Clear Sky Science · de
Modifizierter priorisierter DDPG-Algorithmus zur gemeinsamen Beamforming- und RIS-Phasenoptimierung in MISO-Downlink-Systemen
Intelligente Oberflächen für die nächste Welle der drahtlosen Kommunikation
Während unsere Telefone, Autos und Sensoren immer schnellere und verlässlichere Verbindungen verlangen, werden heutige Funknetze an ihre Grenzen gebracht. Diese Studie untersucht einen neuen Ansatz, um künftige 6G-Netze sowohl ökologischer als auch zuverlässiger zu machen, indem „intelligente“ reflektierende Oberflächen an Gebäuden mit einer künstlichen Intelligenz kombiniert werden, die eigenständig lernt, Funksignale mit geringerem Energieaufwand zu lenken.
Wände, die zu nützlichen Signalspiegeln werden
Zukünftige 6G-Systeme müssen eine große Anzahl von Geräten mit hohen Datenraten, hoher Zuverlässigkeit und sehr geringer Latenz bedienen. All diese Anforderungen allein mit herkömmlichen Basisstationen zu erfüllen, würde viel zusätzliche Hardware und Energie erfordern. Rekonfigurierbare intelligente Oberflächen (RIS) bieten einen anderen Ansatz: Paneele, die mit vielen winzigen, energiearmen Elementen beschichtet sind und eintreffende Funkwellen in kontrollierte Richtungen reflektieren können – wie ein programmierbarer Spiegel. Durch die sorgfältige Wahl der Phasen dieser Reflexionen kann ein RIS Signale um Hindernisse herumlenken, schwache Verbindungen verstärken und Interferenzen reduzieren, ganz ohne selbst aktiv zu senden. Das gibt Netzplanern ein mächtiges neues Steuerungselement, um Abdeckung zu erweitern und Effizienz zu verbessern.
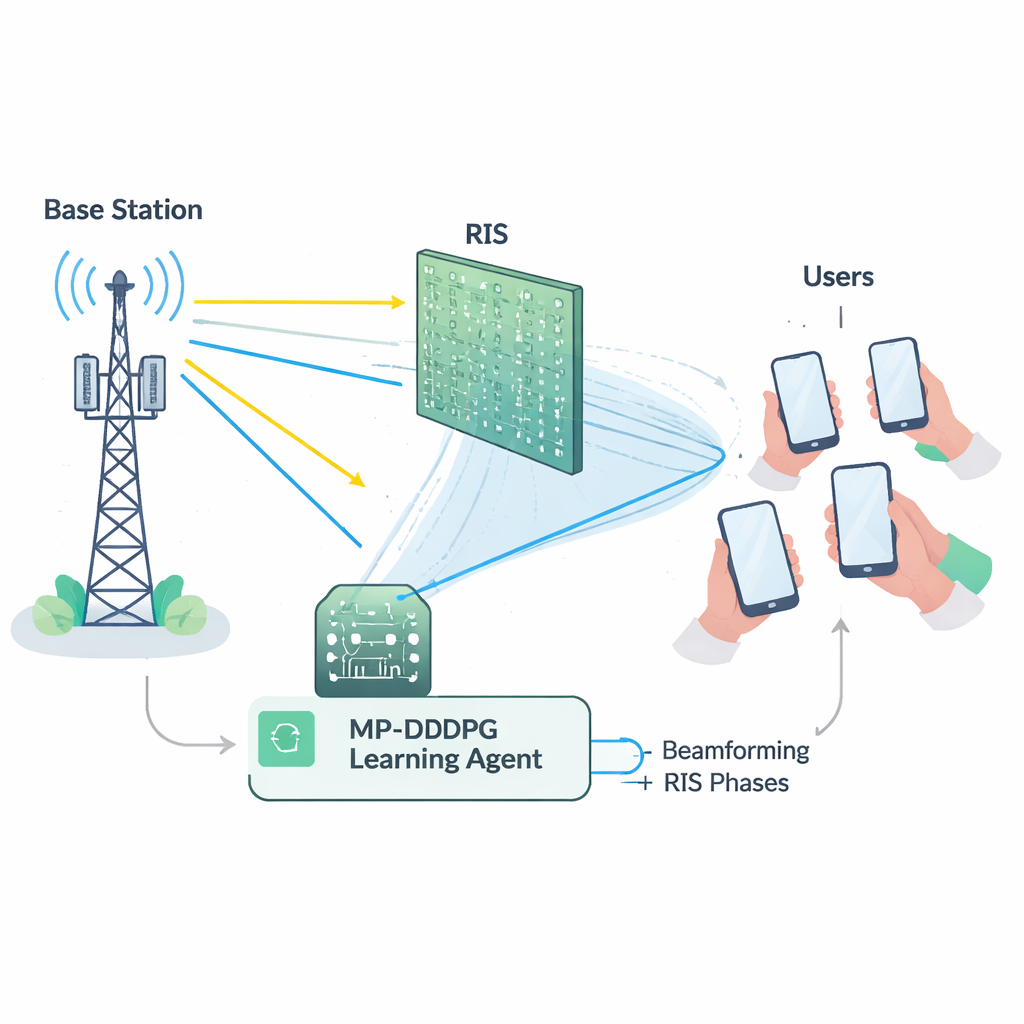
Ein schwieriger Balanceakt für das Netz
Die sinnvolle Nutzung eines RIS ist nicht trivial. Die Basisstation muss entscheiden, wie sie ihre Antennen ausrichtet (Beamforming), während das RIS die Phase jedes seiner vielen Reflektionselemente einstellen muss. Diese Entscheidungen sind eng miteinander verknüpft und müssen gleichzeitig mehrere Vorgaben erfüllen: die Gesamtübertragungsleistung unter einem Maximum halten, jedem Nutzer eine Mindestqualität sichern und physikalische Grenzen der RIS-Hardware respektieren. Mathematisch ist dieses gemeinsame Abstimmungsproblem stark nichtlinear und „nicht-konvex“, was bedeutet, dass herkömmliche Optimierungswerkzeuge oft langsam, anfällig oder in suboptimalen Lösungen gefangen sind, insbesondere bei größeren Netzwerken. Außerdem ist das genaue Messen des Zustands jeder Funkverbindung (die sogenannte Kanalzustandsinformation) selbst kostspielig und fehleranfällig in realen Einsätzen.
