Clear Sky Science · de
Deep atrous context convolution generative adversarial network mit Eck‑Schlüsselpunkt‑extrahierten Merkmalen zur Klassifizierung von Nüssen
Intelligenteres Sortieren für den Alltag
Von Snackmischungen bis zu Nussaufstrichen werden jährlich Milliarden von Nüssen in Fabriken verarbeitet, und jede einzelne muss nach Typ und Qualität sortiert werden. Heute übernehmen das oft Maschinen, die jedoch Probleme haben, wenn Nüsse einander ähneln oder Fotos unter unterschiedlichen Lichtverhältnissen aufgenommen werden. Diese Studie stellt ein leistungsfähiges KI‑System namens DAC‑GAN vor, das acht gängige Nusssorten mit nahezu perfekter Genauigkeit auseinanderhalten kann und damit schnellere, günstigere und zuverlässigere Sortierung für die Lebensmittelindustrie verspricht.
Warum die Erkennung von Nüssen schwierig ist
Auf den ersten Blick lassen sich Cashew und Erdnuss leicht unterscheiden. In realen Produktionslinien können Nüsse jedoch geneigt, gebrochen, überlappend oder schlecht beleuchtet sein. Traditionelle Computerprogramme stützen sich auf einfache, von Menschen definierte Merkmale wie Farbe oder durchschnittliche Form, die bei wechselnden Bedingungen schnell versagen. Deep Learning hat die Lage verbessert, indem es Computern erlaubt, Muster direkt aus Bildern zu lernen, aber diese Methoden benötigen meist sehr große, sorgfältig ausbalancierte Datensätze. Für Nüsse sind oft nur wenige tausend gelabelte Fotos verfügbar, und manche Sorten können so ähnlich aussehen, dass es zu Fehlern und verzerrten Vorhersagen kommt.
Mehr und bessere Trainingsbilder erzeugen
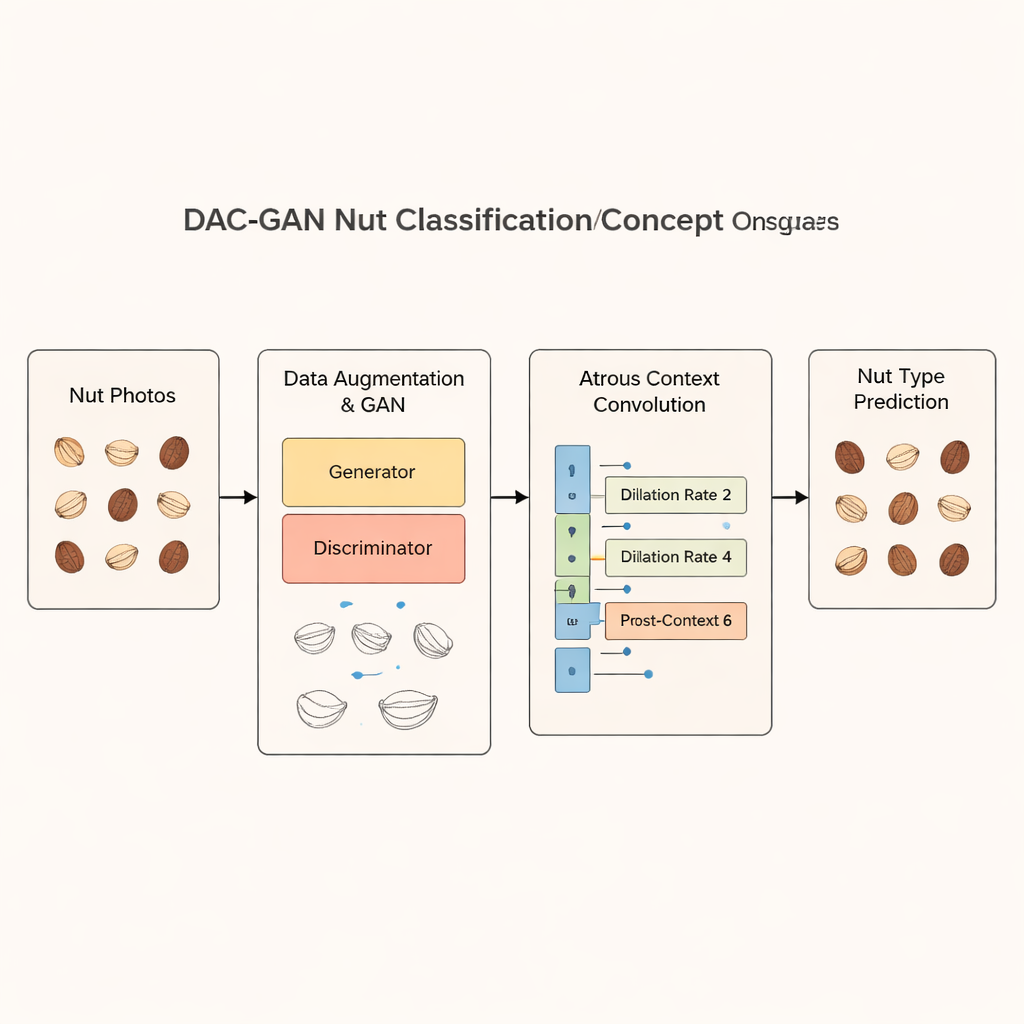
