Clear Sky Science · de
Auf dem Weg zur Umwandlung von MATLAB-Modellen in FPGA-basierte Hardwarebeschleuniger
Laboralgorithmen in realen Geräten umsetzen
Viele moderne medizinische und technische Durchbrüche beginnen als Software, die Forscher häufig in benutzerfreundlichen Werkzeugen wie MATLAB schreiben. Wenn diese Algorithmen jedoch in Echtzeit laufen müssen – etwa um gefährliche Herzrhythmusstörungen in einem Elektrokardiogramm (EKG) zu erkennen – benötigen sie die Geschwindigkeit und Effizienz kundenspezifischer Hardware. Dieser Artikel zeigt, wie man ein komplexes, herzschlag-erkennendes neuronales Netz zuverlässig von MATLAB auf einen spezialisierten Chip (FPGA) überträgt, ohne die Genauigkeit zu verlieren, auf die Ärzte und Ingenieure angewiesen sind.
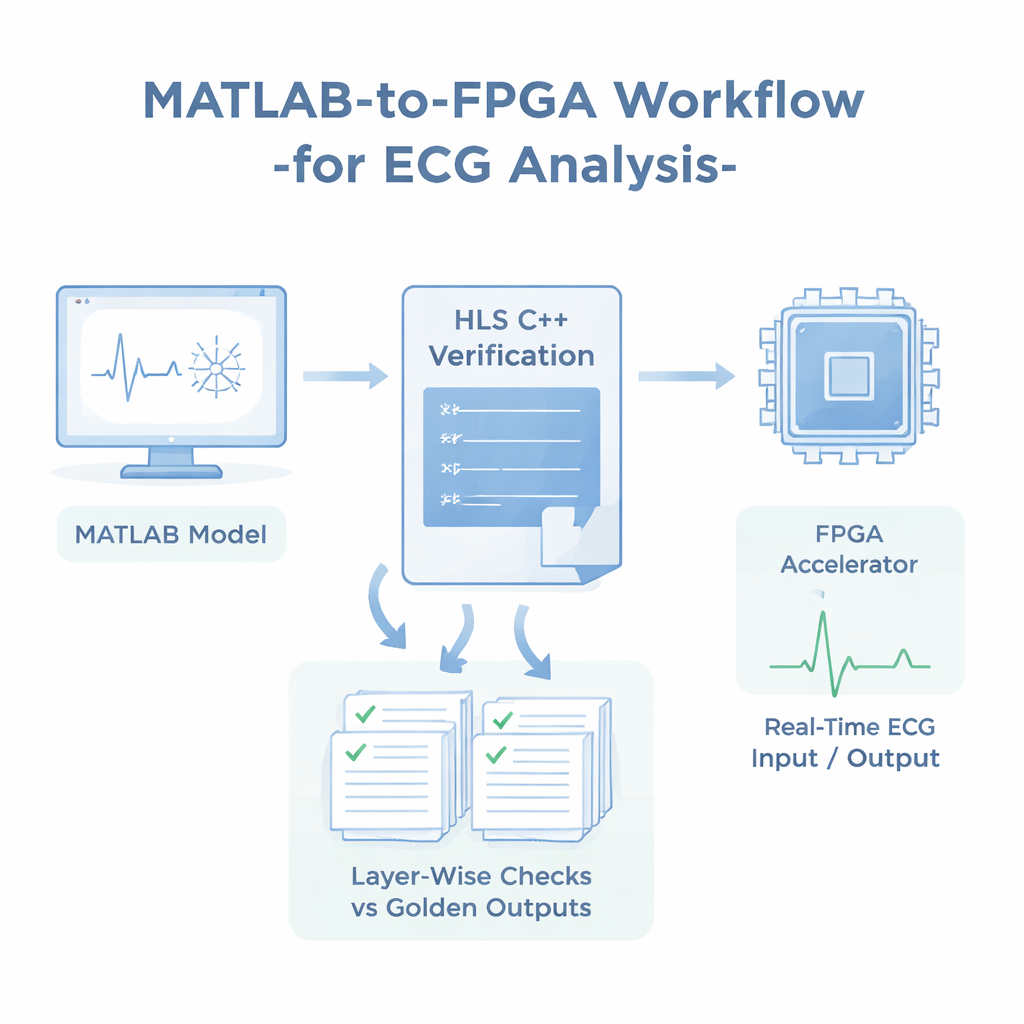
Warum das Umprogrammieren für Chips so schwer ist
FPGAs (Field-Programmable Gate Arrays) sind rekonfigurierbare Chips, geschätzt für ihre Geschwindigkeit und niedrigen Stromverbrauch. Traditionell erforderte ihre Programmierung hardwarezentrierte Sprachen wie VHDL oder Verilog, die weit von dem hochstufigen Mathematik- und Signalverarbeitungs-Code entfernt sind, den Wissenschaftler in MATLAB schreiben. Neue Werkzeuge können Algorithmen automatisch in Hardwarebeschreibungen umwandeln, erfordern jedoch oft manuelle Anpassungen und konzentrieren sich hauptsächlich auf Leistung: wie schnell der Chip läuft und wie viele Ressourcen er benötigt. Was bisher fehlte, ist ein klarer Weg, um zu beweisen, dass die Hardware genau das tut, was die ursprüngliche Software tut – Schicht für Schicht, Zahl für Zahl.
