Clear Sky Science · de
Selbstüberwachtes Lernen auf Graphen sagt Nicht-kodierende RNA–Krankheits-Assoziationen vorher
Warum versteckte RNA für unsere Gesundheit wichtig ist
Die meisten von uns lernten, dass die Hauptaufgabe der RNA darin besteht, beim Aufbau von Proteinen zu helfen. In den letzten zehn Jahren entdeckten Wissenschaftler jedoch eine große Anzahl „nicht-kodierender“ RNAs, die nie zu Proteinen werden, aber dennoch die Funktionsweise unserer Zellen steuern. Viele dieser Moleküle sind inzwischen dafür bekannt, Krebs und andere komplexe Erkrankungen zu fördern oder zu unterdrücken. Zu wissen, welche nicht-kodierenden RNAs mit welchen Krankheiten verknüpft sind, könnte neue Wege eröffnen, Krankheiten früh zu diagnostizieren oder präzisere Therapien zu entwickeln – aber jede Möglichkeit im Labor zu testen wäre unmöglich langsam. Diese Studie stellt eine leistungsfähige rechnergestützte Methode vor, die riesige biologische Netzwerke durchsieben und zuverlässig die vielversprechendsten RNA–Krankheits-Verbindungen vorschlagen kann, die Forscher experimentell überprüfen sollten.
Vom „Genmüll“ zu wichtigen zellulären Akteuren
Jahrelang wurden nicht-kodierende RNAs als bedeutungslose Überbleibsel der Genaktivität abgetan. Heute wissen wir, dass Familien wie microRNAs, lange nicht-kodierende RNAs und zirkuläre RNAs wichtige Prozesse orchestrieren — von der Verpackung der DNA über das Ein- und Ausschalten von Genen bis hin zur Signalweiterleitung innerhalb der Zelle. Da sie an vielen Kontrollpunkten sitzen, können schon kleine Veränderungen in diesen RNAs das Gleichgewicht zugunsten von Krebs oder anderen Erkrankungen verschieben. Kliniker sehen sie bereits als potenzielle Biomarker und Wirkstoffziele. Die Herausforderung ist der Umfang: Es gibt Tausende verschiedener RNAs und Hunderte von Krankheiten, und traditionelle Experimente zur Prüfung jeder möglichen Verbindung sind teuer und zeitaufwendig. Hier setzt die rechnerische Vorhersage an, die hilft, den Suchraum einzugrenzen.
Wie man ein biologisches Netzwerk liest
Frühere rechnerische Methoden versuchten, RNA–Krankheits-Verknüpfungen vorherzusagen, indem sie große Datentabellen in einfachere Teile zerlegten oder maschinelle Lernmodelle mit bekannten Beispielen trainierten. Diese Ansätze halfen, aber sie vernachlässigten oft, wie RNAs und Krankheiten in Netzwerke eingebunden sind. Moderne „graphneurale Netze“ behandeln RNAs und Krankheiten als Knoten, die durch Kanten verbunden sind — ähnlich einem sozialen Netzwerk. Sie können Muster darin lernen, wer mit wem verbunden ist. Allerdings benötigen die meisten dieser Graphmethoden viele verlässliche Trainingsbeispiele und sorgfältig gestaltete Eingabemerkmale. Das macht sie anfällig für fehlende Daten, verrauschte Messungen und Overfitting — sie liefern gute Ergebnisse auf bekannten Daten, versagen aber bei der Vorhersage neuer Assoziationen.
