Clear Sky Science · de
Integration von Optimierung und Machine Learning zur Schätzung der Wasserwiderstandsfähigkeit und Sättigung in shaley Sandlagerstätten
Warum das für Energie und Umwelt wichtig ist
Öl‑ und Gasunternehmen verlassen sich auf Messungen aus dem Bohrloch, um zu entscheiden, wo sich Kohlenwasserstoffe verbergen und ob ein Feld eine wirtschaftliche Erschließung wert ist. In vielen Lagerstätten, insbesondere solchen mit hohem Ton‑ und Schluffgehalt, sind diese Messungen schwer zu interpretieren, sodass Ingenieure das vorhandene Öl oder Gas oft unterschätzen. Diese Studie stellt eine neue Methode vor, um vertrauenswürdigere Informationen aus vorhandenen Daten zu gewinnen, indem physikbasierte Optimierung mit modernem Machine Learning kombiniert wird. Das kann die Wiedergewinnung verbessern und zugleich den Bedarf an teuren Kernproben reduzieren.
Das Problem mit schlammigen Gesteinen
Viele der weltweiten Kohlenwasserstofflagerstätten sind „shaley sands“ – Gemenge aus Sandkörnern, Porenflüssigkeiten und elektrisch leitfähigen Tonmineralen. Diese Tone verfälschen die elektrischen Messungen, die zur Abschätzung des Verhältnisses von Wasser zu Kohlenwasserstoffen im Porenraum dienen. Klassische Werkzeuge und Diagramme, entwickelt für sauberere Sande, setzen einfache Gesteinsstrukturen und geringen Tonanteil voraus. In shaley sands versagen diese Annahmen oft, sodass die Gesteine nasser erscheinen, als sie sind, und Ingenieure Abschnitte verwerfen, die tatsächlich signifikante Öl‑ oder Gasvorkommen enthalten können.
Aus spärlichen Messungen einen belastbaren Bezugspunkt schaffen
Die Autoren widmen sich einer zentralen Größe, der Formationswasserwiderstandsfähigkeit (formation water resistivity), die beschreibt, wie gut das Wasser in den Poren elektrischen Strom leitet. Liegt dieser Wert falsch, sind alle nachfolgenden Wassersättigungs‑Schätzungen verzerrt. Anstatt sich auf wenige Laborwerte oder subjektive grafische Methoden zu stützen, formulieren sie das Problem als Optimierungsaufgabe: Finde den einzelnen Wert der Wasserwiderstandsfähigkeit, der ein physikbasiertes Shaley‑Sand‑Modell am besten mit den im Bohrloch gemessenen Widerstandswerten in Einklang bringt. Sie testen mehrere Suchalgorithmen und zeigen, dass einfache, ableitungsfreie Verfahren wie Powell und Nelder–Mead die wahre Wasserwiderstandsfähigkeit mit sehr geringer Abweichung rekonstruieren können, verglichen mit Kern‑ und Wasserproben aus 11 Bohrungen in der norwegischen Nordsee und der westlichen Wüste Ägyptens.
Erzeugung eines „Pseudo‑Kern“-Protokolls für Machine Learning
Wenn dieser optimierte Wert für die Wasserwiderstandsfähigkeit vorliegt, wird dasselbe physikalische Modell verwendet, um ein kontinuierliches Profil der Wassersättigung entlang jeder Bohrung zu berechnen. Dieses Profil dient als hochwertige, physikinformierte Kennzeichnung – eine Art „Pseudo‑Kern“ –, die in jeder Tiefe vorhanden ist und nicht nur an einigen beprobten Intervallen. Die Forschenden speisen dann übliche Bohrlochlogs wie Gamma Ray, Neutronenporosität, Dichte und Tiefenwiderstand in eine breite Palette von Machine‑Learning‑Modellen. Dazu gehören baumbasierte Ensembles (Random Forest, XGBoost, CatBoost), Support‑Vector‑Machines und mehrere neuronale Netzwerkarchitekturen, einschließlich eines speziellen rekurrenten Netzwerks namens LSTM, das Muster erkennen kann, die sich mit der Tiefe entwickeln. Sorgfältige Vorverarbeitung, Ausreißerscreening und Normalisierung helfen sicherzustellen, dass die Modelle echte geologische Zusammenhänge und nicht Rauschen lernen.
