Clear Sky Science · de
Schwach überwachtes Kolorektaldrüsen-Segmentieren durch selbstüberwachtes Lernen und auf Aufmerksamkeit basierendes Pseudo-Labeling
Warum das für die Krebsdiagnose wichtig ist
Wenn ein Pathologe eine Kolonbiopsie unter dem Mikroskop betrachtet, gehört die Form und Anordnung winziger röhrenförmiger Strukturen, sogenannter Drüsen, zu den wichtigsten Hinweisen auf die Schwere eines Krebses. Jede Drüse von Hand sorgfältig nachzuzeichnen ist langsam, teuer und schwer zwischen Kliniken zu standardisieren. Diese Studie zeigt, wie künstliche Intelligenz lernen kann, diese Drüsen fast so gut wie menschliche Expertinnen und Experten nachzuzeichnen, dabei aber weit weniger detaillierte menschliche Kennzeichnungen benötigt — was die Diagnostik von kolorektalem Krebs potenziell beschleunigen und präzisieren könnte.
Die Herausforderung, jede kleine Kontur zu zeichnen
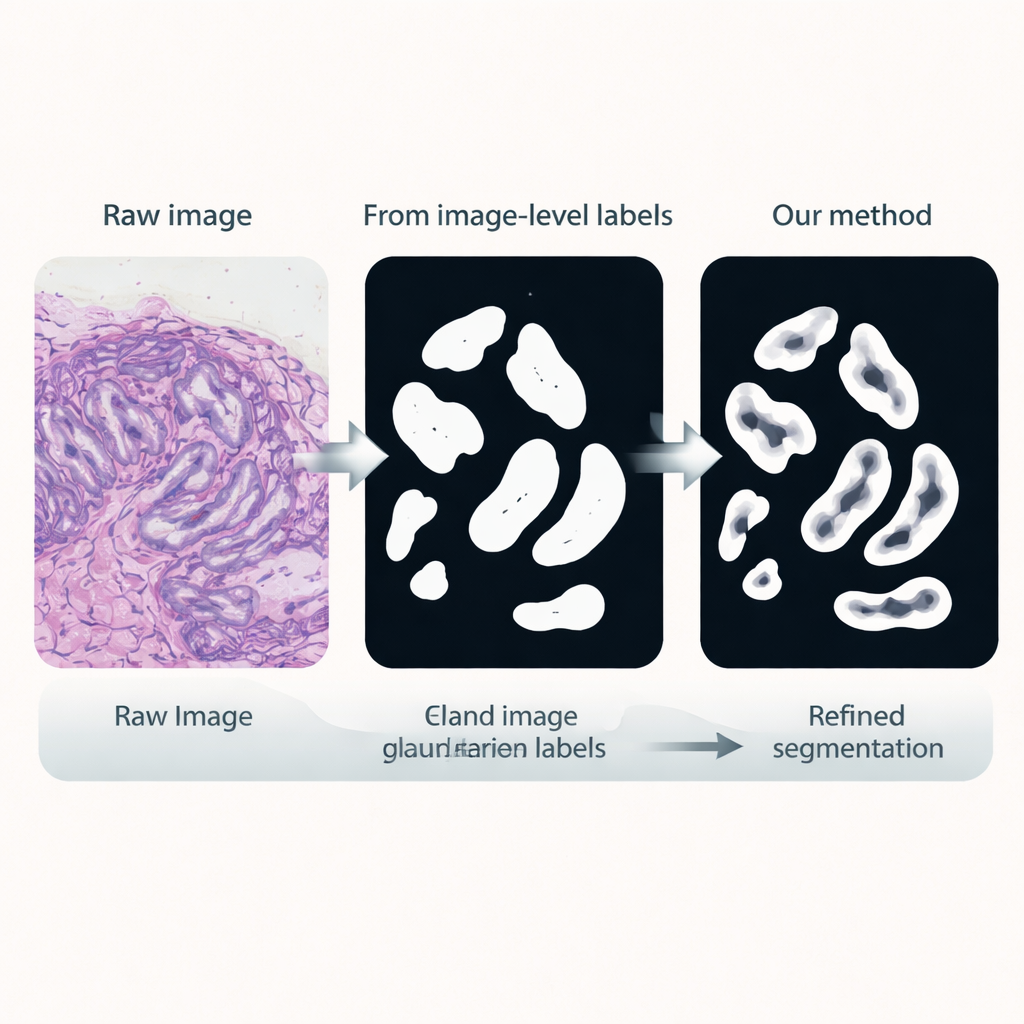
Kolorektales Karzinom zählt zu den weltweit häufigsten und tödlichsten Krebserkrankungen; die Einstufung ihrer Schwere hängt stark vom Aussehen der Drüsen ab. In gesundem oder frühem Gewebe wirken Drüsen wie ordentliche, runde Röhren; in aggressiven Tumoren werden sie gezackt, verschmolzen oder kaum noch erkennbar. Computer können darauf trainiert werden, jede Drüse zu segmentieren oder „auszufüllen“, um automatische Messungen zu ermöglichen, aber traditionelle Deep-Learning-Systeme benötigen aufwändige Pixel-für-Pixel-Konturen, die von Expert:innen gezeichnet werden. In der Praxis sind einfacher zu beschaffende Labels hingegen auf Bild- oder Kachelebene: etwa ob eine Gewebekachel Drüsen enthält oder ob sie gutartig beziehungsweise bösartig ist.
