Clear Sky Science · de
Cross-well Machine-Learning-Vorhersage von Sonik-Logs in Neufundland und Labrador
Gestein zuhören ohne Mikrofon
Öl- und Gasunternehmen nutzen akustische „sonische“ Werkzeuge, um zu hören, wie sich Schallwellen durch unterirdische Gesteine ausbreiten. Diese detaillierten Messungen helfen Ingenieuren, die Festigkeit des Gesteins einzuschätzen, sichere Bohrungen zu planen und Bohrdaten mit seismischen Messungen abzugleichen. Sonik-Instrumente sind jedoch teuer, können den Betrieb verlangsamen und lassen sich manchmal überhaupt nicht einsetzen. Diese Studie zeigt, wie maschinelles Lernen Sonik-Informationen aus billigeren, routinemäßig gesammelten Messungen rekonstruieren kann und so eine Möglichkeit bietet, den Untergrund „zu hören“, selbst wenn das Mikrofon fehlt.
Warum die Vorhersage von Sonik-Daten wichtig ist
Bei Offshore-Bohrungen zeichnen Betreiber viele Logtypen auf: natürliche Radioaktivität, Bohrgeschwindigkeit, Pumpenrate, Gewicht auf dem Bohrkopf und mehr. Sonik-Logs sind besonders, weil sie zeigen, wie schnell sich Schall durch Gestein ausbreitet — ein zentraler Eingangsparameter zur Abschätzung von Gesteinssteifigkeit, Druck und Spannungen. Fehlen Sonik-Instrumente, müssen Ingenieure mit Lücken arbeiten oder sich auf grobe Faustregeln verlassen. Indem maschinelles Lernen gängige Nicht-Sonik-Logs in genaue „Pseudo-Sonik“-Kurven verwandelt, können Unternehmen Kosten für Datenerfassung senken, fehlende Abschnitte füllen und dennoch fundierte Entscheidungen über Bohrstabilität und Reservoir-Verhalten treffen.
Ein sorgfältiges Rezept, um Schummeln zu verhindern
Die Autoren arbeiteten mit Daten aus zwei Offshore-Brunnen in Neufundland und Labrador. Für jede Tiefe versuchten sie, die Druckwellenschnelligkeit (compressional slowness — eine Art, wie lange eine Schallwelle benötigt, um sich durchs Gestein zu bewegen) nur anhand nicht-sonischer Messungen vorherzusagen. Entscheidend war, dass jeglicher Input, der direkt oder indirekt Sonik-Daten nutzte — etwa abgeleitete elastische Eigenschaften — verboten war. Features wurden außerdem nur aus Informationen derselben Tiefe oder flacherer Tiefen gebildet, um Echtzeit-Bohrbedingungen zu simulieren, bei denen die Zukunft unbekannt ist. Ausreißer in den Sensordaten wurden mithilfe von Statistiken aus nur einem „Trainings“-Brunnen identifiziert und dann in beiden Brunnen gleich behandelt, sodass die Modelle nicht heimlich aus den Testdaten lernen konnten. Alle Skalierungen und Feature-Wahlen wurden ebenfalls am Trainingsbrunnen festgelegt, bevor sie unverändert auf den anderen Brunnen angewendet wurden.
Wie Roh-Logs in lernbare Signale verwandelt werden
Roh-Logs einfach einem Algorithmus zu übergeben, reicht selten aus. Das Team entwickelte eine umfangreiche Menge tiefebewusster Features: Sie verfolgten, wie sich jedes Log mit der Tiefe änderte, glätteten rauschbehaftete Signale auf mehreren Skalen und berechneten Steigungen und Krümmungen, die lokale Trends hervorheben. Tiefe wurde zudem relativ zu Abschnitten des Bohrlochs ausgedrückt, um Muster zu erfassen, die sich beim Wechsel der Bohrkronengröße wiederholen. Um die Modelle nicht zu überfrachten, wurden Features mit drei verschiedenen Methoden gerankt und die Ranglisten zu einer einzigen geordneten Liste kombiniert. Eine kompakte Gruppe der informativsten Merkmale wurde dann mithilfe einer zeitbewussten Aufteilung innerhalb des Trainingsbrunnens ausgewählt, sodass der Auswahlprozess selbst die natürliche Tiefenordnung respektierte.