Ein KI-Agent lernt, wie man beamt
Um diese Hürden zu überwinden, entwickeln die Autoren einen Lernagenten auf Basis von Deep Reinforcement Learning, einem Bereich der KI, in dem ein Agent durch Versuch und Irrtum mit einer Umgebung gute Strategien entdeckt. Ihre Methode, genannt Modifizierter Priorisierter Deep Deterministic Policy Gradient (MP-DDPG), beobachtet den aktuellen Netzstatus – frühere Beam-Richtungen, RIS-Einstellungen, empfangene Leistung und Signalqualität – und wählt dann neue Beamforming- und RIS-Phasenwerte. Nach jeder Entscheidung erhält der Agent eine Belohnung, die drei Ziele zugleich fördert: geringere Sendeleistung, Einhaltung der Qualitätsanforderungen der Nutzer und Beachtung der Leistungsgrenze der Basisstation. Über viele simulierte Interaktionen lernt der Agent schrittweise eine Steuerungsstrategie, die diese Ziele ausbalanciert, ohne dass ihm eine explizite Formel für den Funkkanal vorgegeben wird.
Schneller lernen, indem man sich auf das Wesentliche konzentriert
Die Schlüsselinnovation liegt darin, wie der Algorithmus aus seinen bisherigen Erfahrungen lernt. Standardansätze speichern viele vergangene Situationen und sampeln sie zufällig während des Trainings, was verschwenderisch und langsam sein kann. MP-DDPG weist stattdessen jeder gespeicherten Erfahrung eine Priorität zu, die sowohl von ihrer Belohnung als auch davon abhängt, wie unterschiedlich ihr Zustand im Vergleich zu ihren nächsten Nachbarn ist. Erfahrungen, die sowohl informativ als auch vielfältig sind, werden häufiger ausgewählt, während redundante ignoriert werden. Dieses „modifizierte priorisierte Replay“ macht jeden Lernschritt nützlicher, beschleunigt die Konvergenz und hilft dem Agenten, schlechte lokale Lösungen zu vermeiden. Die Autoren analysieren zudem den zusätzlichen Rechenaufwand und zeigen, dass – obwohl die Verwaltung komplexer ist als bei der Grundmethode – das schnellere Lernen dies in der Praxis mehr als ausgleicht.
