Clear Sky Science · de
Maschinelles Lernen zur Vorhersage von Nahrungsmittelabhängigkeit bei Studierenden anhand demografischer, anthropometrischer und Persönlichkeitsmerkmale
Warum unser Verhältnis zu Lebensmitteln sich außer Kontrolle anfühlen kann
Viele Leute machen Witze darüber, sie seien „süchtig“ nach Schokolade oder Fast Food, aber für manche sind Verlangen und Kontrollverlust beim Essen ernst und belastend. Besonders verletzlich sind Studierende, die mit Stress, neuen Freiheiten und körperlichen Veränderungen jonglieren. Diese Studie stellt eine aktuelle Frage: Können Computerprogramme lernen, welche Studierenden ein höheres Risiko für Nahrungsmittelabhängigkeit haben, anhand einfacher Informationen über Hintergrund, Körpermaße und Persönlichkeit? Wenn ja, könnten wir Probleme früher erkennen und gezielte Unterstützung anbieten, bevor Essgewohnheiten in langfristige Gesundheitsprobleme ausarten.
Studierende aus vielen Perspektiven betrachten
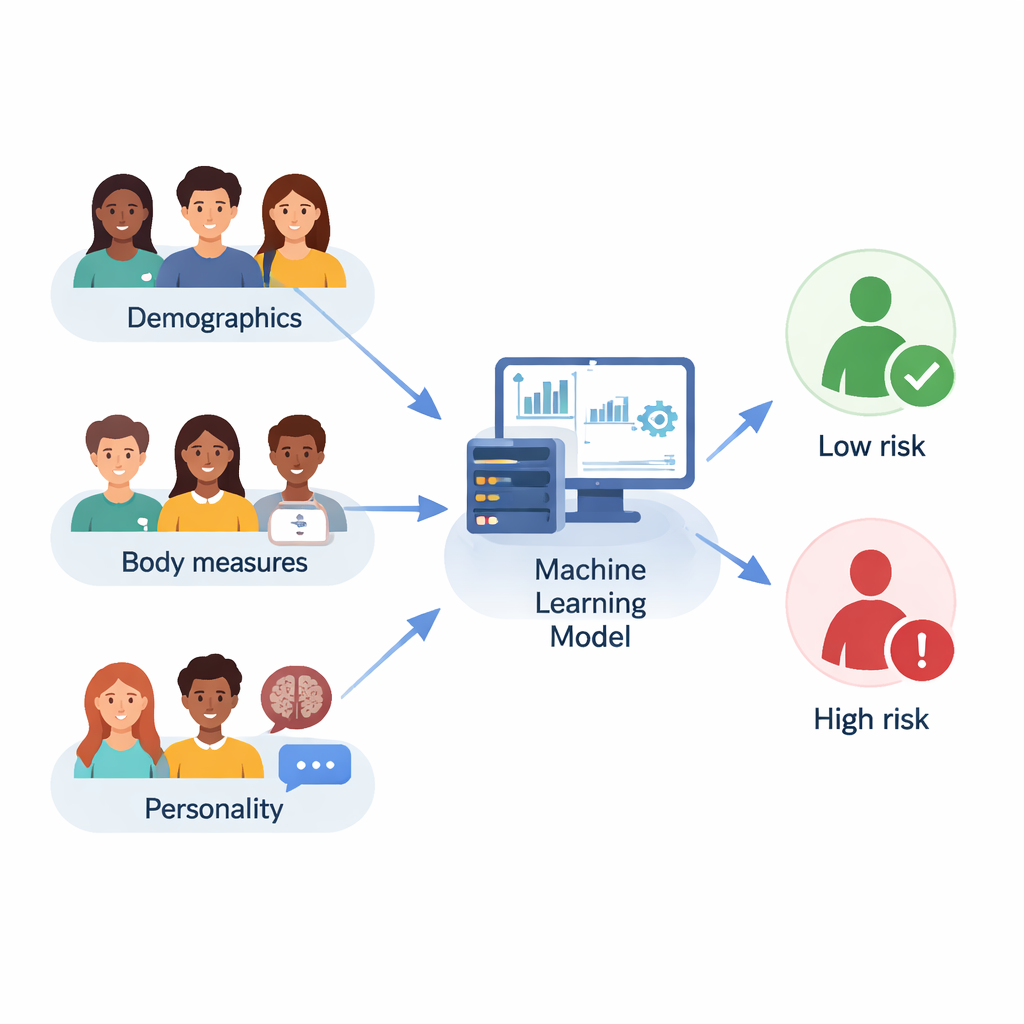
Die Forschenden arbeiteten mit 210 Studierenden in Ahvaz, Iran, im Alter von 18 bis 35 Jahren. Jede Person gab grundlegende Angaben wie Alter und Bildungsstand an, berichtete Größe und Gewicht, so dass der Body‑Mass‑Index (BMI) berechnet werden konnte, und füllte einen standardisierten Persönlichkeitsfragebogen aus. Außerdem wurde eine kurze Version der Yale Food Addiction Scale eingesetzt, die einstuft, ob jemand suchtähnliche Muster gegenüber stark appetitlichen Lebensmitteln zeigt, etwa intensives Verlangen, vergebliche Versuche, den Konsum zu reduzieren, oder Essen trotz negativer Konsequenzen. Nur 30 Studierende erfüllten die Kriterien für Nahrungsmittelabhängigkeit, während 180 dies nicht taten, was widerspiegelt, dass solche Probleme nur einen kleineren Teil der Bevölkerung betreffen.
