Clear Sky Science · de
Dialektischer Austausch als adversarieller Ansatz zur Bewertung der Robustheit arabischer NLP-Systeme
Warum Alltagssprache Arabisch intelligente Computer verwirrt
Viele Anwendungen lesen heute arabischen Text, um Stimmung zu beurteilen, Nachrichten zu sortieren oder Fragen zu beantworten. Diese Systeme lernen jedoch meist aus dem Modernen Standardarabisch (MSA), während reale Menschen im Alltag regionale Dialekte mischen. Dieser Artikel zeigt, wie der Austausch nur eines Wortes in ägyptisches oder Golfarabisch moderne Sprachmodelle täuschen kann — ein Problem für alle, die sich auf arabische KI in Kundendienst, Medienbeobachtung oder Online-Sicherheit verlassen.
Eine Sprache, viele Stimmen
Arabisch ist keine einheitliche Sprechweise. MSA wird in Schulen, Nachrichten und offiziellen Texten verwendet, aber alltägliche Gespräche stützen sich auf Dialekte wie ägyptisches oder Golfarabisch. Diese Varietäten unterscheiden sich im Wortschatz, in Wortformen und teilweise sogar in der Satzstruktur. Ein einfaches Wort wie „jetzt“ hat je nach Region sehr unterschiedliche Formen. Für menschliche Leser sind diese Varianten natürlich und leicht verständlich. Für Modelle, die fast ausschließlich auf MSA trainiert wurden, können Dialektwörter dagegen ungewohnt wirken und einen klaren Satz in etwas Rätselhaftes verwandeln.
Dialekte als Stresstest für KI
Um die Fragilität arabischer Sprachmodelle zu testen, entwirft der Autor einen einfachen zweistufigen Test. Zuerst wird ein Modell wiederholt abgefragt, um das einzelne Wort in einem Satz zu finden, das für seine Entscheidung am wichtigsten ist — oft ein starkes Adjektiv, ein Schlüsselverb oder ein thematisches Substantiv. Zweitens wird dieses eine Wort durch das entsprechende Wort des ägyptischen oder Golfarabischen ersetzt, mithilfe eines großen, sorgfältig feinabgestimmten „Dialektisierers“. Der Rest des Satzes bleibt unverändert, und die Bedeutung bleibt für menschliche Leser dieselbe. So entsteht ein realistisches adversariales Beispiel: eine kleine, natürlich wirkende Änderung, die darauf abzielt, das System zu täuschen, ohne die beabsichtigte Botschaft zu verändern.