Ein KI beibringen aus unbeschrifteten und schwach beschrifteten Schnitten
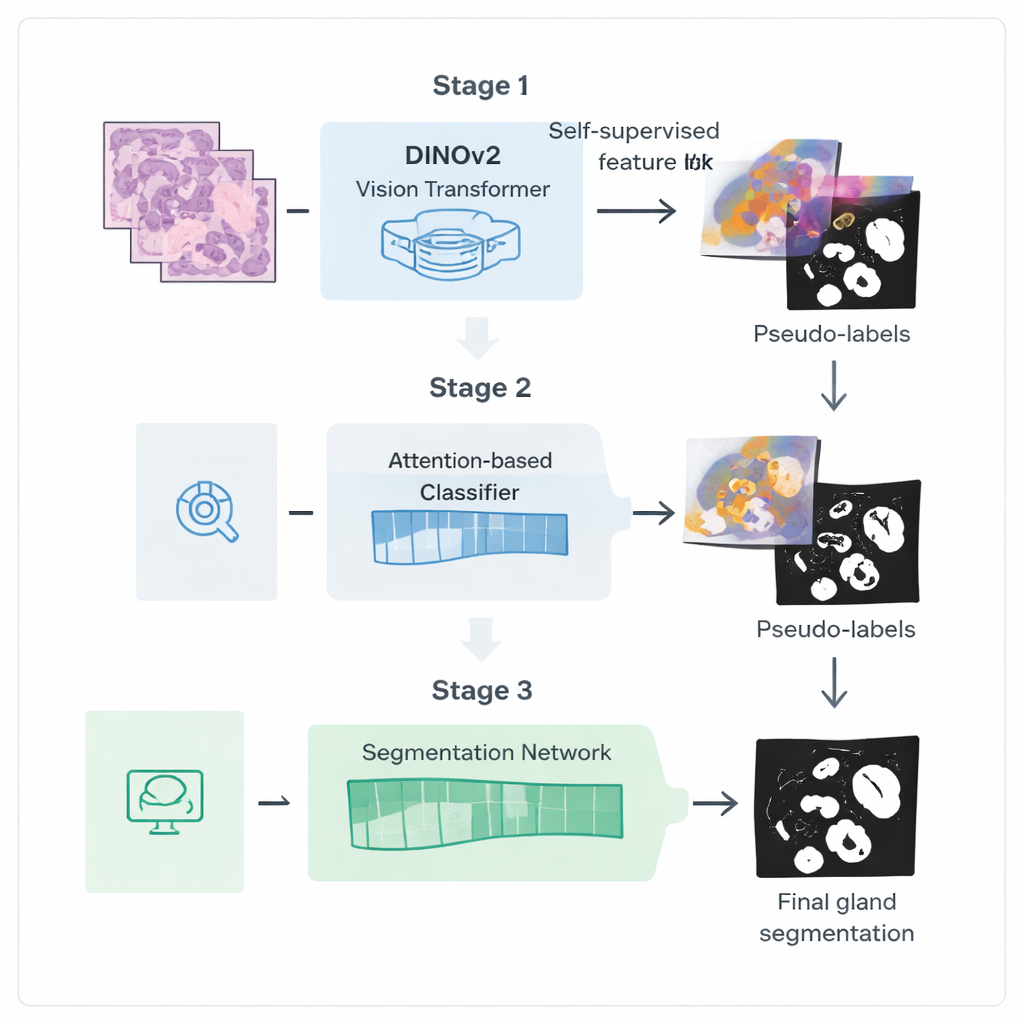
Die Autorinnen und Autoren stellen eine dreistufige Trainingspipeline vor, die darauf ausgelegt ist, mehr Nutzen aus solchen schwächeren Labels zu ziehen. Zunächst starten sie mit einem leistungsfähigen Vision-Modell namens DINOv2, ursprünglich auf Naturfotos trainiert, und setzen es tausenden unbeschrifteter Kolonbiopsiebilder aus. Indem das Modell verschiedene Ansichten desselben Gewebe-Patches aufeinander abgleicht, lernt es visuelle Merkmale, die an die Farben und Texturen histologischer Schnitte angepasst sind, ganz ohne Annotationen. Dieser Schritt erzeugt einen spezialisierten „Encoder“, der Rohbilder in reichhaltige interne Repräsentationen überführt, die drüsenähnliche Strukturen erfassen.