Ungleiche Daten ausgleichen und Maschinen klug trainieren
Da deutlich weniger Studierende als nahrungsmittelabhängig eingestuft wurden, war der Datensatz unausgewogen. Diese Imbalance kann Computer‑Modelle dazu verleiten, überwiegend die Mehrheitsgruppe vorherzusagen und die Hochrisikogruppe zu übersehen. Um dem entgegenzuwirken, nutzte das Team zwei Datenverarbeitungsstrategien. Zuerst wendeten sie eine Methode namens Tomek Links an, um verwirrende Fälle der Mehrheitsgruppe zu entfernen, die den Minderheitsfällen zu ähnlich waren. Anschließend verwendeten sie SMOTE, das realistische synthetische Beispiele der Minderheitsgruppe erzeugt, um die Zahlen auszugleichen. Verändert wurden nur die Trainingsdaten; eine separate, unangetastete Testgruppe wurde zurückgehalten, um zu prüfen, wie gut die Modelle an neuen, unbekannten Studierenden funktionieren.
Viele Algorithmen gegeneinander antreten lassen
Die Forschenden verließen sich nicht auf ein einzelnes mathematisches Rezept. Stattdessen verglichen sie zehn verschiedene Machine‑Learning‑Modelle, von einfachen Verfahren wie logistischer Regression und k‑nearest neighbors bis zu fortgeschrittenen Ensemble‑Methoden wie Random Forest, Gradient Boosting, LightGBM und CatBoost. Zudem testeten sie zwölf Feature‑Selection‑Strategien, um zu entscheiden, welche Fragen und Messwerte am aussagekräftigsten waren, und nutzten Cross‑Validation sowie automatische Suchverfahren, um die Einstellungen jedes Modells zu optimieren. Die Gesamtleistung wurde anhand mehrerer Kennzahlen bewertet, darunter Genauigkeit (wie oft das Modell richtig lag), F1‑Score (ein Ausgleich zwischen dem Erfassen echter Fälle und der Vermeidung zu vieler Fehlalarme) und die Fläche unter der ROC‑Kurve, die erfasst, wie gut ein Modell höher‑ und niedrigrisiko‑Personen trennt.
Was die Vorhersagen im Inneren antreibt
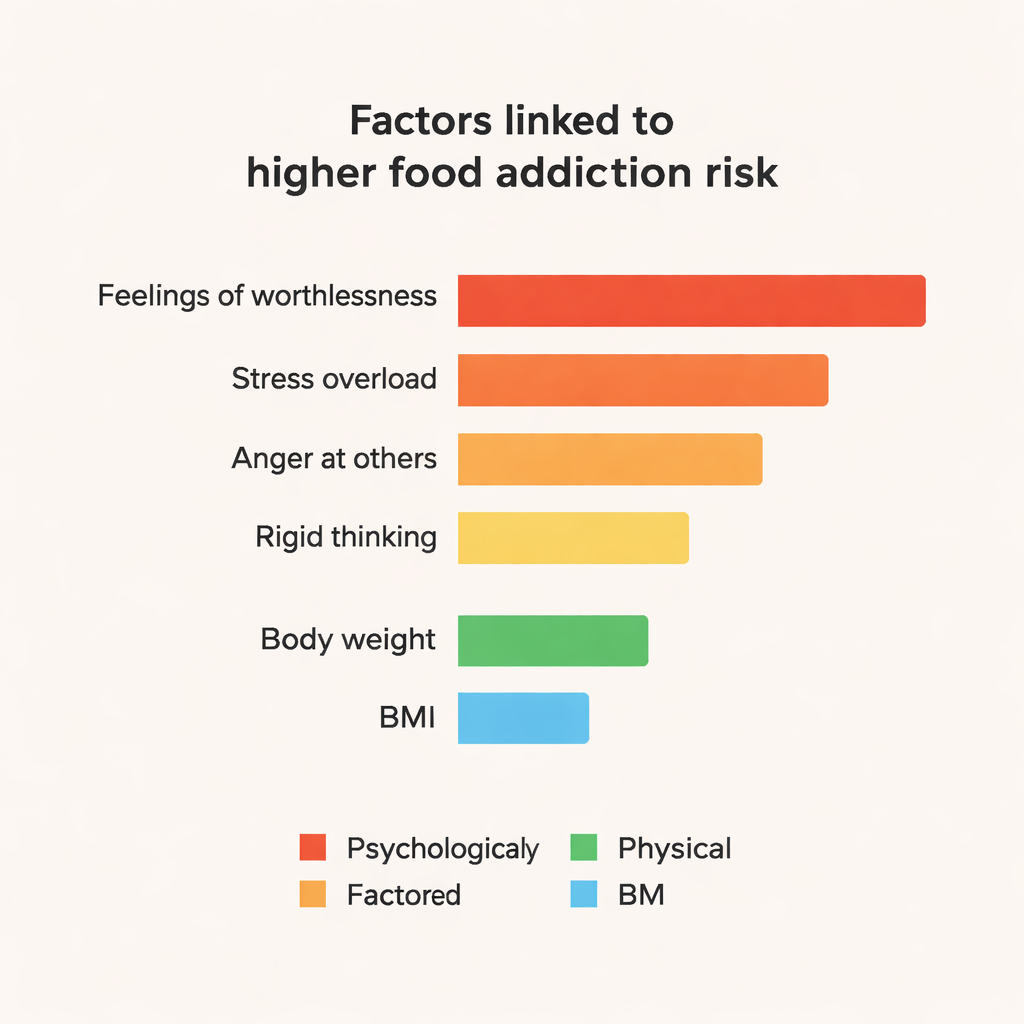