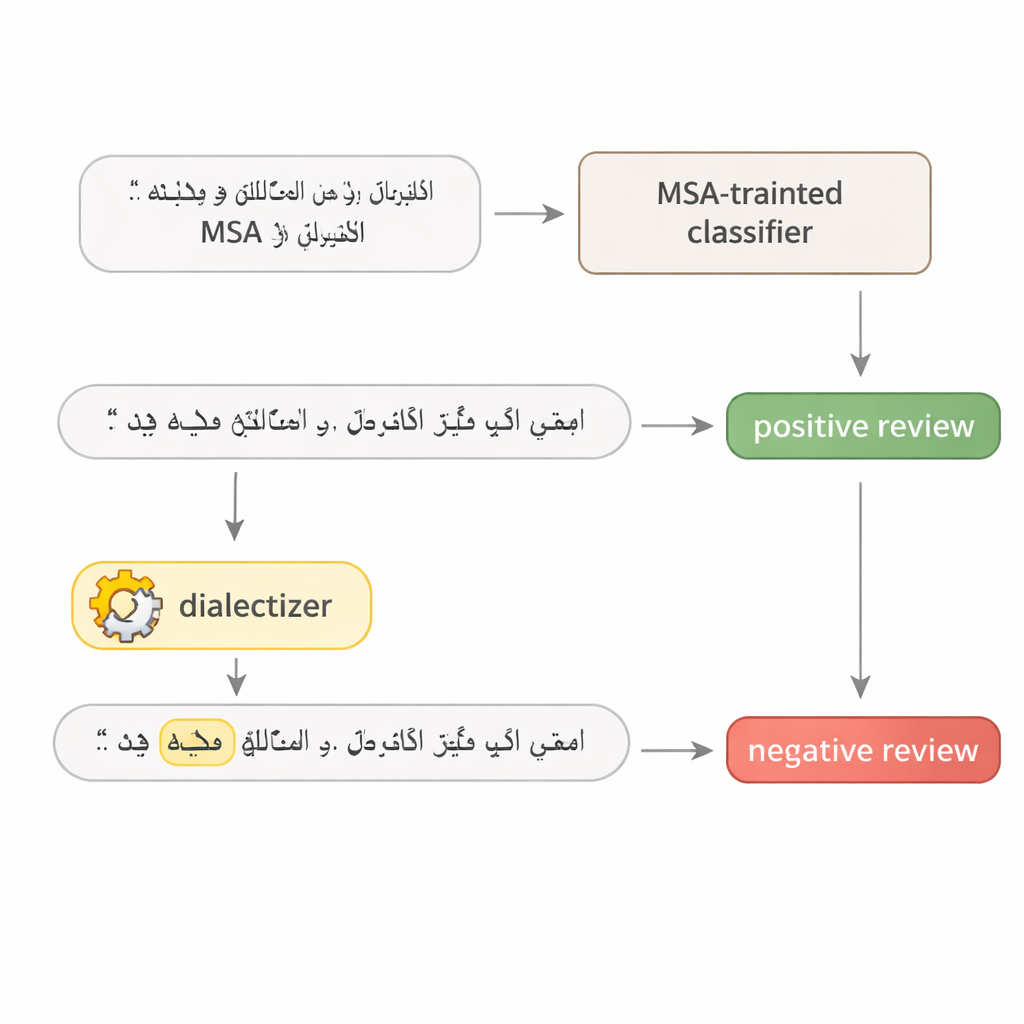
Hotelbewertungen und Nachrichten auf dem Prüfstand
Die Studie greift vier bekannte Deep-Learning-Modelle an: zwei große Transformer-Modelle (AraBERT und CAMeLBERT) und zwei kleinere Netze (ein Faltungsmodell und ein bidirektionales LSTM). Sie sind auf zwei großen MSA-Datensätzen trainiert: Hotelbewertungen für Sentiment-Analyse und Nachrichtenartikel für Themenklassifikation. Aus jedem Testset zieht der Autor 1.280 Beispiele und wendet das Verfahren der dialektalen Substitution an. Obwohl in jedem Satz nur ein Wort geändert wird, ist die Wirkung deutlich. Bei Hotelbewertungen fällt die Genauigkeit von AraBERT von 94 Prozent auf sauberem Text auf etwa 72 Prozent bei Golf-Substitutionen und 65 Prozent bei ägyptischen. CAMeLBERT sinkt noch stärker, auf rund 63 bzw. 55 Prozent. Auch Nachrichtenklassifikatoren leiden: Das Faltungsmodell verliert etwa 18 bis 22 Prozentpunkte, und das LSTM zeigt ähnliche Einbußen.
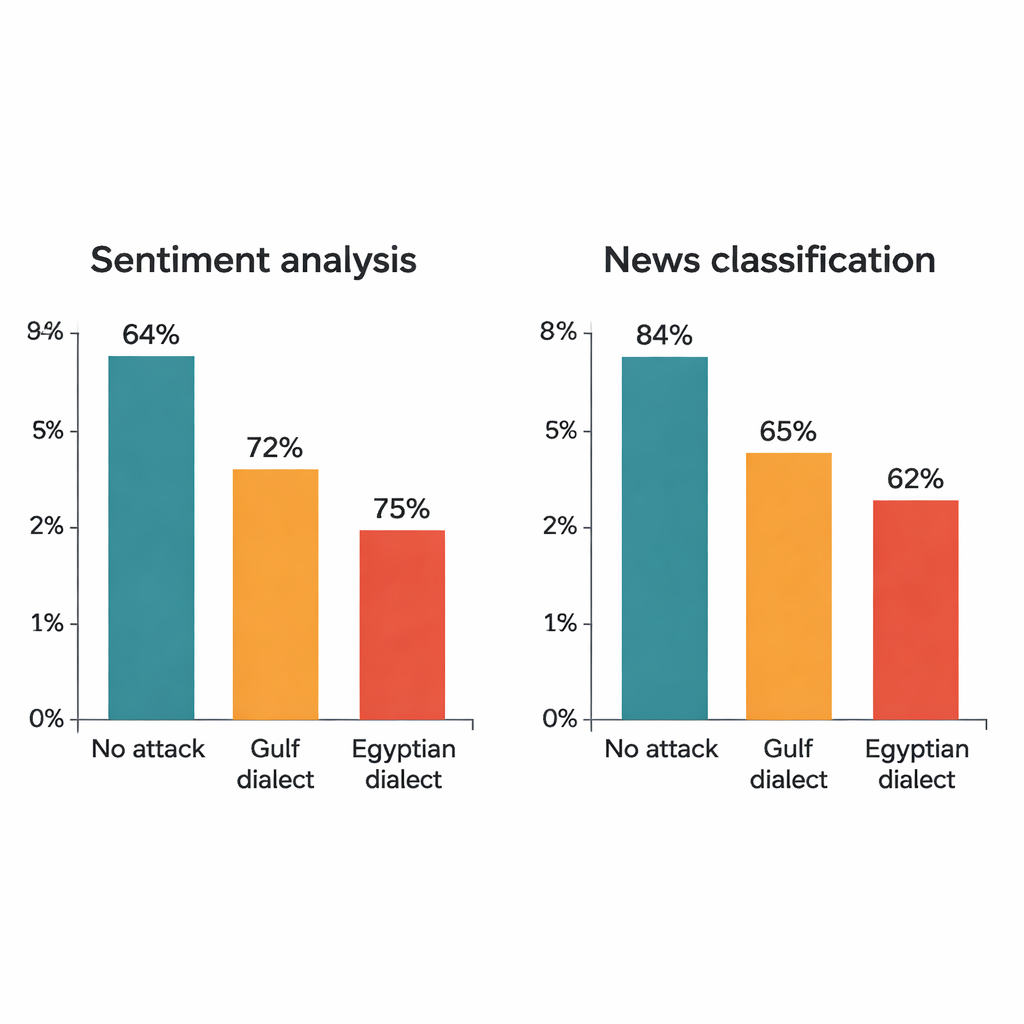
Was im Modell schiefgeht
Ein genauer Blick zeigt, dass die verwundbarsten Wörter mit der Art übereinstimmen, wie Menschen Text tatsächlich lesen. In Hotelbewertungen sind fast die Hälfte der anvisierten Wörter Adjektive wie „gut“ oder „schrecklich“, die klare emotionale Gewichtung tragen. In Nachrichtenartikeln sind die meisten ausgewählten Wörter Substantive und Namen, die Themen wie Politik, Sport oder Finanzen signalisieren. Wenn diese auslösenden Wörter in Dialektformen getauscht werden, erkennen Modelle, die nur auf MSA trainiert sind, sie oft nicht. Transformer-Modelle erweisen sich als besonders brüchig: Ihre Abhängigkeit von Subword-Fragmenten und die starke Gewichtung weniger Token macht ein einzelnes Dialektwort ausreichend, um eine Vorhersage umzustoßen. Kleinere Modelle, die die Aufmerksamkeit gleichmäßiger über einen Satz verteilen, werden zwar ebenfalls getäuscht, sind aber etwas robuster.
