Clear Sky Science · de
Langreichweiten-Kontextmodellierung zur Erkennung von Software-Schwachstellen mit einem XLNet-basierten Ansatz
Warum versteckte Softwarefehler wichtig sind
Das moderne Leben basiert auf Software – von Online-Banking und Krankenhaus-IT bis hin zu Videoplayern und Chat-Apps. Schon winzige Fehler im Programmcode können jedoch Angreifern Tür und Tor öffnen und Datendiebstahl oder Ausfälle verursachen. Sicherheitsexperten greifen zunehmend auf künstliche Intelligenz zurück, um Millionen von Codezeilen nach solchen Schwachstellen zu durchforsten. Dieser Beitrag untersucht eine neue KI-basierte Methode, XLNetVD genannt, die darauf ausgelegt ist, subtile Software-Schwachstellen zu erkennen, indem sie deutlich größere Codeabschnitte liest als viele bestehende Werkzeuge.
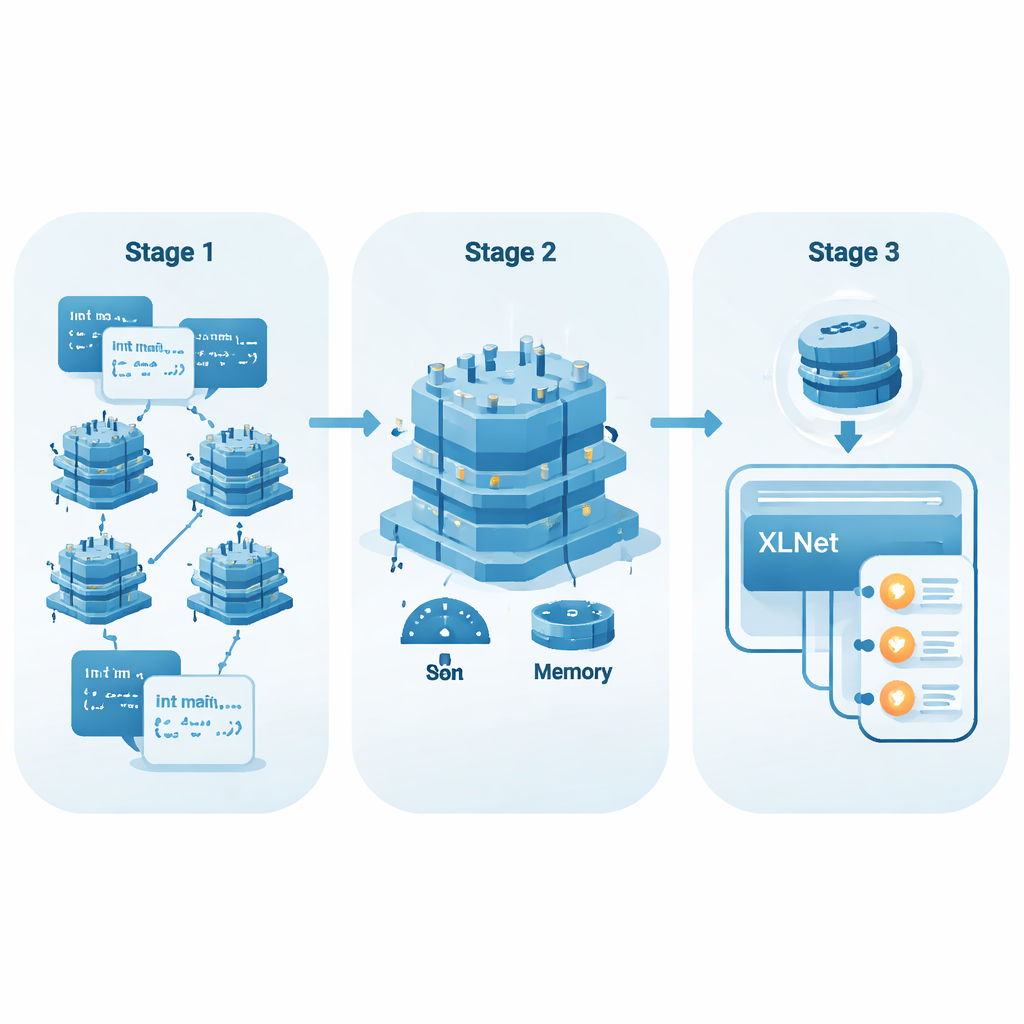
Von einfachen Wortlisten zu Code, der Kontext versteht
Frühe KI-Methoden zur Code-Analyse behandelten jedes Token – etwa einen Variablennamen oder ein Symbol – fast wie ein Wörterbuchwort mit fester Bedeutung. Techniken wie Word2Vec oder GloVe lernten einen Vektor pro Token, unabhängig davon, wo es erschien. Das funktioniert für natürliche Sprache einigermaßen, greift aber bei Programmen zu kurz, weil derselbe Variablenname je nach Kontext sehr unterschiedlich wirken kann. Neuere Modelle, sogenannte kontextuelle Einbettungsmodelle, betrachten stattdessen die gesamte Funktion gleichzeitig und passen die Darstellung jedes Tokens an seine Umgebung an. So erkennen sie Muster im Datenfluss, Kontrollfluss und in Abhängigkeiten zwischen Variablen – Muster, die oft über sicheren oder unsicheren Code entscheiden.
