Clear Sky Science · de
Integration von Random-Forest-basierter Regression-Kriging zur Analyse räumlicher Variabilität von Niederschlag in ariden und semi-ariden Regionen
Warum die Kartierung von Regen in Trockengebieten wichtig ist
In Ländern, in denen Wasser knapp ist, kann das genaue Wissen darüber, wo und wann Regen fällt, den Unterschied zwischen Ernährungssicherheit und Krise ausmachen. Pakistan erstreckt sich über Gebirge, Wüsten und fruchtbare Ebenen, und der Niederschlag ist durch den Klimawandel unbeständiger geworden. Bodengestützte Wetterstationen sind jedoch rar und weit auseinander. Diese Studie stellt eine praktische Frage: Kann man mit begrenzten Daten und modernen Methoden des maschinellen Lernens kombiniert mit klassischen Kartierungstechniken schärfere, verlässlichere Niederschlagskarten erstellen, die Landwirtschaft, Hochwasserplanung und Wassermanagement leiten?
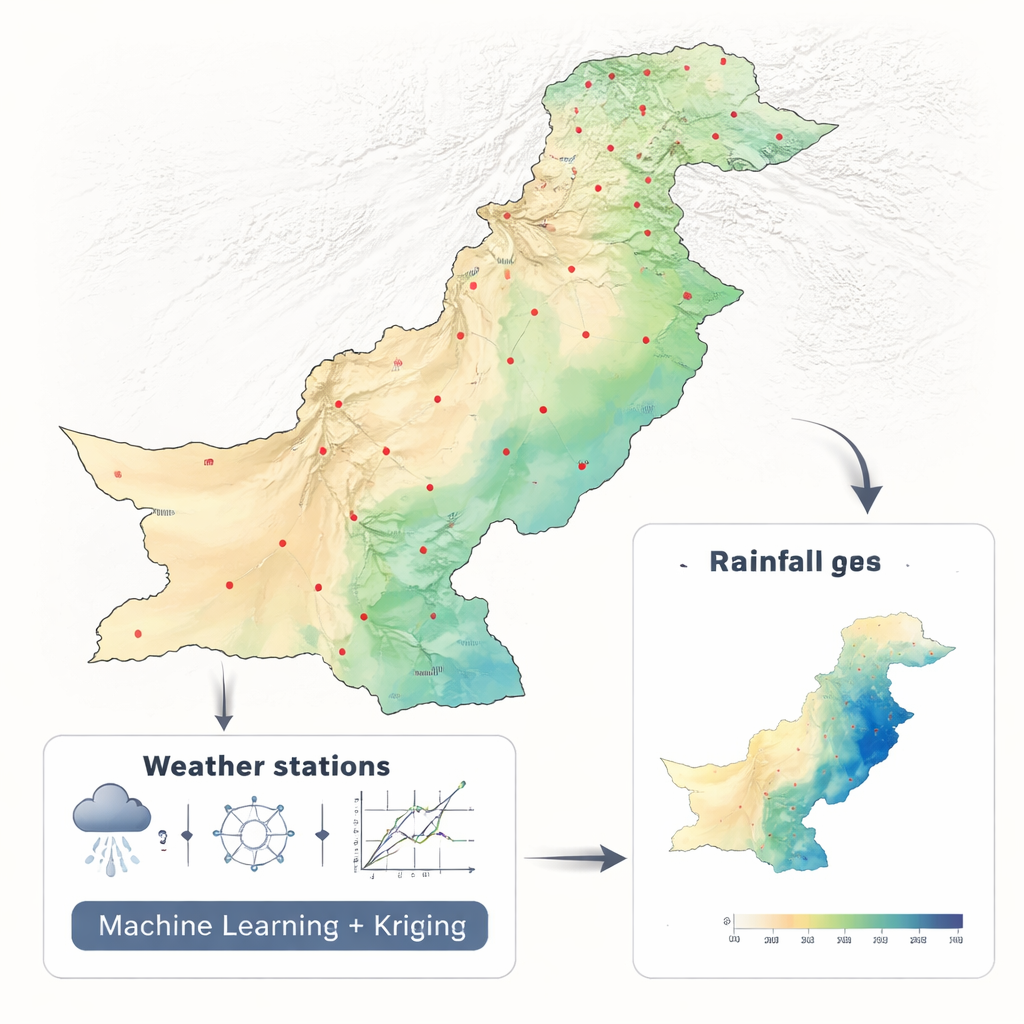
Aus verstreuten Regenmessern vollständige Karten machen
Die Forschenden arbeiteten mit zwei Jahrzehnten monatlicher Niederschlagsdaten (2001–2010 und 2011–2021) von 42 Stationen in Pakistan und nutzten ein konsistentes Klimadatenset der NASA. Anstatt Dutzende Umweltvariablen in ein komplexes Modell einzuspeisen, verwendeten sie bewusst nur Breiten- und Längengrad. Dieses reduzierte Design erlaubte es ihnen, sich auf eine zentrale Frage zu konzentrieren: Welcher mathematische Ansatz verwandelt verstreute Punktmessungen am besten in eine kontinuierliche Karte? Sie verglichen sechs Methoden des maschinellen Lernens — Random Forest, Support Vector Machine, K-Nearest Neighbors, Neuronales Netzwerk, Elastic Net und Polynomregression — jeweils eingebettet in ein Framework namens Regression-Kriging, das in den Geowissenschaften weit verbreitet ist.
