Clear Sky Science · de
Autonome Navigation in unstrukturierten Außenbereichen mittels semantisch segmentierter, leitungsbasierter Verstärkungslernverfahren
Roboter, die den Wald erwandern lernen
Stellen Sie sich einen kleinen Roboter vor, der einen Waldpfad ganz allein bewältigt, zwischen Bäumen und Felsen hindurchmanövriert, ohne GPS oder einen Menschen am Joystick. Dieses Papier beschreibt ein System, das solchen Robotern beibringt, Pfade im dichten Wald „zu sehen“ und in jedem Moment zu entscheiden, wie sie sich sicher vorwärts bewegen. Die Arbeit ist relevant für künftige Roboter, die bei Waldüberwachung, Brandprävention, Suche und Rettung oder sogar bei Lieferungen im Freien helfen könnten – gerade dort, wo Satellitensignale schwach oder nicht vorhanden sind.
Warum Wälder für Roboter so schwierig sind
Wälder gehören zu den härtesten Umgebungen für autonome Maschinen. Pfade können schmal und verschlungen sein, der Untergrund ist uneben, Äste und Sträucher verstellen oft die Sicht, und hohe Bäume machen GPS unzuverlässig. Traditionelle Navigationsmethoden setzen präzise Karten, zuverlässiges GPS oder teure Lasersensoren voraus und gehen meist von klaren, strukturierten Bereichen wie Straßen oder Fabrikhallen aus. Im Wald versagen diese Annahmen: Schatten, Jahreszeitenwechsel und dichte Vegetation verwirren einfache Sichtsysteme, während regelbasierte Kontrollmechanismen mit all den unordentlichen, unerwarteten Situationen auf einem echten Pfad kaum zurechtkommen.
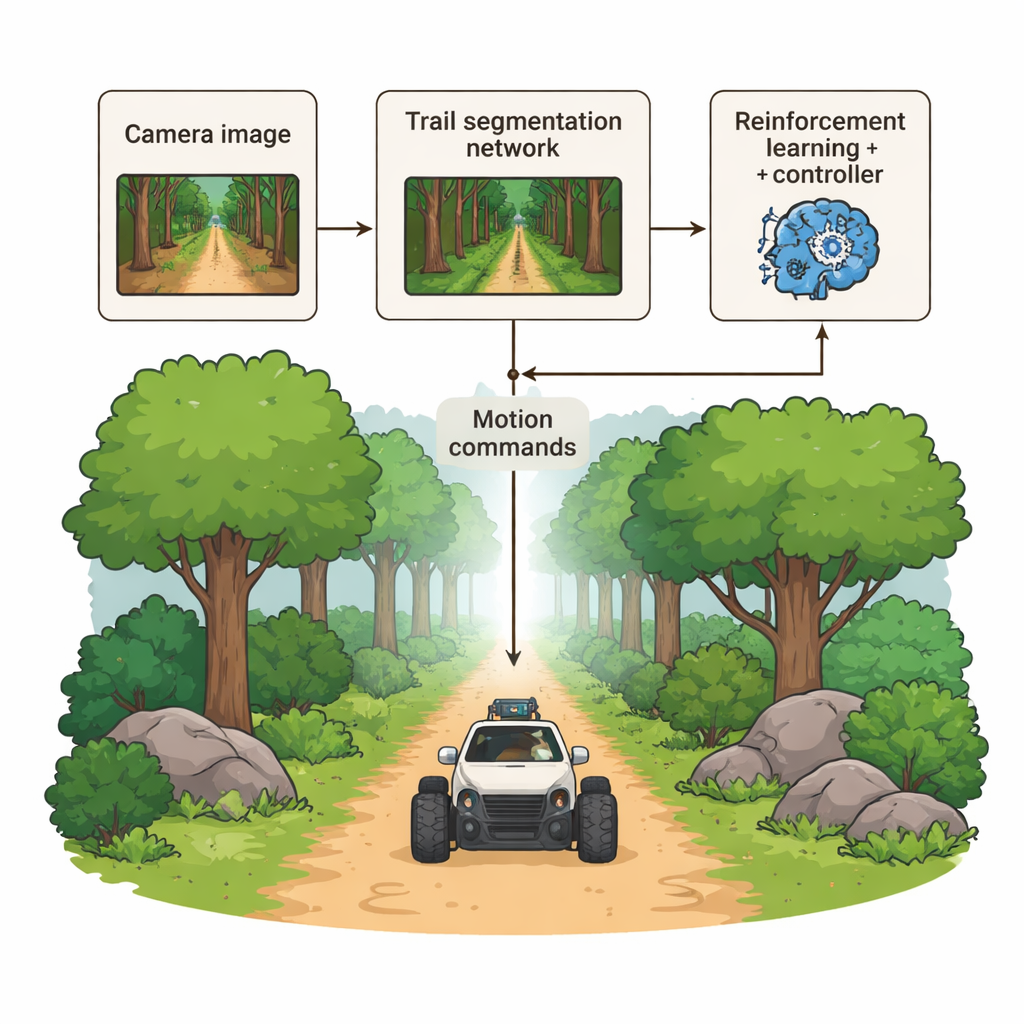
Drei Gehirne arbeiten zusammen