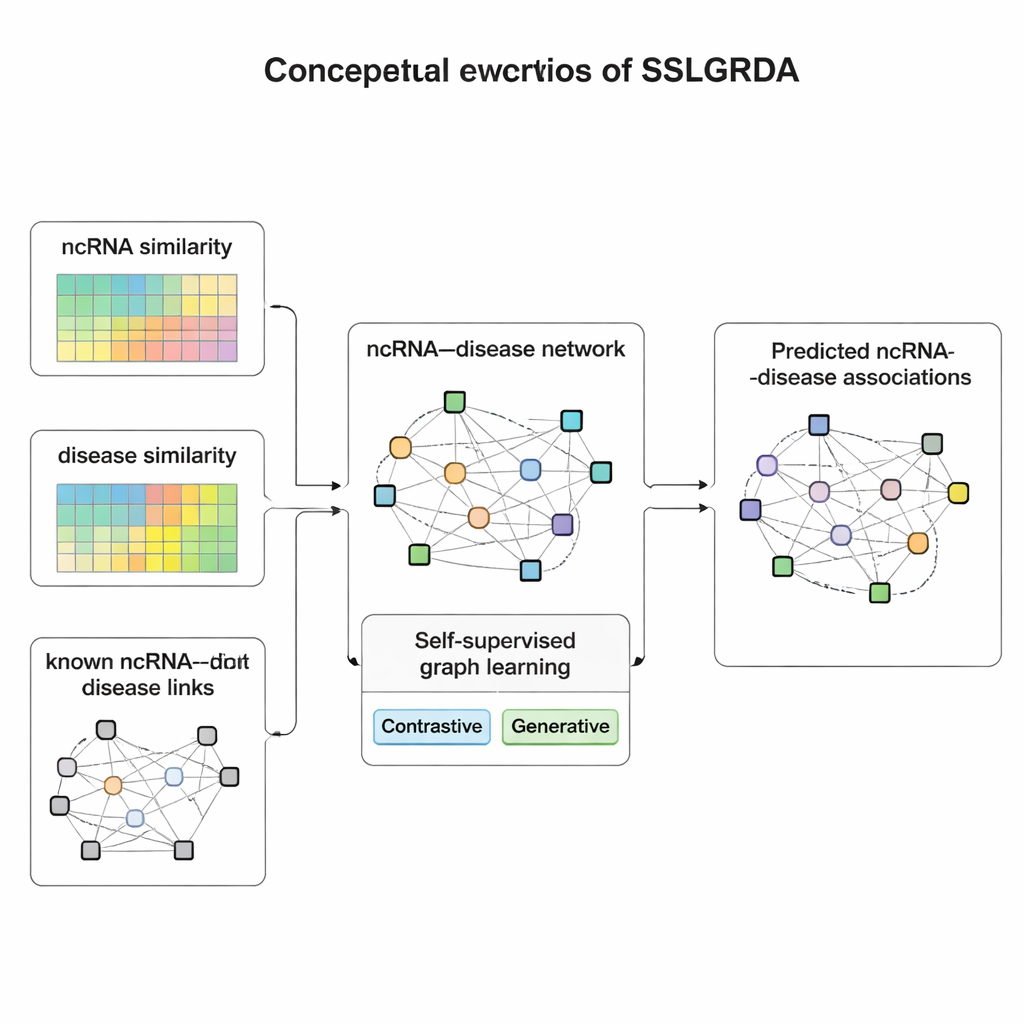
Vom Datensatz selbst lernen
Die Autoren stellen SSLGRDA vor, ein neues Framework, das ein Graphmodell lehrt, nützliche Muster zu lernen, ohne stark auf gelabelte Trainingsdaten angewiesen zu sein. Die zentrale Idee ist „selbstüberwachtes Lernen“: Anstatt dem Modell zu sagen, welche RNA mit welcher Krankheit gepaart ist, erfindet das Modell eigene Übungsaufgaben, die allein auf der Struktur und den Attributen des Netzwerks basieren. Die Forschenden bauen zwei Arten von Graphen: Einer behält RNAs und Krankheiten als unterschiedliche Knotentypen mit bekannten Verbindungen bei. Der andere mischt sie zu einem einzigen großen Netzwerk, das zusätzlich Ähnlichkeitsinformationen enthält — wie ähnlich sich zwei RNAs oder zwei Krankheiten sind — sodass auch spärlich verbundene Elemente unterstützende Nachbarn erhalten. Auf diesen Graphen setzt SSLGRDA zwei Formen des Selbsttrainings ein. Kontrastive Strategien fordern das Modell heraus zu erkennen, dass verschiedene „Sichten“ desselben Knotens (zum Beispiel seine Verbindungen gegenüber seinen Attributen) zu ähnlichen internen Repräsentationen führen sollten, während nicht verwandte Knoten klar getrennt werden. Generative Strategien verbergen gezielt Teile der Eingabemerkmale und fordern das Modell auf, diese zu rekonstruieren, wodurch es ermutigt wird, tiefere Struktur zu erfassen statt Rauschen auswendig zu lernen.