Großdatenartiges Lernen mit räumlicher Intuition verbinden
Regression-Kriging arbeitet in zwei Stufen. Zuerst sagt ein Regressionsmodell den Niederschlag an jedem Ort aus seinen Koordinaten voraus und erfasst grobe Muster wie feuchtere Berge und trockenere Wüsten. Dann füllt eine räumliche Methode namens Kriging die verbleibenden, lokal gemusterten Unterschiede zwischen Beobachtungen und Vorhersagen auf. Um diesen zweiten Schritt verlässlich zu machen, untersuchte das Team zunächst, wie ähnlich oder unterschiedlich der Niederschlag zwischen Stationspaaren in verschiedenen Entfernungen ist — ein Werkzeug, das Variogramm genannt wird. Sie fanden, dass einfache „zirkuläre“ und „lineare“ mathematische Formen am besten beschrieben, wie die Niederschlagsähnlichkeit mit der Entfernung über Jahreszeiten und zwischen den beiden Jahrzehnten abnimmt, ein Hinweis auf glatte, regionsweite Regensysteme statt abrupten Sprüngen.
Random Forest erweist sich als Spitzenreiter
Sobald die räumliche Struktur feststand, übernahm jede Methode des maschinellen Lernens reihum die Rolle der Regressionsmaschine im hybriden Modell. Die Autorinnen und Autoren bewerteten die Leistung mit üblichen Fehlermaßen und danach, wie viel Niederschlagsvarianz das Modell erklären konnte. In nahezu allen Monaten und beiden Jahrzehnten lieferte der auf Random Forest basierende Ansatz die genauesten und stabilsten Karten. Er verringerte Vorhersagefehler deutlich gegenüber der Polynomregression und übertraf konstant Support Vector Machines, neuronale Netze und andere Methoden, besonders während der Monsunmonate, wenn der Niederschlag am stärksten und am variabelsten ist. Die resultierenden Karten waren dort glatt, wo sie es sein sollten, erfassten aber dennoch scharfe Kontraste zwischen trockenen und feuchten Zonen bei relativ geringer Unsicherheit.
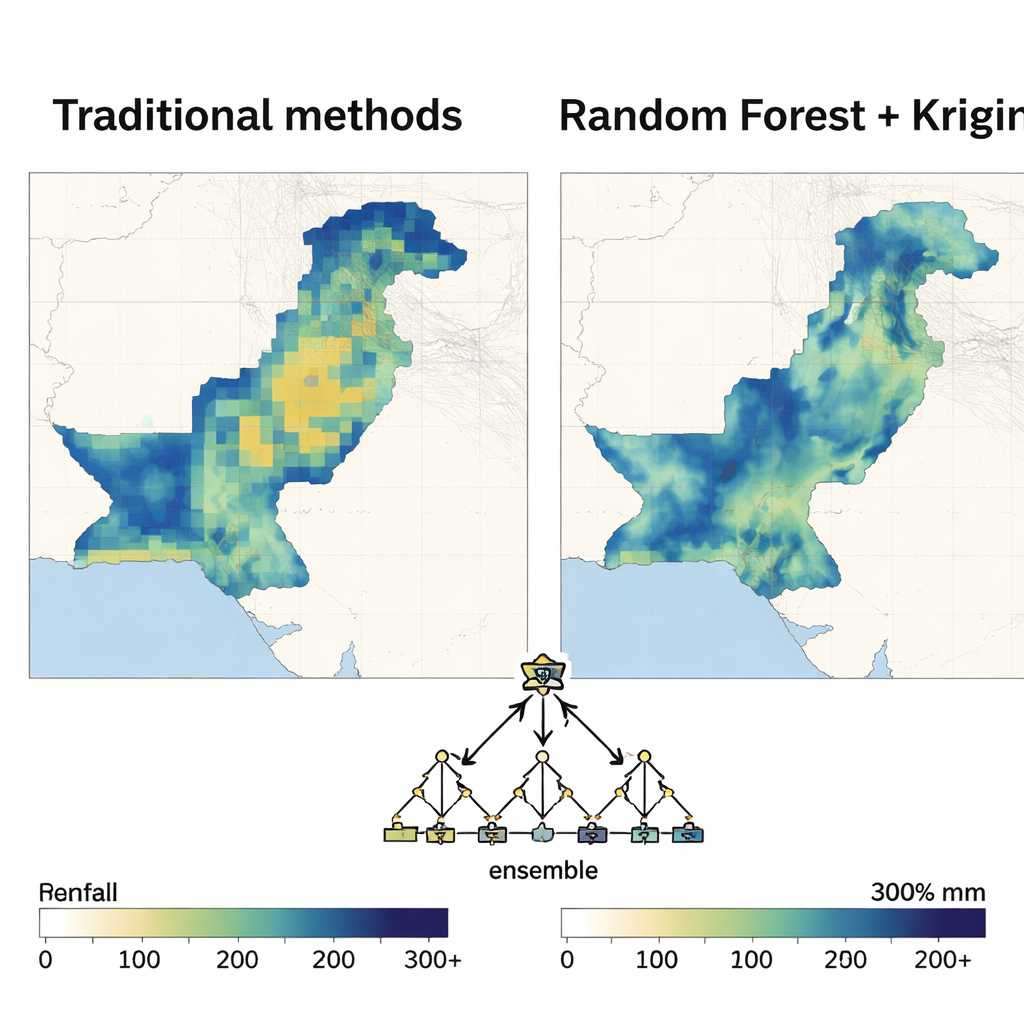
Was sich ändernde Niederschlagsmuster offenbaren