Die KI zeigen lassen, wo sie hinschaut
Im zweiten Schritt wird dieser Encoder in ein Klassifizierungsnetzwerk eingespeist, das nur Bild- oder Kachel-Labels benötigt, etwa ob Drüsen vorhanden sind. Ein Aufmerksamkeitsmechanismus im Netzwerk lernt, Regionen des Bildes höher zu gewichten, die für seine Entscheidung am wichtigsten sind. Diese Aufmerksamkeitskarten heben effektiv hervor, wo das Netzwerk „glaubt“, dass sich Drüsen befinden. Die Forschenden wandeln diese weichen Heatmaps mittels Kombination und Schwellenwertsetzung in grobe binäre Masken um und bereinigen sie anschließend mit einer probabilistischen Glättungstechnik, dem Conditional Random Field. Das Ergebnis sind verfeinerte Pseudo-Labels: computergenerierte Drüsenumrisse, die nicht perfekt, aber ausreichend gut sind, um ein spezialisierteres Segmentierungsmodell zu leiten.
Drüsengrenzen schärfen
Im dritten Schritt wird ein dediziertes Segmentierungsnetzwerk unter Verwendung dieser Pseudo-Labels als Ersatz für manuelle Annotationen trainiert. Es nutzt den feinabgestimmten Encoder wieder und fügt einen leichten Decoder-Kopf hinzu, der Merkmale zurück in eine detaillierte Drüsenmaske überführt. Entscheidend ist, dass die während des Trainings verwendete Verlustfunktion Grenzen stärker gewichtet: Fehler, die die Drüsenränder verzerren, werden stärker bestraft als kleine Fehler im Inneren. Dieses randbewusste Training fördert scharfe, anatomisch realistische Konturen, die für präzise Messungen von Drüsenform und -trennung unerlässlich sind.
Wie gut funktioniert das in der Praxis?
Das Team testete die Methode an zwei Standard-Benchmarks für koloniales Gewebe. Auf dem GlaS-Datensatz übertraf ihr schwach überwachter Ansatz nicht nur andere Methoden mit begrenzten Labels, sondern kam in mehreren Metriken an klassische vollüberwachte Systeme heran oder übertraf sie sogar — Systeme, die auf vollständigen Pixel-Annotationen beruhten. Auf einem schwierigeren Datensatz namens CRAG, der viele stark unregelmäßige, maligne Drüsen enthält, gingen die Leistungen aller Methoden zurück, doch das neue Rahmenwerk zeigte weiterhin bessere Ergebnisse als andere Schwach-Label-Konkurrenten und verringerte die Lücke zu vollüberwachten Modellen. Ablationsstudien zeigten, dass jede Komponente — selbstüberwachtes Fine-Tuning, auf Aufmerksamkeit basierendes Pseudo-Labeling mit Nachbearbeitung und randbewusster Loss — wesentlich zu den Verbesserungen beitrug.
Was das für künftige Pathologie-Werkzeuge bedeutet
Für eine allgemeine Leserschaft ist die wichtigste Erkenntnis: Diese Arbeit weist in Richtung von KI-Systemen, die hochqualitative, randpräzise Karten mikroskopischer Drüsenstrukturen liefern können, während sie sich hauptsächlich auf einfache Slide-Level-Labels stützen, die bereits in Krankenhausarchiven verbreitet sind. Indem die Abhängigkeit von mühsamer manueller Konturarbeit verringert wird, könnte der Ansatz fortschrittliche bildbasierte Einstufungen und quantitative Analysen in vielen Einrichtungen praktikabler machen, Patholog:innen helfen, kolorektalen Krebs konsistenter und effizienter zu diagnostizieren, und sich möglicherweise künftig auch auf andere Gewebetypen und Strukturen ausdehnen.
Zitation: Wen, H., Wu, Y., Huang, D. et al. Weakly supervised colorectal gland segmentation through self-supervised learning and attention-based pseudo-labeling. Sci Rep 16, 5771 (2026). https://doi.org/10.1038/s41598-026-36256-0
Schlüsselwörter: kolorektales Karzinom, digitale Pathologie, Drüsensegmentierung, schwach überwachtes Lernen, selbstüberwachtes Sehen