Clear Sky Science · de
IL2Pepscan: Ein Machine‑Learning‑Framework zur Vorhersage von IL‑2‑induzierenden Peptiden und deren Identifikation in globalen Virusproteomen
Das Immunsystem mit winzigen Proteinfragmenten lehren
Moderne Impfstoffe und Krebstherapien setzen zunehmend darauf, das Immunsystem gezielt zu steuern, statt Krankheiten mit breit wirkenden Medikamenten zu bekämpfen. Diese Studie untersucht, wie winzige Proteinfragmente, sogenannte Peptide, ausgewählt werden können, um einen kräftigen Immunbotenstoff, Interleukin‑2 (IL‑2), anzuschalten. Mithilfe fortgeschrittener Computermodelle durchforsten die Autorinnen und Autoren sowohl bekannte Immun‑Daten als auch die Proteinkataloge tausender Viren, um Nadel‑im‑molekularen‑Heuhaufen‑Peptide zu finden, die bei der Entwicklung besserer Impfungen und Immuntherapien helfen könnten.
Warum IL‑2 für Gesundheit und Krankheit wichtig ist
IL‑2 ist ein kleines Signalmolekül, das wie ein Wachstumsfaktor für zentrale Immunzellen, die T‑Zellen, wirkt. Wenn diese Zellen einem Eindringling begegnen – etwa einem Virus oder einer Krebszelle – können sie IL‑2 freisetzen, das dann die Vermehrung, Spezialisierung und Gedächtnisbildung der T‑Zellen fördert. IL‑2 trägt außerdem zur Aufrechterhaltung regulatorischer T‑Zellen bei, die das Immunsystem davon abhalten, körpereigene Gewebe anzugreifen. Aufgrund dieser Doppelrolle wurde IL‑2 als Arzneimittel zur Behandlung von Krebsarten wie Melanom eingesetzt und wird für Autoimmunerkrankungen erforscht. Die direkte Gabe von IL‑2 kann jedoch belastend für Patientinnen und Patienten sein, weshalb das Interesse wächst, sichere Peptide zu entwerfen, die den Körper auf kontrolliertere und gezieltere Weise zur Produktion von IL‑2 anregen.
Den „Geschmack“ IL‑2‑induzierender Peptide lernen
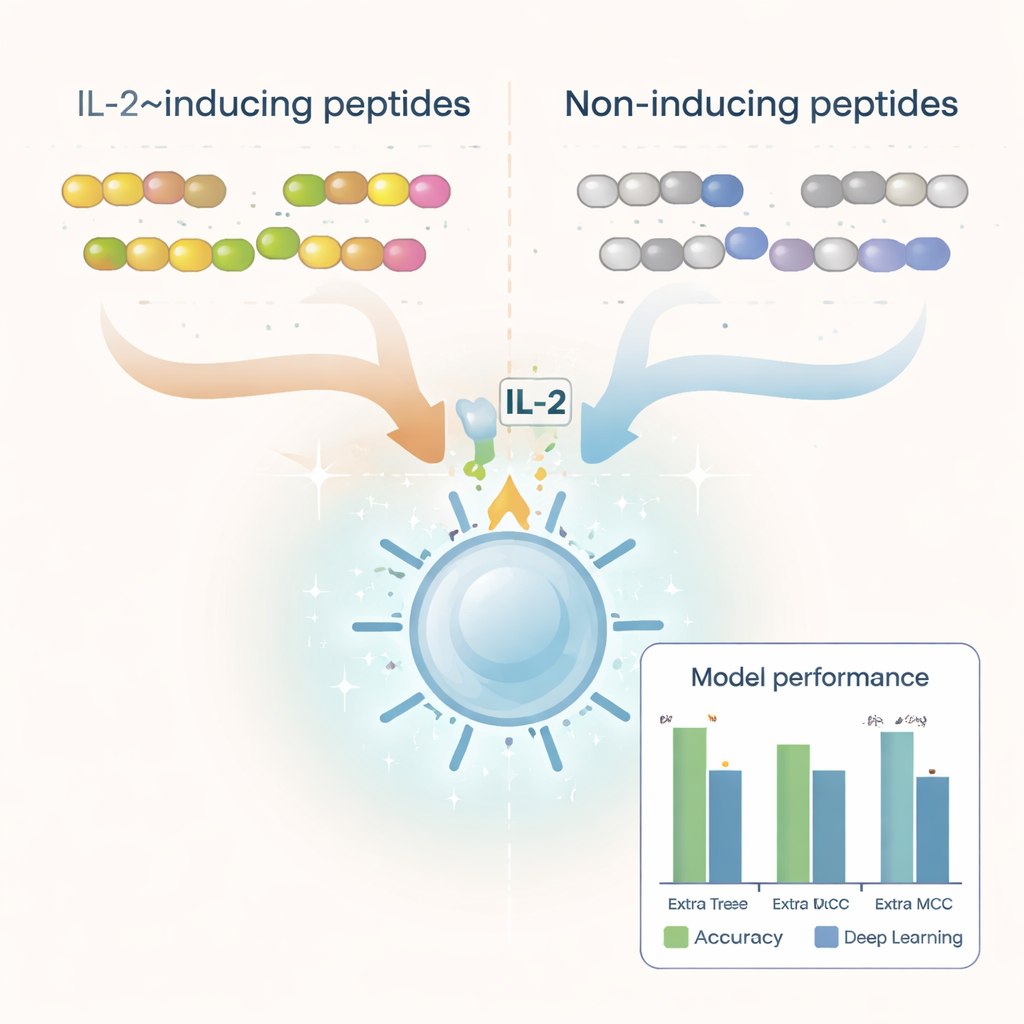