Die Autoren schlagen ein hybrides Navigationssystem vor, das dem Roboter drei sich ergänzende „Gehirne“ gibt. Erstens analysiert ein tiefes Visionsmodul jedes Kamerabild und markiert, fast Pixel für Pixel, welche Bereiche zum begehbaren Pfad gehören. Zweitens trifft ein lernbasiertes Entscheidungsmodul mithilfe von Verstärkungslernen sanfte Lenk- und Geschwindigkeitsbefehle, wobei Verhalten belohnt wird, das auf dem Pfad bleibt, Kollisionen vermeidet und das Ziel effizient erreicht. Drittens wandelt ein klassischer Regler die vorhergesagte Form des Pfades in stabile Radbewegungen um, glättet ruckartige Bewegungen und hält die Bahn des Roboters geschmeidig statt ruckartig. Statt eines einzelnen, intransparenten End-to-End-Netzes sind diese Module getrennt, aber eng verknüpft, sodass Ingenieure jede Stufe verstehen und debuggen können.
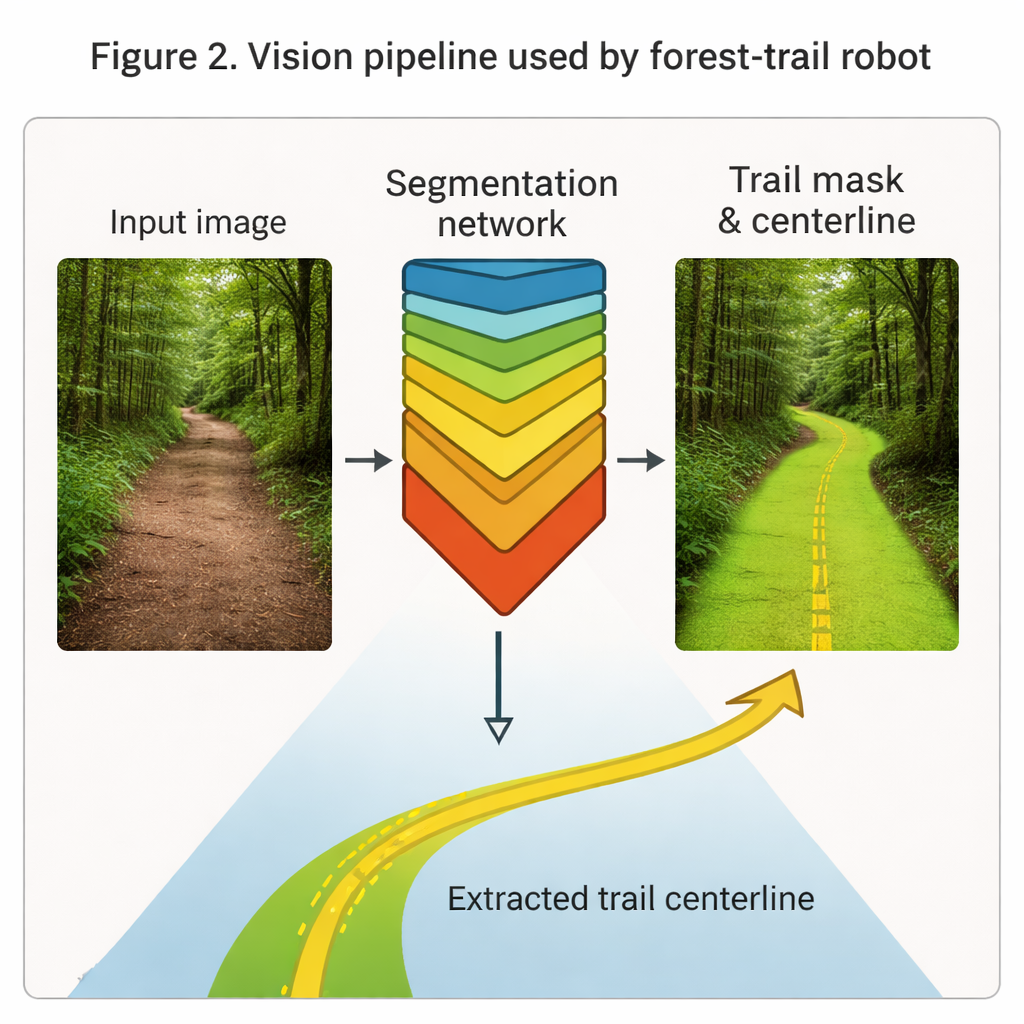
Dem Sehen beibringen, Pfade zu erkennen
Im Zentrum der „Augen“ des Roboters steht ein tiefes Netzwerk namens Mask R-CNN, hier darauf abgestimmt, Waldpfade in gewöhnlichen Farbbildern hervorzuheben. Trainiert an fast 24.000 annotierten Frames von realen Wanderaufnahmen aus Menschhöhe unter wechselnden Licht-, Wetter- und Pfadbedingungen, lernt das System, die Pfadregion in jedem Frame als saubere Maske darzustellen. Aus dieser Maske wird eine dünne Mittellinienkurve extrahiert, die Richtung und Krümmung des vor dem Roboter liegenden Wegs erfasst. In Tests erreicht das Visionsmodul eine hohe Übereinstimmung mit menschlichen Markierungen und über 90 % Pixelgenauigkeit und zeichnet Pfade robust nach, selbst wenn Äste oder Schatten Teile des Wegs verdecken. Diese geometrischen Hinweise fließen direkt als kompakte Beschreibung von „wo der Weg ist“ in die Lern- und Regelmodule ein.