Die Forschenden beginnen mit einer öffentlichen Bildsammlung „Common Nut“, die 4.000 Fotos enthält, gleichmäßig verteilt auf acht Nusssorten: Paranuss, Cashew, Marone (Kastanie), Erdnuss, Pecan, Pistazie, Macadamia und Walnuss. Um ein robustes Modell zu trainieren, benötigen sie weit mehr Beispiele. DAC‑GAN löst das Problem mit einer speziellen Form neuronaler Netze, den generativen gegnerischen Netzen (GAN). Ein Teil des GAN, der Generator, lernt, realistische Nussbilder aus zufälligem Rauschen zu erzeugen, während der andere Teil, der Diskriminator, lernt, echte von gefälschten Bildern zu unterscheiden. Durch dieses Konkurrenzspiel wird der Generator so gut, dass er hochwertige, lebensechte synthetische Nüsse produziert. Durch die Kombination dieser künstlichen Bilder mit üblichen Spiegelungen und Rotationserweiterungen vergrößert das Team den Datensatz auf mehr als 70.000 Bilder, wobei jede Nusssorte perfekt ausbalanciert bleibt.
Dem Modell beibringen, sich auf Details der Nüsse zu konzentrieren
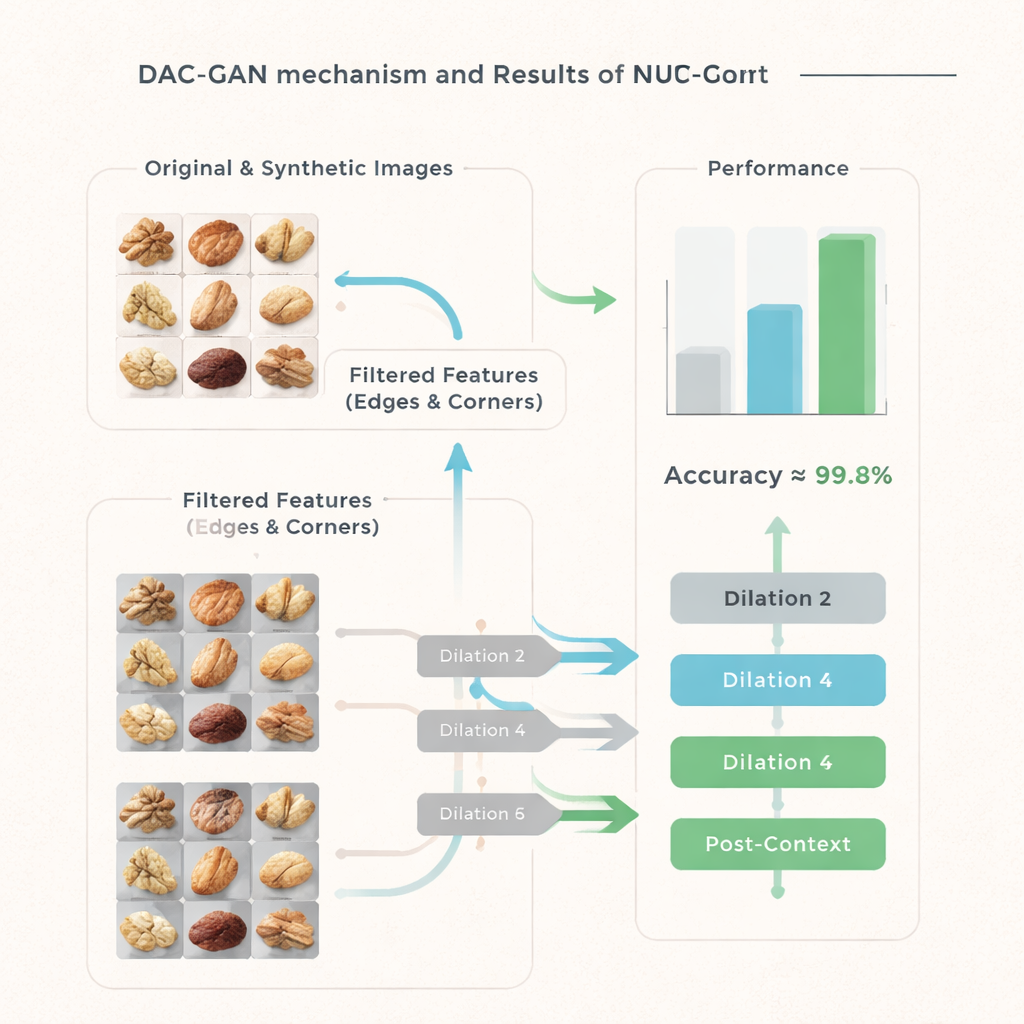
Mehr Bilder allein reichen nicht; das Modell muss sich auch auf die richtigen visuellen Hinweise konzentrieren. DAC‑GAN führt einen Filterungsschritt ein, der Nussfotos in Graustufen umwandelt und dann starke Konturen, Kanten und markante Eckpunkte extrahiert. Diese „Eck‑Schlüsselpunkt‑Merkmale“ erfassen Stellen, an denen sich die Form einer Nuss biegt oder sich die Oberflächentextur ändert — Details, die oft eine Sorte von einer anderen unterscheiden. Zusätzliche Filter heben die Gesamtumrisse des Kerns und interne Strukturen hervor. Anstatt rohe Fotos in den Klassifikator zu füttern, arbeitet das System mit diesen geschärften Feature‑Bildern, die Geometrie und Textur betonen und ablenkende Hintergrund‑ und Farbvariationen zurückdrängen.