Der KI erlauben, mehr der Datei zu lesen
Beliebte Codemodelle wie CodeBERT und GraphCodeBERT verwenden bereits diesen kontextbewussten Ansatz, beschränken ihre „Sicht“ jedoch typischerweise auf etwa 512 Tokens. Bei langen Funktionen oder bei Schwachstellen, die in weit auseinanderliegenden Teilen des Codes angedeutet werden, kann dieses Fenster zu kurz sein. Wichtige Prüfungen am Anfang einer Funktion können so von riskanten Operationen am Ende abgeschnitten sein. Die Autoren setzen stattdessen auf XLNet, ein Modell auf Basis von Transformer-XL, das Informationen über Segmente hinweg behalten kann und längere Sequenzen komfortabel verarbeitet (in ihren Experimenten bis zu 768 Tokens). Dadurch eignet es sich besser, entfernte Ereignisse im Code zu verknüpfen – etwa zu erkennen, dass ein Wert zuvor validiert wurde oder eben nicht.
Leistungsstarke Modelle leichter und schneller machen
Große KI-Modelle benötigen oft leistungsstarke Hardware, was ihren Einsatz in alltäglichen Entwicklungsumgebungen einschränkt. Um dem zu begegnen, wenden die Autoren ein Fine-Tuning-Verfahren namens Low-Rank Adaptation (LoRA) an. Anstatt alle vielen Parameter von XLNet zu ändern, fügt LoRA kleine Adapter-Schichten hinzu, die viel weniger Kosten beim Trainieren und Speichern verursachen. Das Team führt eine einfache Kennzahl ein, EffScore, die abwägt, wie viel Speicher und Zeit eingespart werden gegenüber einem möglichen Qualitätsverlust bei der Erkennung. Über mehrere führende Modelle hinweg erweist sich XLNet mit LoRA als insgesamt am effizientesten: es bietet starke Genauigkeit bei deutlich geringerem Ressourcenbedarf.
Tests an realen und synthetischen Projekten
Die Forschenden bewerten XLNetVD an zwei sehr unterschiedlichen Datensätzen. Der eine besteht aus echtem C-Code aus 12 Open-Source-Projekten – etwa Mediatheken und Webservern – mit einem stark verzerrten Verhältnis von etwa 1 verwundbarer Funktion zu 65 nicht verwundbaren, wie es in großen Codebasen üblich ist. Der andere ist eine ausgeglichene, synthetische Sammlung aus dem SARD-Projekt, bei der jede Funktion so gestaltet ist, dass sie einen bekannten Schwachstellentyp repräsentiert. XLNetVD erreicht bei diesen Tests nicht nur frühere Deep-Learning-Systeme und klassische statische Analysewerkzeuge, es schneidet auch in Cross-Project-Szenarien gut ab, in denen es Schwachstellen in einem zuvor unbekannten Projekt finden muss. Sein Vorteil ist besonders stark bei langen Funktionen, bei denen längerer Kontext entscheidend ist, und über eine Reihe von Schwachstellenkategorien hinweg, darunter Integer-Überläufe, fehlerhafte Ressourcenverwaltung und unsachgemäße Eingabebehandlung.
Was das für alltägliche Software-Sicherheit bedeutet
Für Nicht-Spezialisten lautet die Kernbotschaft: Kontextbewusste, intelligentere KI kann Code mehr wie ein erfahrener menschlicher Prüfer lesen und bewerten – aber in Maschinengeschwindigkeit. Indem das Modell mehr von jeder Funktion sieht und effizient feinabgestimmt wird, bietet XLNetVD eine praktische Möglichkeit, Prioritäten zu setzen, welche Teile einer riesigen Codebasis eine genauere menschliche Prüfung verdienen. Es ersetzt keine manuellen Sicherheitsüberprüfungen oder formale Methoden und kann nicht garantieren, dass Software fehlerfrei ist. Allerdings erhöht es deutlich die Chancen, gefährliche Fehler früh zu entdecken, selbst in unbekannten Projekten, und stellt damit einen vielversprechenden Baustein für zuverlässigere und sicherere digitale Infrastrukturen dar.
Zitation: Zhao, Y., Lin, G. & Liao, Z. Long-range context modeling for software vulnerability detection using an XLNet-based approach. Sci Rep 16, 5338 (2026). https://doi.org/10.1038/s41598-026-36196-9
Schlüsselwörter: Software-Schwachstellen, Code-Sicherheit, Deep Learning, XLNet, LoRA-Fine-Tuning