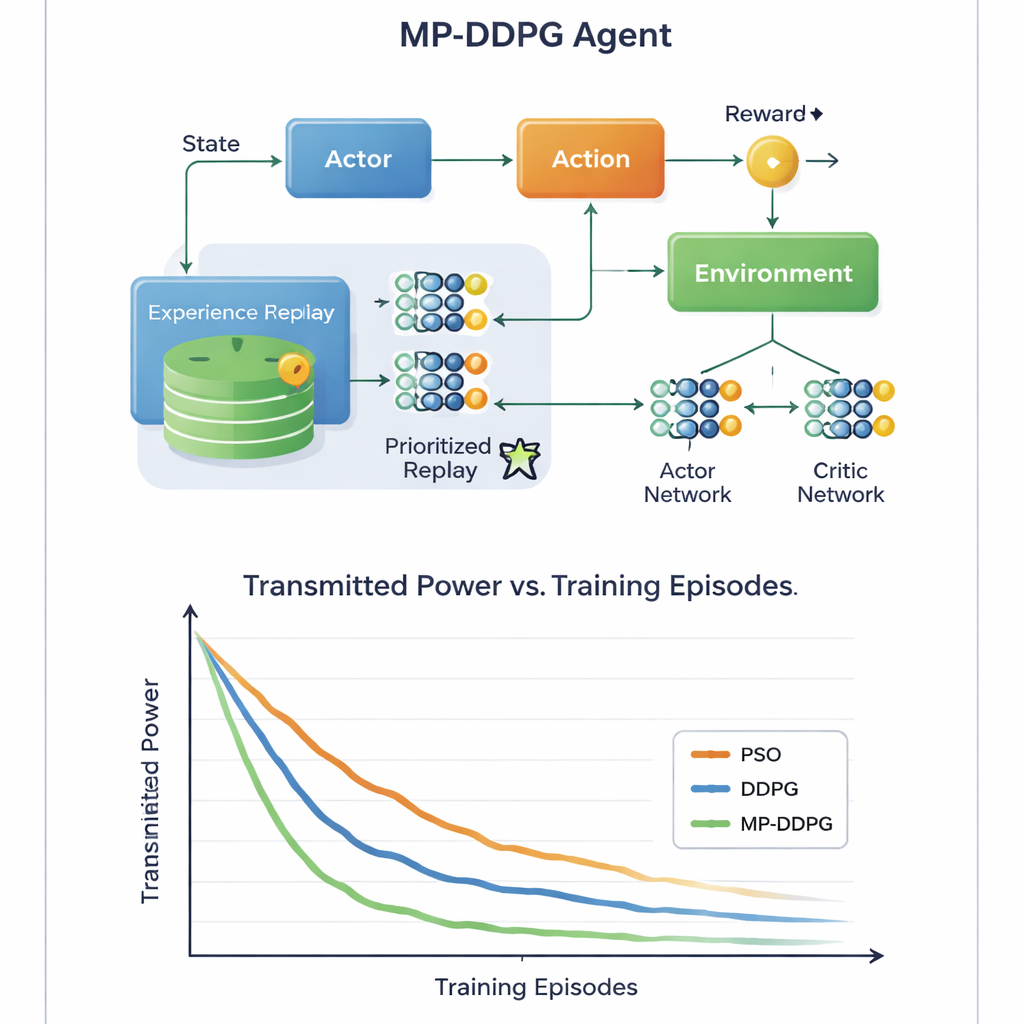
Grünere Signale mit weniger Hardware
Durch detaillierte Computersimulationen eines Downlink-Zell-Szenarios vergleicht die Studie MP-DDPG mit zwei Alternativen: einer traditionellen Particle-Swarm-Optimierung und dem ursprünglichen DDPG-Lernalgorithmus. Die neue Methode erreicht konstant niedrigere Sendeleistungen in weniger Trainingsdurchläufen und tut dies mit weniger RIS-Elementen und weniger Basisstationsantennen bei gleichem Leistungsniveau. Einfach ausgedrückt, das Netz lernt, mehr Nutzen aus jeder Reflektionsfläche und jeder Antenne zu ziehen. Für Nichtfachleute lautet die Botschaft: Indem ein KI-Controller sowohl die Strahlen der Basisstation als auch die intelligenten Oberflächen an benachbarten Wänden gezielt abstimmt, könnten künftige 6G-Netze starke, zuverlässige Signale mit weniger Energie und weniger Hardware bereitstellen und so unsere zunehmend vernetzte Welt nachhaltiger machen.
Zitation: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Schlüsselwörter: rekonfigurierbare intelligente Oberfläche, 6G Funk, tiefes verstärkendes Lernen, Beamforming-Optimierung, energieeffiziente Netze