Eine Schritt-für-Schritt-Prüfung für jede Netzwerkschicht
Der Autor schließt diese Lücke mit einem verifikationsorientierten Workflow für ein eindimensionales Faltungsneuronales Netz, das Herzschläge aus der bekannten MIT-BIH-Arrhythmie-Datenbank klassifiziert. Das in MATLAB entwickelte Netz untersucht kurze Ausschnitte von EKG-Daten und ordnet sie einer von fünf Herzschlagtypen zu, einschließlich normaler und mehrerer abnormer Rhythmen. Drei Versionen des Netzes mit unterschiedlicher Tiefe werden mit denselben Daten trainiert. Nach dem Training werden Gewichte, Biases und die Ausgaben jeder Schicht bei Tests als „goldene Ausgaben“ gespeichert – ein präziser numerischer Bericht darüber, wie sich das MATLAB-Modell verhält.
Von MATLAB über C++ zum FPGA, mit verfolgten Zahlen
Anstatt auf einen automatischen "Konvertieren"-Knopf zu drücken, wird das Netz manuell in C++ nachimplementiert, wobei dasselbe Datenlayout und dieselben mathematischen Schritte wie in MATLAB beibehalten werden. Dieser C++-Code wird dann mit einem High-Level-Synthesis-Tool verwendet, um Hardware zu erzeugen, die auf einer PYNQ-Z1-FPGA-Platine läuft. In jeder Phase – MATLAB, C++ und FPGA – werden die Schichtausgaben mit den gespeicherten goldenen Ausgaben verglichen, wobei ein einfaches Maß verwendet wird: der mittlere absolute Fehler, der die durchschnittliche numerische Differenz zwischen zwei Ergebnissets angibt. Die Studie legt eine strenge Toleranz fest: alle Schichten müssen unter einem Fehler von 1,5×10⁻³ bleiben. Über tausende EKG-Proben erfüllt jede geprüfte Schicht dieses Ziel, und die endgültige Klassifikationsgenauigkeit bleibt nahezu unverändert: etwa 98,3–98,4 % in MATLAB und C++, und nur rund 0,2 Prozentpunkte niedriger auf dem FPGA, ein Unterschied, der mit den erwarteten Effekten kürzerer Festkommazahlen in der Hardware übereinstimmt.

Die Hardware beschleunigen, ohne die Mathematik zu zerstören
Sobald die Korrektheit gesichert ist, wird das Design auf Geschwindigkeit abgestimmt. Die anspruchsvollsten Teile des Netzes – die Faltungsschichten – werden auf die programmierbare Logik des FPGAs abgebildet und verwenden aus Effizienzgründen Festkommaarithmetik, während leichtere Aufgaben wie die abschließende Softmax-Berechnung auf dem eingebauten Prozessor des Chips mit normaler Gleitkommaarithmetik ausgeführt werden. Techniken wie Loop-Pipelining, Loop-Unrolling und die sorgfältige Aufteilung des Speichers in parallele Bänke ermöglichen es, verschiedene Teile der Berechnung und Datenübertragungen nebeneinander laufen zu lassen. Eine optimierte Hardwareversion verarbeitet ein Herzschlagfenster in etwa 1,7 Millisekunden und passt bequem in die Ressourcen- und Leistungsgrenzen des FPGAs, während sie gleichzeitig das schichtweise numerische Verhalten des ursprünglichen MATLAB-Modells bewahrt.
Was das für zukünftige intelligente Geräte bedeutet
Für Nicht-Spezialisten lautet die Kernbotschaft: Es ist jetzt möglich, nicht nur einen anspruchsvollen MATLAB-basierten Herzrhythmus-Klassifikator auf einem energieeffizienten Chip zu beschleunigen, sondern auch zu beweisen, dass die inneren Abläufe des Chips auf jeder Schicht eng mit dem vertrauenswürdigen Softwaremodell übereinstimmen. Anstatt der Geschwindigkeit auf Kosten der Zuverlässigkeit hinterherzujagen, schafft dieser Ansatz eine klare Prüfkette vom Gleitpunkt-MATLAB-Code zur Festkomma-FPGA-Hardware. Dasselbe Verifikationsrezept – goldene Ausgaben speichern, schichtweise Fehler gegen eine strenge Schwelle vergleichen und die Endgenauigkeit prüfen – kann auf andere eindimensionale neuronale Netze in Bereichen wie tragbaren Gesundheitsmonitoren, Industriesensoren und intelligenten Fahrzeugen angewendet werden und trägt dazu bei, sicherzustellen, dass Entscheidungen, die aus dem Labor in Geräte überführt werden, verlässlich bleiben.
Zitation: Bal, S. Towards the transformation of MATLAB models into FPGA-Based hardware accelerators. Sci Rep 16, 5027 (2026). https://doi.org/10.1038/s41598-026-36033-z
Schlüsselwörter: FPGA-Beschleuniger, MATLAB-Neuronale Netze, EKG-Arrhythmie-Klassifikation, Hardware-Verifikation, Festkomma-Deep-Learning