Einem Roboter beibringen, gute Entscheidungen zu treffen
Das zweite Schlüsselelement ist das Entscheidungsmodul, das eine Technik namens Verstärkungslernen verwendet. Anstatt ihm genau vorzuschreiben, was zu tun ist, probiert der Roboter Aktionen in einem realistischen simulierten Wald aus und erhält Belohnungen für gute und Strafen für schlechte Ergebnisse. Vorwärtsbewegen auf dem Pfad ist gut; Abdriften, Kollisionen mit Hindernissen oder Festfahren sind schlecht. Über etwa 150.000 Trainingsschritte hinweg entdeckt das System schrittweise Strategien, die den Roboter zentriert auf dem Pfad halten, Kurven geschmeidig handhaben und sinnvoll reagieren, wenn Äste oder Felsen auftauchen. Um Bewegungen glatt und sicher zu halten, können die gelernten Aktionen mit denen des klassischen Reglers gemischt werden, was besonders in engen Kurven oder bei verrauschten Bedingungen hilfreich ist.
Das System auf die Probe stellen
Um zu bewerten, wie gut diese Kombination funktioniert, bauten die Forscher drei detaillierte virtuelle Wälder: einen mit engen, stark zugestellten Pfaden, einen weiteren mit steilem, unebenem Gelände und großen Hindernissen und einen dritten mit Gabelungen, Sackgassen und ablenkenden Fehlpfaden. In 90 Versuchen auf diesen Karten erreichte der Roboter in etwa 87 % der Durchläufe das Ziel ohne Kollision, mit im Mittel nur 0,2 Remplern pro Fahrt und blieb typischerweise innerhalb von etwa 30 Zentimetern vom Pfadzentrum. Er bewältigte die Strecken außerdem zügig und konsistent. Wenn die Autoren nacheinander ein Modul entfernten oder vereinfachten, brach die Leistung deutlich ein – ein Hinweis darauf, dass alle drei Komponenten notwendig sind. Im Vergleich zu anderen aktuellen Systemen, darunter solche mit Laserscannern, lieferte dieser rein visuelle Hybridansatz die beste Mischung aus Erfolgsrate, Präzision und Sicherheit.
Was das für reale Roboter bedeutet
Für Nichtfachleute lautet die Quintessenz: Roboter werden besser darin, wie vorsichtige, kompetente Wanderer Pfade zu begehen. Durch die Kombination eines starken visuellen Kontexts („das ist der Weg“), erfahrungsbasierten Entscheidens („diese Manöver haben sich bewährt“) und eines stabilen Lenkmechanismus ermöglicht das vorgeschlagene System einem kleinen Radroboter, komplexe Wälder ohne Karten oder GPS zu durchqueren. Obwohl die Arbeit in Simulationen getestet wurde und weiterhin Herausforderungen wie extremes Licht und seltene Pfadtypen bestehen, bietet sie eine praktikable Anleitung für zukünftige Feldroboter, die wildnisverträglich und sicher mit Menschen koexistieren können, um Wälder zu inspizieren, Rettungsteams zu unterstützen und natürliche Ressourcen effektiver zu verwalten.
Zitation: Tibermacine, A., Tibermacine, I.E., Akrour, D. et al. Autonomous navigation in unstructured outdoor environments using semantic segmentation guided reinforcement learning. Sci Rep 16, 2633 (2026). https://doi.org/10.1038/s41598-026-36022-2
Schlüsselwörter: autonome Navigation, Waldrobotik, Computer Vision, Verstärkungslernen, semantische Segmentierung