Ägyptisch versus Golf: Dialekte sind nicht gleich
Die Angriffe zeigen außerdem, dass ägyptisches Arabisch Modelle tendenziell stärker aus dem Konzept bringt als Golfarabisch. Sprachwissenschaftliche Untersuchungen stützen dies: Golfvarietäten bleiben oft im Wortschatz und in der Struktur näher am MSA, während das Ägyptische mehr eigenständige Formen durch historische Entwicklung und Sprachkontakt aufgenommen hat. Dadurch ähneln Golf-Substitutionen manchmal dem MSA-Original genug, dass das Modell noch klarkommt, während ägyptische Substitutionen eher außerhalb des bisher Gesehenen fallen. Statistische Tests bestätigen, dass die beobachteten Leistungseinbrüche nicht zufällig sind — sie spiegeln systematische blinde Flecken darin wider, wie aktuelle Systeme die arabische Diglossie verarbeiten.
Was das für arabische KI bedeutet
Für Alltagsnutzer ist die Erkenntnis einfach: Die heutige arabische KI lässt sich leicht durch gewöhnliche Dialektwörter verwirren, selbst wenn Menschen den Text vollkommen klar finden. Ein einzelner dialektaler Ausdruck in einer Hotelbewertung kann die Bewertung eines Modells von positiv zu negativ kippen oder das Thema einer Nachricht falsch zuordnen. Für Forschende und Entwickler bedeutet das einen Appell, „diglossie-bewusste“ Systeme zu bauen, die sowohl auf MSA als auch auf regionalen Dialekten trainieren, und realistische Stresstests wie dialektale Substitution zur Bewertung der Robustheit zu nutzen. Bis dahin läuft jede Anwendung, die annimmt, „Arabisch sei nur MSA“, Gefahr, in der Praxis gravierende Missverständnisse zu erzeugen.
Zitation: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
Schlüsselwörter: Arabische NLP, dialektale Variation, adversarielle Beispiele, Sentiment-Analyse, Textklassifikation