Die ganze Nuss auf mehreren Skalen sehen
Im Zentrum von DAC‑GAN steht eine verfeinerte Version einer Technik namens atrous‑ bzw. dilatierte Faltung. Gewöhnliche Faltungsschichten in tiefen Netzen betrachten jeweils nur kleine Bereiche. Atrous‑Faltung verteilt die Abtastpunkte weiter, sodass das Modell einen breiteren Blick erhält, ohne Auflösung zu verlieren. Die Autoren fügen um diese Kernoperation „Pre‑Context“‑ und „Post‑Context“‑Blöcke hinzu, die das gesamte Bild zusammenfassen und diese Zusammenfassung wieder in die Schicht einspeisen. Indem sie drei solcher Faltungen mit unterschiedlichen Dilatationsraten ausführen, lernt das Netzwerk, sowohl winzige Rillen auf der Nussoberfläche als auch die Gesamtkontur zu erfassen und diese Ansichten zu einer reichhaltigen, kontextbewussten Repräsentation zu kombinieren, bevor es eine Entscheidung trifft.
Wie gut funktioniert es?
Das Team unterzieht DAC‑GAN einer umfangreichen Reihe von Tests. Sie vergleichen es mit vielen bekannten neuronalen Netzen, von klassischen Modellen wie VGG und ResNet bis zu neueren, auf Transformern basierenden Entwürfen, jeweils mit und ohne synthetische Daten. Über Genauigkeit, Präzision, Recall und den kombinierten F1‑Score hinweg übertrifft DAC‑GAN durchgängig alle Alternativen deutlich. Auf dem zurückgehaltenen Testset realer Nussbilder identifiziert es die Nusssorte in 99,83 % der Fälle korrekt, mit nur 25 Fehlern bei 800 Proben. Selbst die konkurrenzfähigsten Rivalen liegen mehrere Prozentpunkte zurück, und detaillierte Statistiken zeigen, dass der Vorteil von DAC‑GAN nicht zufällig, sondern statistisch sehr robust ist.
Was das für Lebensmittel und darüber hinaus bedeutet
Für Nicht‑Spezialisten ist die Botschaft einfach: Indem man geschickt zusätzliche Trainingsbilder erzeugt und dem Netzwerk beibringt, auf Kanten, Ecken und kontextuelle Mehrskaleninformationen zu achten, verwandelt DAC‑GAN ein visuell feines Problem in eines, das es nahezu perfekt lösen kann. Praktisch könnte dieser Ansatz zu automatisierten Nuss‑Sortiermaschinen führen, die große Mengen mit sehr wenigen Fehlern verarbeiten, die Qualitätskontrolle verbessern und die manuelle Arbeit reduzieren. Da die Methode allgemein anwendbar ist, ließe sie sich auch auf andere Lebensmittelprodukte — oder sogar auf industrielle Bauteile — übertragen, die anhand feiner visueller Details unter unvollkommenen Aufnahmebedingungen unterschieden werden müssen.
Zitation: Devi, M.S., Jaiganesh, M., Priya, S. et al. Deep atrous context convolution generative adversarial network with corner key point extracted feature for nuts classification. Sci Rep 16, 6409 (2026). https://doi.org/10.1038/s41598-026-36238-2
Schlüsselwörter: Nussklassifizierung, Tiefes Lernen, Bildaugmentation, Lebensmittelklassifizierung, Computer Vision