Clear Sky Science · de
Aufmerksamkeitsgesteuerte räumlich‑zeitliche Merkmalsfusion für robuste Anomalieerkennung in der Videoüberwachung
Warum intelligentere Kameras wichtig sind
Von belebten Bahnhöfen bis zu Einkaufszentren: Das moderne Leben ist voller Sicherheitskameras, die stillschweigend alles aufzeichnen, was geschieht. Die meisten dieser Videos werden jedoch—wenn überhaupt—von müden Menschen betrachtet, die leicht entscheidende Momente übersehen können. Diese Arbeit untersucht ein neues „intelligentes“ Überwachungssystem, das ungewöhnliches oder riskantes Verhalten wie Diebstahl oder Vandalismus in Echtzeit automatisch erkennen kann, indem es sowohl versteht, was in einer Szene zu sehen ist, als auch wie sich das Geschehen im Zeitverlauf verändert.

Mehr sehen als nur Pixel
Ein herkömmlicher Kamerastream ist nur eine Abfolge von Bildern. Ältere Computersysteme versuchten, Probleme zu erkennen, indem sie jede Einzelaufnahme für sich betrachteten und nach Formen und Kanten suchten, die Menschen oder Objekten ähneln. Die Autoren prüfen zunächst eine moderne Variante dieser Idee, die ein kompaktes Bilderkennungsnetz mit klassischen Kantendetektoren kombiniert. Dieses Setup funktioniert recht gut in sauber eingerahmten Szenen, insbesondere um deutliche visuelle Hinweise wie das Greifen eines Gegenstands zu bemerken. Da der Fokus jedoch auf Einzelaufnahmen liegt, gerät es an seine Grenzen, wenn Personen einander verdecken, sich Menschenmengen verdichten oder eine gleiche Körperhaltung je nach zeitlicher Entwicklung entweder normal oder verdächtig sein kann.
Bewegung und Verhalten verstehen
Um die Geschichte hinter einer Handlung zu erfassen—nicht nur das Aussehen eines einzelnen Frames—evaluierte die Studie anschließend ein videozentriertes Modell, das kurze Clips statt Standbilder analysiert. Dieses Modell lernt, wie sich Bewegung über mehrere Frames hinweg entfaltet, und erkennt besser plötzliche Veränderungen wie Rennen, Prügeleien oder das Wegreißen eines Gegenstands. Es erweist sich als gut darin, viele abnormale Ereignisse zu erfassen, was zu hoher Sensitivität führt. Gleichzeitig leidet es jedoch an einem klassischen Praxisproblem: Wirklich ungewöhnliche Ereignisse sind im Vergleich zum Alltag selten. Daher kann das Modell instabil werden, zu viele Fehlalarme auslösen und sorgfältig vorgeschnittene Videosegmente benötigen, die die unordentliche, kontinuierliche Natur realer Überwachungsaufnahmen nicht widerspiegeln.
Verschmelzen von Ort und Zeit
Aufbauend auf den Stärken und Schwächen dieser beiden Ausgangsvarianten schlagen die Autoren ein neues Hybridsystem namens HybridModel-1 vor, das darauf abzielt, gleichzeitig räumlich und zeitlich zu „denken“. Es kombiniert ein Netzwerk, das sehr gut darin ist, zu verstehen, welche Objekte in jedem Frame vorhanden sind, mit einem schnellen Detector, der diese Objekte in der Szene lokalisieren kann. Ein spezielles Fusionsmodul lernt, die informativsten visuellen Details—etwa Personen und wichtige Objekte—zu betonen und Hintergrundstörungen wie Wände, Bäume oder vorbeifahrende Autos abzuschwächen. Gleichzeitig bestraft eine neue Trainingsstrategie das System sanft, wenn seine Zuversicht von einem Frame zum nächsten sprunghaft schwankt, und bewegt es so zu gleichmäßigeren, konsistenteren Entscheidungen über ein ganzes Video hinweg.
