmte Dienstleistungssektoren sowie die strengsten Regeln in der Kinderbetreuung tauchen ebenfalls als mögliche echte Effekte auf, doch auch dort ist die genaue Größenordnung des Nutzens hochgradig unsicher und kann teilweise mit frühen, breit angelegten Maßnahmen wie allgemeiner physischer Distanzierung verflochten sein.
Lektionen für künftige Pandemieentscheidungen
Für Nicht‑Spezialisten lautet die Kernbotschaft: Übersichtlich wirkende Tabellen, die Maßnahmen nach Wirksamkeit ordnen, können irreführend sein, wenn sie auf komplexen, verrauschten Daten basieren. Die Autorinnen und Autoren argumentieren, dass Deutschlands Vorgehen – und ein großer Teil der internationalen Zeitreihenliteratur zu COVID‑19‑Maßnahmen – die Unsicherheit unterschätzte und daher die Präzision, mit der man einzelne Interventionen beurteilen kann, überschätzte. Sie fordern, Evaluationen bereits in die Gestaltung von Maßnahmen einzubauen: ausreichende Beobachtungszeiträume zuzulassen, qualitativ bessere Daten zu sammeln, moderne Zeitreihenmethoden zu verwenden und einflussreiche Modelle unabhängigen Überprüfungen zu unterziehen. Ohne solche Sorgfalt laufen Regierungen Gefahr, weitreichende Maßnahmen auf einer fragilen statistischen Grundlage zu treffen oder zu verteidigen, und der Öffentlichkeit könnte mehr Vertrauen in diese Zahlen vermittelt werden, als sie rechtfertigen.
Zitation: Müller, B., Padberg, I., Lorke, M. et al. Uncertainty and inconsistency of COVID-19 non-pharmaceutical intervention effects with multiple competitive statistical models. Sci Rep 16, 5767 (2026). https://doi.org/10.1038/s41598-026-36265-z
Schlüsselwörter: COVID‑19‑Interventionen, Bewertung der Pandemiepolitik, statistische Unsicherheit, Deutschland, nicht‑pharmazeutische Maßnahmen