Ensemble‑Modelle, insbesondere CatBoost und Random Forest, übertrafen durchgehend einfachere Ansätze und erreichten in diesem kleinen Datensatz etwa 84 % Genauigkeit und F1‑Werte von rund 0,84. Um über „Black‑Box“-Vorhersagen hinauszukommen, nutzte das Team ein Werkzeug namens SHAP, um zu untersuchen, welche Merkmale das Modell dazu veranlassen, jemanden als nahrungsmittelabhängig zu klassifizieren. Die auffälligsten Einflüsse waren psychologischer Natur: starke Aussagen wie „Manchmal fühle ich mich vollkommen wertlos“, das Gefühl, unter Stress „auseinanderzufallen“, häufige Wut über das Verhalten anderer, emotionale Anspannung und starres, unflexibles Denken. Körpergewicht und BMI spielten ebenfalls eine Rolle, waren aber weniger zentral als diese emotionalen und persönlichkeitsbezogenen Signale. Merkmale, die mit positiver Stimmung und guter Organisation verbunden sind, zeigten einen leicht schützenden Effekt.
Was das für den Alltag bedeutet
Für die Leserschaft lautet die Kernbotschaft, dass Nahrungsmittelabhängigkeit nicht einfach eine Frage der Willenskraft oder des Gefallens an leckeren Snacks ist. In dieser Pilotgruppe von Studierenden waren tiefere emotionale Belastungen – geringes Selbstwertgefühl, Schwierigkeiten im Umgang mit Stress und belastete Beziehungen – eng mit problematischem Essen verknüpft. Frühe Versionen von Machine‑Learning‑Tools, gespeist mit einfachen Fragebögen und Körpermaßen, konnten diese Muster mit ermutigender Genauigkeit erkennen. Die Autorinnen und Autoren betonen jedoch, dass ihre Stichprobe klein, auf Selbstangaben basierend und von einer einzelnen Universität stammend war, sodass die Ergebnisse vorläufig sind. Mit größeren und vielfältigeren Studien könnten ähnliche Modelle schließlich zusammen mit standardisierten klinischen Beurteilungen eingesetzt werden, um junge Menschen zu identifizieren, die von Unterstützung beim Umgang mit ihren Emotionen und Essgewohnheiten profitieren würden.
Zitation: Rahimnezhad, A., Mortazavi, S.T., Behdarvand, Y. et al. Machine learning prediction of food addiction in university students using demographic, anthropometric and personality traits. Sci Rep 16, 6745 (2026). https://doi.org/10.1038/s41598-026-36162-5
Schlüsselwörter: Nahrungsmittelabhängigkeit, Studierende, Persönlichkeitsmerkmale, maschinelles Lernen, emotionales Essen