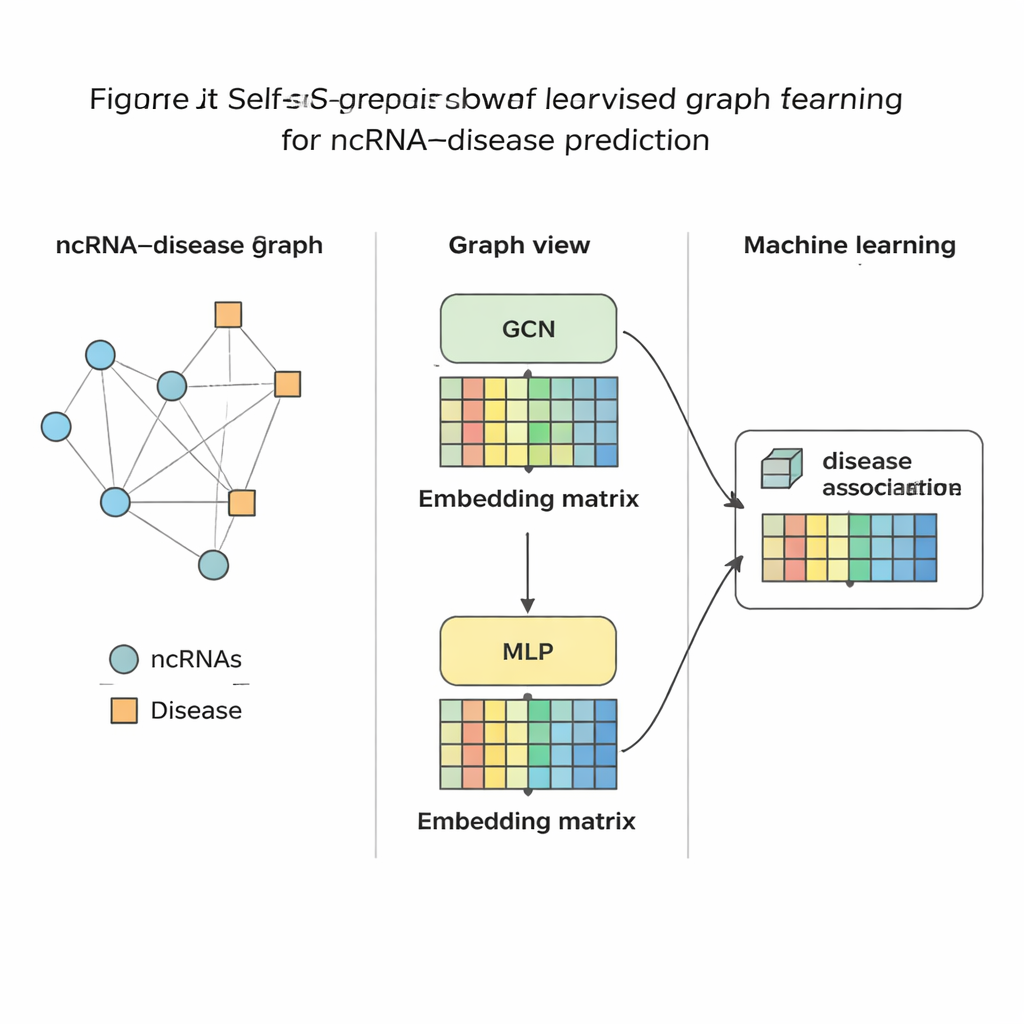
Die Methode im Praxistest
Nachdem SSLGRDA jede RNA und Krankheit in einen kompakten numerischen Fingerabdruck destilliert hat, wird ein Standard-Classifier trainiert, um zu beurteilen, ob eine Verbindung zwischen ihnen wahrscheinlich ist oder nicht. Die Autoren bewerteten diesen Ansatz an neun verschiedenen Datensätzen, die drei wichtige RNA-Typen und Hunderte von Krankheiten abdecken. Insgesamt schnitten die kontrastiven, selbstüberwachten Varianten auf dem gemischten (homogenen) Graphen am besten ab und übertrafen eine Reihe bestehender Werkzeuge, einschließlich starker graphbasierter Baselines. Die Methode erzielte nicht nur höhere Genauigkeit in globalen Tests, sondern platzierte in Einzelanalysen die richtigen Partner weit oben — entscheidend für den realen Einsatz, wenn ein Biologe etwa von einem einzelnen Krebs ausgeht und wissen möchte, welche RNAs untersucht werden sollten. Die Autoren zeigten außerdem, dass sich dieselben Ideen gut auf andere biomedizinische Netzwerke übertragen lassen, etwa solche, die Mikroben mit Krankheiten oder Medikamenten verbinden.
Von Vorhersagen zu potenziellen Therapien
Um den praktischen Nutzen zu demonstrieren, wandte das Team SSLGRDA an, um nach neuen nicht-kodierenden RNAs zu suchen, die an Brustkrebs, Darmkrebs und mehreren anderen Erkrankungen beteiligt sein könnten. Viele der am höchsten gerankten Vorschläge wurden später in unabhängigen Datenbanken oder wissenschaftlichen Berichten bestätigt, was die Fähigkeit des Modells unterstützt, biologisch bedeutungsvolle Muster zu erkennen. Für Nicht-Spezialisten lautet die Erkenntnis, dass diese Arbeit eine klügere Methode bereitstellt, im immer weiter wachsenden Geflecht biologischer Daten nach versteckten Krankheits-Hinweisen zu suchen. Indem selbstüberwachte Graphmethoden wie SSLGRDA automatisch lernen, wie RNAs und Krankheiten clusterbilden und interagieren, können sie Laborforschende zu den vielversprechendsten Zielen führen und damit den Weg von Rohdaten zu besseren Diagnostika und Therapien potenziell beschleunigen.
Zitation: Wu, Q., Tang, S. Self-supervised learning on graphs predicts non-coding RNA and disease associations. Sci Rep 16, 5231 (2026). https://doi.org/10.1038/s41598-026-36030-2
Schlüsselwörter: nicht-kodierende RNA, Krankheitsassoziation, Graphneurale Netze, selbstüberwachtes Lernen, computationale Biologie