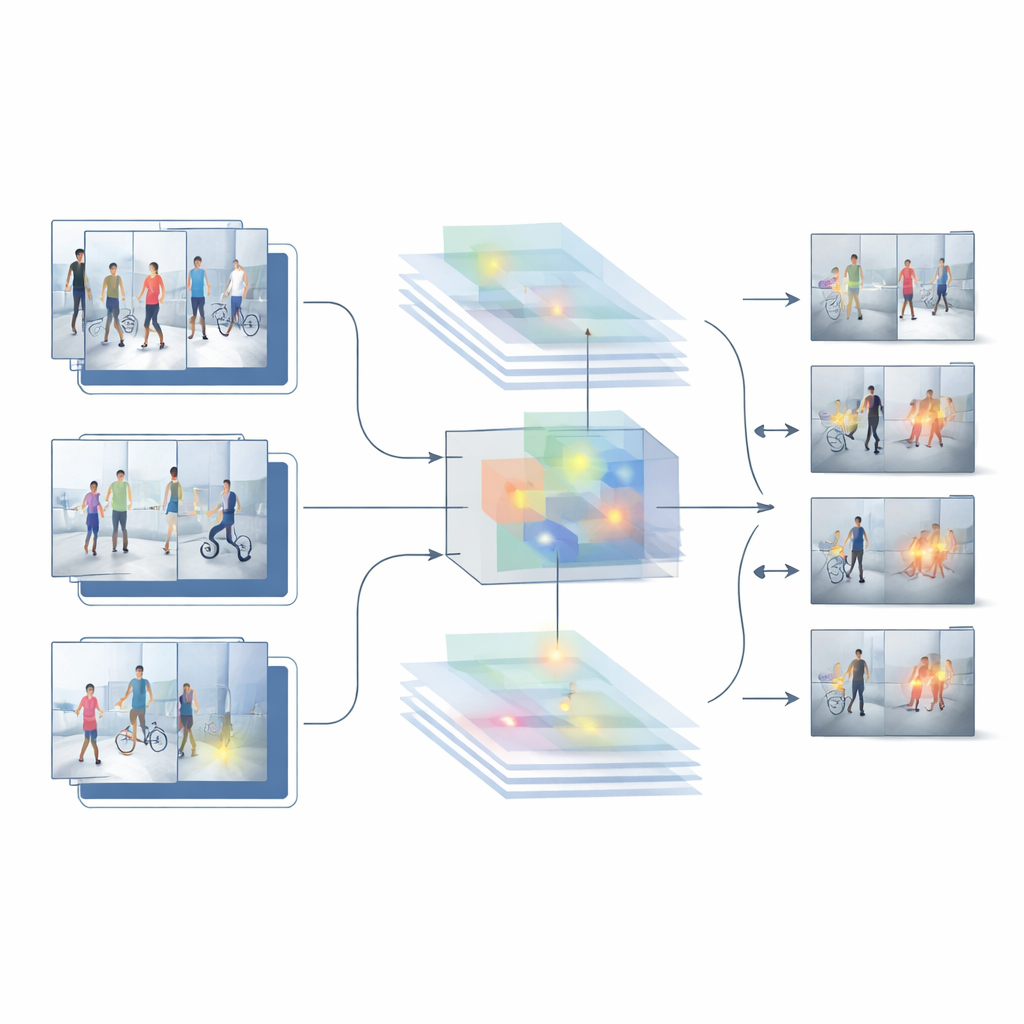
Das System auf die Probe stellen
Um zu prüfen, ob dieses Design außerhalb des Labors funktioniert, testen die Forschenden es an mehreren herausfordernden öffentlichen Datensätzen mit realen Überwachungsaufnahmen. Diese Sammlungen umfassen alles von Diebstählen in Innenräumen bis zu Fußwegen auf Campusgeländen, mit unterschiedlichen Kamerapositionen, Lichtverhältnissen, Menschenmengen und Vorfallarten. Über diese Benchmarks hinweg übertrifft das Hybridmodell sowohl die rein bildbasierten als auch die rein videobasierten Ausgangsmodelle. Es erzielt eine höhere Gesamtgenauigkeit, löst deutlich weniger Fehlalarme aus und behält starke Leistungen selbst bei Aufnahmen bei, für die es nicht trainiert wurde. Detaillierte Vergleiche und Ablationsstudien—bei denen Systemteile entfernt oder verändert werden—zeigen, dass sowohl das Merkmals‑Fusionsmodul als auch der auf Glätte ausgerichtete Trainingsschritt jeweils einen bedeutsamen Beitrag zu diesen Verbesserungen leisten.
Was das für die tägliche Sicherheit bedeutet
Vereinfacht gesagt zeigt diese Arbeit, dass Überwachungssysteme zuverlässiger werden, wenn sie lernen, sich auf die richtigen Bereiche einer Szene zu konzentrieren und ihre Urteile über die Zeit hinweg stabil zu halten. Anstatt jeden Frame als isoliertes Bild zu behandeln oder sich ausschließlich auf rohe Bewegung zu verlassen, verbindet der vorgeschlagene Ansatz „was“ und „wann“ in einem einzigen, sorgfältig abgestimmten Rahmen. Zwar bleiben Herausforderungen bei extrem dunklen oder stark verdeckten Blicken bestehen, doch die Ergebnisse deuten auf einen praktischen Weg zu Kameranetzwerken hin, die große Mengen an Video still überwachen, wirklich verdächtige Ereignisse hervorheben und die Belastung durch Fehlalarme für menschliche Operatoren verringern. Für die Öffentlichkeit könnte das sicherere Räume bedeuten, die von Systemen überwacht werden, die nicht nur beobachten, sondern wirklich verstehen, was sie sehen.
Zitation: Nivethika, S.D., Joshi, S., Verma, K. et al. Attention-guided saptio-temporal feature fusion for robus video surveillance anomaly detection. Sci Rep 16, 8027 (2026). https://doi.org/10.1038/s41598-026-36130-z
Schlüsselwörter: Videoüberwachung, Anomalieerkennung, intelligente Kameras, Kriminalitätserkennung, maschinelles Lernen