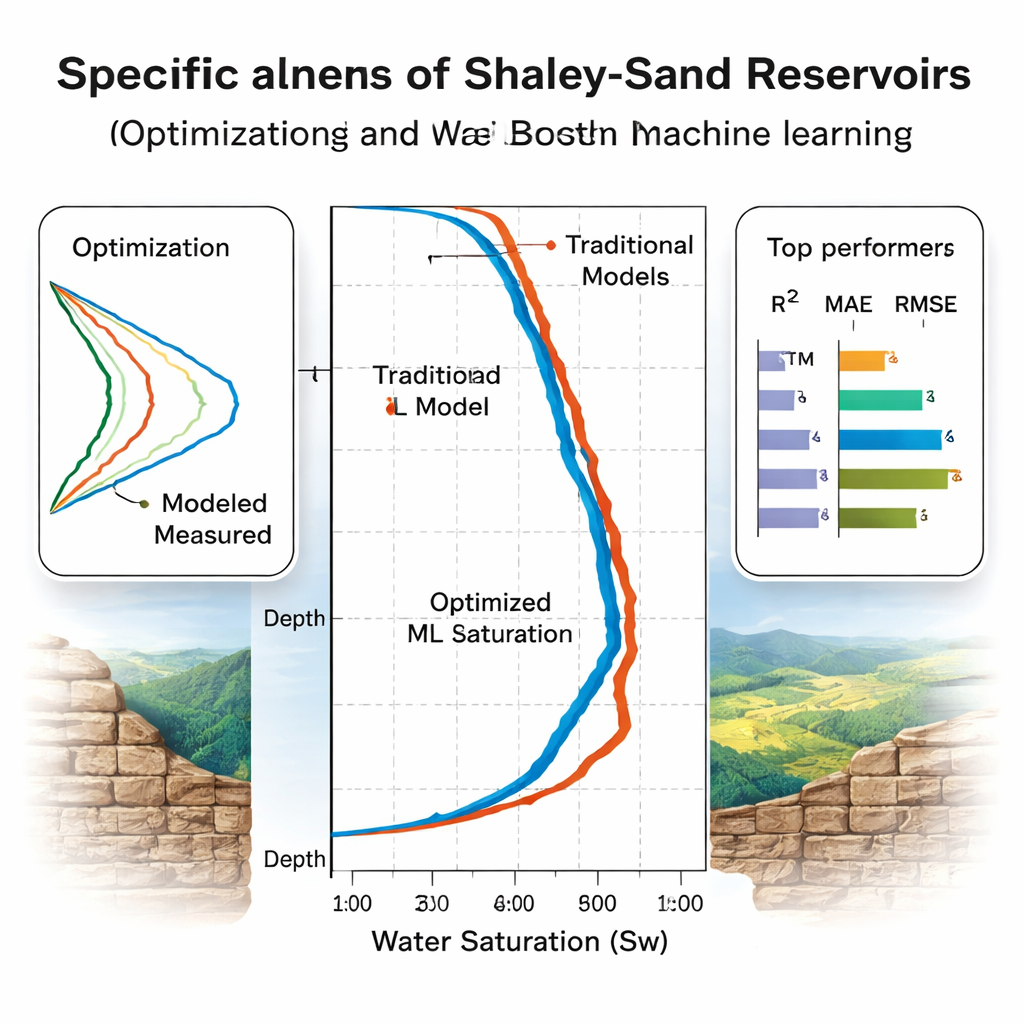
Welche Modelle generalisieren wirklich?
Das Team bewertet die Modelle in zwei Stufen. Zuerst verwenden sie Five‑Fold‑Cross‑Validation auf acht Nordsee‑Bohrungen, um die Modelle zu optimieren und zu rangieren; dabei scheint Random Forest bei den standardmäßigen Genauigkeitsmaßen zu führen. Der aussagekräftigere Test sind jedoch drei „blinde“ Bohrungen, darunter zwei aus einem geologisch unterschiedlichen ägyptischen Becken, die nie für das Training genutzt wurden. Hier zeigen einige Modelle Schwächen: Die Leistung des Random Forest sinkt, was auf Overfitting an das ursprüngliche Becken hindeutet. Im Gegensatz dazu halten gradientenverstärkte Bäume (CatBoost und XGBoost) sowie LSTM‑ und bayesisch‑regularisierte neuronale Netzwerke eine hohe Genauigkeit, erklären über 93–94 % der Variation der Wassersättigung bei moderaten Fehlern. Eine Feature‑Importance‑Analyse mit SHAP, einem modernen Interpretationswerkzeug, bestätigt, dass die Modelle am stärksten auf physikalisch sinnvolle Eingaben wie Widerstand, Porosität und Tonanteil setzen.
Warum das in einfachen Worten wichtig ist
Für Nicht‑Spezialisten lautet die Kernidee: Die Autoren verwenden zunächst die Physik, um das Problem zu bereinigen und zu verankern, und setzen erst danach Machine Learning ein. Indem ein Optimierungsverfahren die bestpassende Wasserwiderstandsfähigkeit findet und diese in einen dichten, physikrespektierenden Trainingssatz verwandelt, umgehen sie das übliche Nadelöhr knapper und teurer Kernproben. Ihre Ergebnisse zeigen, dass dieser „Optimierung‑zuerst, ML‑danach“-Ansatz vertrauenswürdige Schätzungen liefert, wie stark ein shaley Reservoir mit Wasser versus Kohlenwasserstoffen gefüllt ist, sogar in neuen Becken, die nicht für das Training genutzt wurden. Praktisch hilft das Betreibern, zahlbare Zonen zuverlässiger zu kartieren, unnötiges Kernen zu reduzieren und die Schätzung der vorhandenen Kohlenwasserstoffe zu verbessern – und das alles durch klügere Nutzung bereits erhobener Daten.
Zitation: Hameedy, M.A.E., Mabrouk, W.M. & Metwally, A.M. Integrating optimization and machine learning for estimating water resistivity and saturation in shaley sand reservoirs. Sci Rep 16, 6342 (2026). https://doi.org/10.1038/s41598-026-36133-w
Schlüsselwörter: shaley Sandlagerstätten, Wassersättigung, Wasserleitwert der Formation, Machine Learning in der Petrophysik, Reservoir‑Charakterisierung