Beim Vergleich der beiden Jahrzehnte zeigte die Studie auch Anzeichen für verschobenes Niederschlagsverhalten. Im Mittel war das spätere Jahrzehnt (2011–2021) feuchter und zeichnete sich durch größere monatliche und räumliche Variabilität aus, besonders im Frühling und während des Monsuns. Die räumliche Struktur des Niederschlags wurde diffuser, was auf breitere Schwankungen in der Verteilung des Wassers hindeutet. Wichtig ist: Die Kombination aus Random Forest und Kriging bewältigte sowohl das frühere, etwas mildere Klima als auch die variablere jüngere Periode, ohne Genauigkeit einzubüßen, was nahelegt, dass solche flexiblen Werkzeuge gut für eine sich erwärmende, weniger vorhersehbare Welt geeignet sind.
Von Karten zu Entscheidungen vor Ort
Praktisch zeigt das Papier, dass intelligente Algorithmen mehr Wert aus begrenzten Niederschlagsaufzeichnungen ziehen können und hochauflösende Karten erzeugen, die selbst in datenarmen Regionen nützlich sind. Für Pakistan können diese Karten bessere Planung von Bewässerung, Stauseinrichtungen und Hochwasserschutz unterstützen und helfen, Gemeinden zu identifizieren, die besonders von Dürre oder Starkregen bedroht sind. Die Autoren betonen, dass ihre Arbeit ein Proof of Concept ist, das sich auf die Kartierungstechniken selbst konzentriert und noch kein vollständiges Hochwasser- oder Dürrewarnsystem darstellt. Dennoch ist ihre Schlussfolgerung klar: Die Kombination aus Ensemble-Machine-Learning, angeführt von Random Forest, und geostatistischer Kartierung bietet einen leistungsfähigen, praxisnahen Weg, um Veränderungen des Niederschlags in trockenen und halb-trockenen Gebieten weltweit zu verfolgen.
Zitation: Manaf, M., Ali, Z. & Scholz, M. Integrating random forest-based regression kriging for analyzing spatial variability of rainfall in arid and semi-arid regions. Sci Rep 16, 5298 (2026). https://doi.org/10.1038/s41598-026-36074-4
Schlüsselwörter: Niederschlagskartierung, Random Forest, Regression-Kriging, Klima Pakistan, Wasserressourcen