Die Forschenden begannen mit Tausenden von Peptidsequenzen, die bereits im Labor getestet und als IL‑2‑induzierend oder nicht klassifiziert worden waren. Sie bereinigten den Datensatz, entfernten Duplikate, ungewöhnliche Bausteine sowie Peptide, die zu kurz oder zu lang waren, und blieben so bei über 6.000 gut charakterisierten Beispielen. Durch die Analyse der Bausteine (Aminosäuren), aus denen diese Peptide bestehen, zeigten sich klare Unterschiede zwischen den beiden Gruppen. IL‑2‑induzierende Peptide wiesen tendenziell einen höheren Anteil an hydrophoben, also wasserabweisenden, Aminosäuren wie Leucin und Alanin auf, während nicht‑induzierende Peptide eher polare und geladene Reste enthielten. Bestimmte kurze Muster oder Motive, etwa „LEGS“ und „ALEG“, traten ausschließlich in IL‑2‑induzierenden Peptiden auf und deuten auf strukturelle Signaturen hin, die die Immunaktivierung begünstigen könnten.
Mashines trainieren, immunstärkende Muster zu erkennen
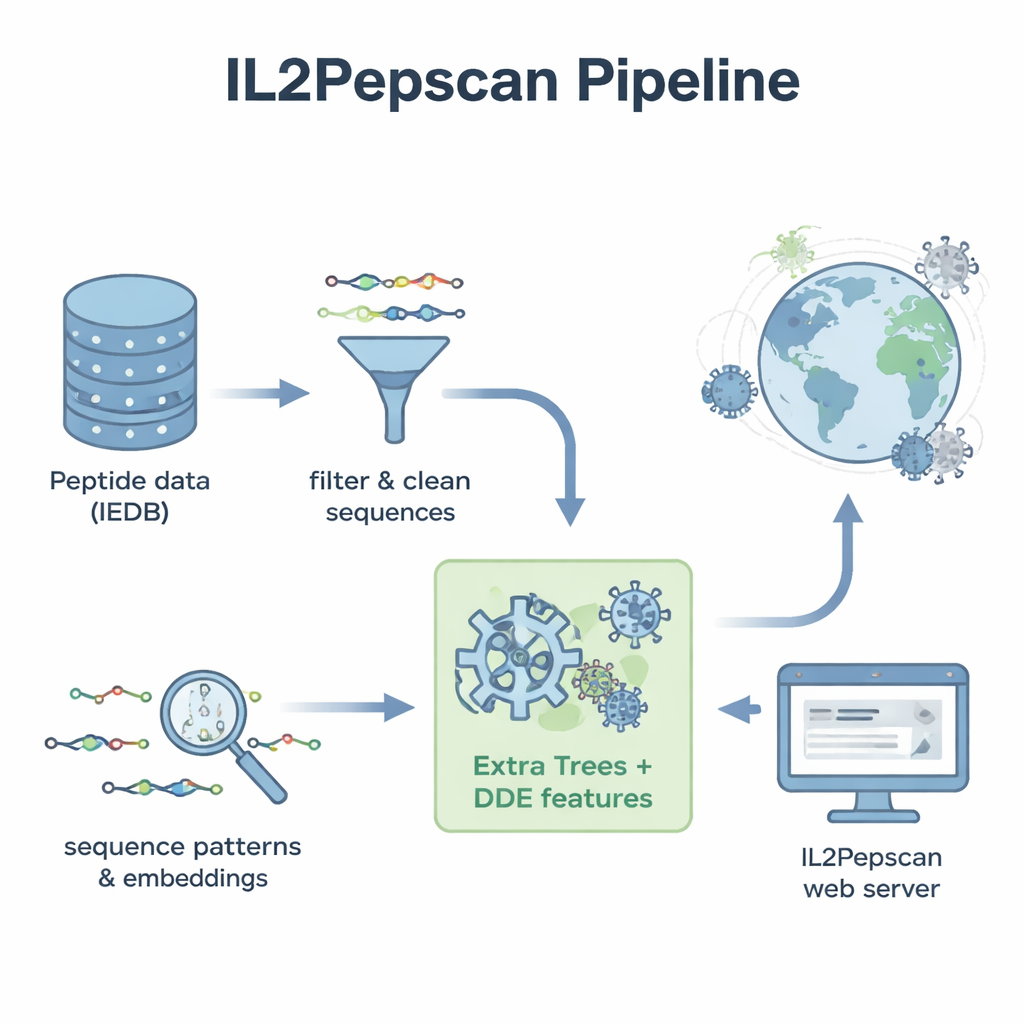
Um diese Muster in ein praktisches Vorhersagewerkzeug zu überführen, wandelte das Team jedes Peptid in numerische Beschreibungen um, die dessen Zusammensetzung und die Reihenfolge der Aminosäuren erfassen. Sie testeten eine Reihe von Machine‑Learning‑Methoden – darunter verbreitete Algorithmen wie Random Forests, Support‑Vector‑Machines und Boosted Trees – sowie Deep‑Learning‑Architekturen, die häufig für Sprach‑ und Bildaufgaben genutzt werden. Außerdem nutzten sie ein großes Protein‑»Sprachmodell« namens ProtBERT, das ursprünglich auf Hunderten Millionen Proteinsequenzen trainiert wurde, und passten es fein ab, um IL‑2‑relevante Signale besser zu erkennen. Nach umfangreichen Tests mit Kreuzvalidierung und einem unabhängigen Testsatz erwies sich ein Modell namens Extra Trees in Kombination mit einem Merkmalsset namens Dipeptide Deviation from Expected Mean (DDE) als Spitzenreiter. Dieses Modell erreichte knapp 80 % Genauigkeit und eine starke Korrelationsbewertung und übertraf damit mehrere Deep‑Learning‑Ansätze.
Die virale Welt nach versteckten Immuntriggern absuchen