Baumbasierte Modelle schlagen Deep Learning
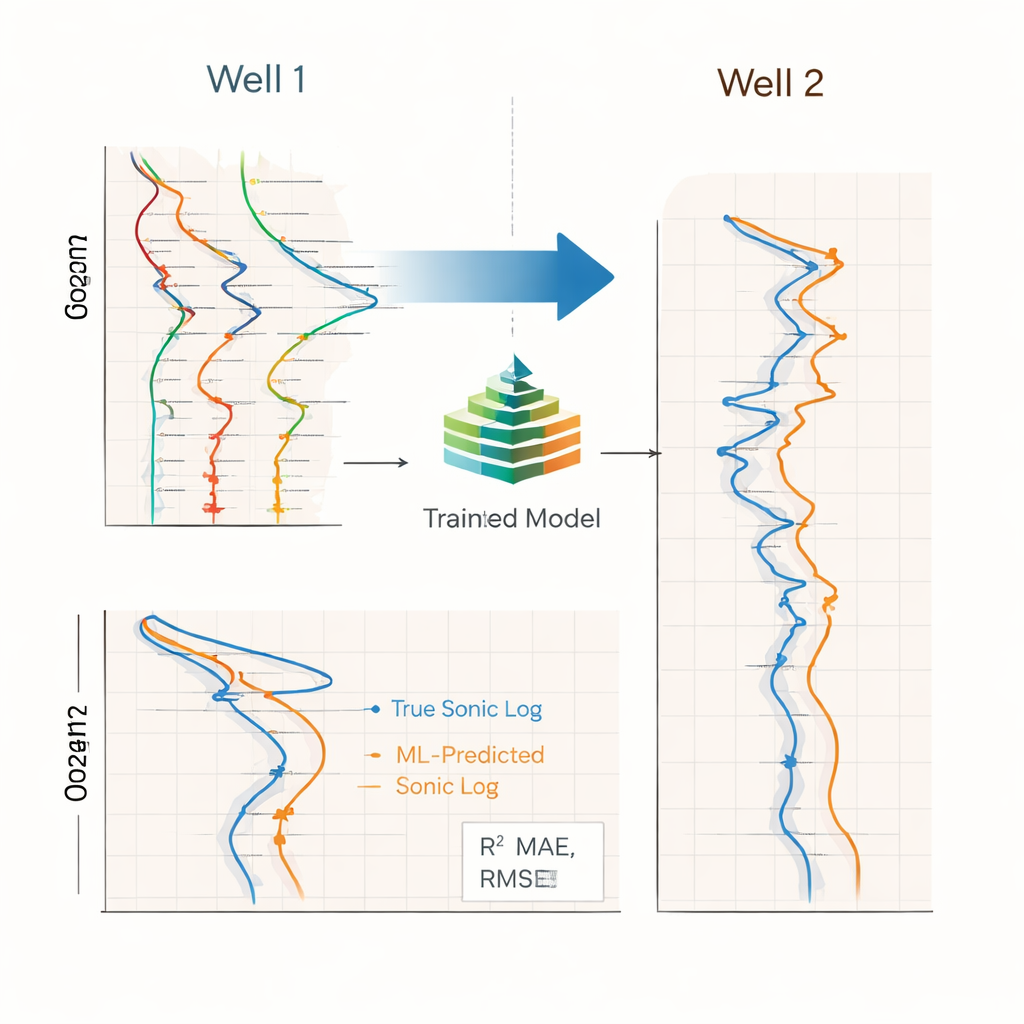
Die Studie verglich drei Modelltypen: Random Forests, XGBoost (eine verbreitete Gradient-Boosting-Methode) und bidirektionale LSTM-Neuronale Netze, die oft für Sequenzdaten verwendet werden. Jedes Modell wurde an einem Brunnen trainiert und blind am anderen getestet — ein anspruchsvolles Setup, das Unterschiede zwischen Brunnen in Tiefenbereich, Betriebsbedingungen und Gesteinsarten aufdeckt. Unter diesem Test schnitt XGBoost am besten ab und erzielte hohe Übereinstimmung zwischen prognostizierten und gemessenen Sonik-Logs, wenn auf den zweiten Brunnen übertragen. Random Forests lagen dicht dahinter und waren in verrauschten Zonen manchmal stabiler. LSTM-Netze hinkten trotz ihrer Komplexität bei Genauigkeit und Robustheit hinterher, vermutlich weil nur zwei Brunnen vorlagen und die Daten stark mit der Tiefe variierten — Bedingungen, die große neuronale Netze nicht begünstigen.
Was die Genauigkeit antreibt und wo es nützt
Indem die Autoren verschiedene Teile ihrer Vorverarbeitung ein- und ausschalteten, zeigten sie, dass intelligente Feature-Generierung und -Selektion den größten Leistungsunterschied ausmachten — stärker noch als längere Historienfenster oder einfache Ausreißerfilter allein. Mit diesen Schritten generalisierten die baumbasierten Modelle deutlich besser zwischen den Brunnen. Die resultierenden Pseudo-Sonik-Logs waren genau genug, um nachgelagerte Aufgaben zu unterstützen, etwa die Schätzung der Gesteinssteifigkeit, Modellierung von Porendruck und Spannungen, Kalibrierung seismischer Daten und Planung von Bohrungen in Bereichen, in denen direkte Sonik-Messungen fehlen, verzögert sind oder unzuverlässig erscheinen. Da alle Transformationen an einem Referenzbrunnen fixiert und dann wiederverwendet werden, könnte der Workflow nahezu in Echtzeit während des Bohrens betrieben werden.
Kernergebnis für Nicht-Fachleute
Diese Arbeit zeigt, dass sich mit disziplinierter Datenverarbeitung und wohlgewählten maschinellen Lernmodellen hochwertige Sonik-Informationen aus günstigeren Bohr- und Logging-Kanälen in einem neuen, dem Modell unbekannten Brunnen rekonstruieren lassen. Der Ansatz ersetzt keine dedizierten Sonik-Instrumente, insbesondere dort, wo Sicherheitsmargen eng sind, bietet aber ein praktisches und kosteneffizientes Backup sowie eine Qualitätskontrolle, wenn gemessene Daten verdächtig erscheinen. Mit mehr Brunnen und Regionen sowie neuen Modellen, die unter den gleichen strengen Regeln getestet werden, könnte diese Art der Cross-Well-Vorhersage Teil des digitalen Instrumentariums für sicherere und effizientere Offshore-Bohrungen werden.
Zitation: Zare, B., Huque, M.M., James, L.A. et al. Cross-well machine learning prediction of sonic logs in Newfoundland and Labrador. Sci Rep 16, 5292 (2026). https://doi.org/10.1038/s41598-026-36053-9
Schlüsselwörter: maschinelles Lernen, Sonik-Logs, Well-Logging, Offshore-Bohrung, Reservoir-Charakterisierung