Mit ihrem besten Modell warfen die Autorinnen und Autoren ein viel größeres Netz aus. Sie sammelten Referenzproteinsequenzen von mehr als 14.000 Viren, zerschnitten diese Proteine in etwa 156 Millionen überlappende Peptide und ließen das Modell vorhersagen, welche davon IL‑2 induzieren könnten. Unter den bestbewerteten Kandidaten fanden sich Peptide aus bekannten Virusfamilien, darunter Flaviviren wie West‑Nile, Zika, Gelbfieber und Hepatitis‑C‑Viren sowie aus Influenza und SARS‑CoV‑2. Viele vielversprechende Peptide stammten aus Virus‑Hüll‑ oder Nukleokapsidproteinen – denselben Proteinarten, von denen andere Studien gezeigt haben, dass sie in Tiermodellen IL‑2‑Antworten auslösen können. Das Modell markierte zudem potenzielle IL‑2‑induzierende Peptide, die von Bakteriophagen codiert werden, also Viren, die Bakterien infizieren, und deutet damit auf eine noch breitere Landschaft immunrelevanter Sequenzen hin.
Vom Algorithmus zum zugänglichen Werkzeug
Um ihre Arbeit über das Rechenlabor hinaus nutzbar zu machen, entwickelten die Autorinnen und Autoren einen öffentlichen Webserver namens IL2Pepscan. Forschende können Peptid‑ oder Proteinsequenzen in die Seite einfügen, um deren IL‑2‑induzierendes Potenzial abzuschätzen, neue Varianten durch gezielte Mutationen zu entwerfen, ganze Proteine nach Hotspots zu durchsuchen oder nach bekannten IL‑2‑verknüpften Motiven zu suchen. Zwar bestätigt die Studie nicht experimentell jedes einzelne vorhergesagte Peptid, doch die Übereinstimmung mit bestehenden Laborbefunden legt nahe, dass IL2Pepscan zuverlässig die Kandidatenauswahl für weitere Tests einschränken kann. Für Nicht‑Fachleute lautet die Kernaussage: Gut trainierte Algorithmen können riesige biologische Datensätze durchsieben und kleine Proteinfragmente identifizieren, die eines Tages Impfstoffe und Immuntherapien helfen könnten, das Immunsystem kraftvoller – und präziser – zu lenken.
Zitation: Arora, P., Abhigyan, R., Periwal, N. et al. IL2Pepscan: A machine learning framework for predicting IL-2 inducing peptides and their identification across global viral proteomes. Sci Rep 16, 6701 (2026). https://doi.org/10.1038/s41598-026-35977-6
Schlüsselwörter: Interleukin‑2, Peptidimpfstoffe, Machine Learning, virales Proteom, Immuntherapie