Clear Sky Science · de
Die multiparameter-optimierte Belief-Rule-Base zur Vorhersage von Schülerleistungen mit Interpretierbarkeit
Warum die Notenvorhersage uns alle angeht
Zeugnisse wirken vielleicht einfach, doch die Kräfte, die die Noten eines Schülers formen, sind alles andere als trivial. Schulen greifen zunehmend auf Computermodelle zurück, um frühzeitig gefährdete Schüler zu erkennen und Unterstützung zu steuern. Viele dieser Modelle sind jedoch „Black Boxes“: sie können genau sein, aber selbst Lehrkräfte und Eltern sehen nicht, warum eine Vorhersage getroffen wurde. Dieser Artikel stellt einen neuen Ansatz vor, der sowohl hohe Genauigkeit als auch gute Nachvollziehbarkeit anstrebt, damit Pädagogen den Ergebnissen vertrauen und darauf reagieren können.
Ein klügerer Weg, Signale zu lesen
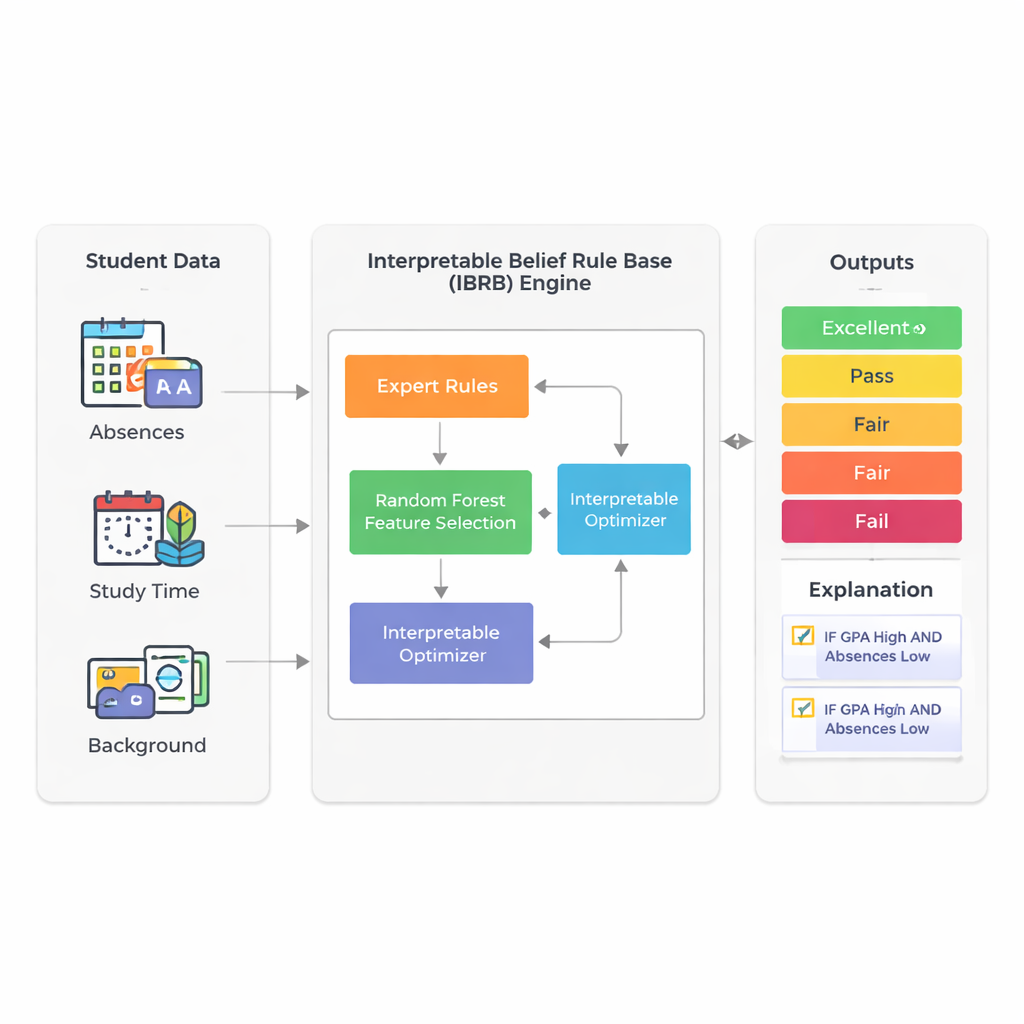
Die Studie konzentriert sich darauf, wie gut sich die endgültige Leistung von Schülern vorhersagen lässt, indem die bereits von Schulen gesammelten Informationen genutzt werden: Notendurchschnitt (GPA), Fehlzeiten, Lernzeit, Hintergrund sowie familiäre und außerunterrichtliche Aktivitäten. Statt sich auf undurchsichtige Deep-Learning-Systeme zu verlassen, bauen die Autorinnen und Autoren auf einer Technik namens Belief-Rule-Base auf. In diesem Rahmen formulieren Expertinnen und Experten Regeln, die dem ähneln, was eine Lehrkraft sagen würde: „Wenn der GPA hoch und die Fehlzeiten gering sind, dann wird der Schüler wahrscheinlich gute Leistungen erbringen.“ Jede Regel trägt einen Grad an Überzeugung für mögliche Ergebnisse wie Excellent, Good, Pass, Fair oder Fail. Dadurch wird der Schlussprozess sichtbar und prinzipiell auch für Nicht-Expertinnen und Nicht-Experten erklärbar.
Komplexität zähmen, Bedeutung bewahren
Ein großes Problem bei regelbasierten Systemen ist, dass sie außer Kontrolle geraten können, sobald viele Schülermerkmale einbezogen werden: jeder zusätzliche Faktor vervielfacht die möglichen Regeln. Um diese „Regel-Explosion“ zu vermeiden, nutzen die Forschenden zunächst einen Random Forest — ein weit verbreitetes Ensemble aus Entscheidungsbäumen —, um zu messen, welche Merkmale für die Vorhersage der Leistung am wichtigsten sind. In ihrem realen Datensatz mit 2.392 Schülern aus einer öffentlichen Quelle machen GPA und Fehlzeiten etwa 73 % der Vorhersagekraft des Modells aus. Indem sie bewusst nur diese beiden Eingaben beibehalten, bleibt das endgültige Modell kompakt und leichter interpretierbar, erfasst aber trotzdem den Großteil der Variation bei den Schülerergebnissen.
Regeln entwickeln, denen Menschen folgen können
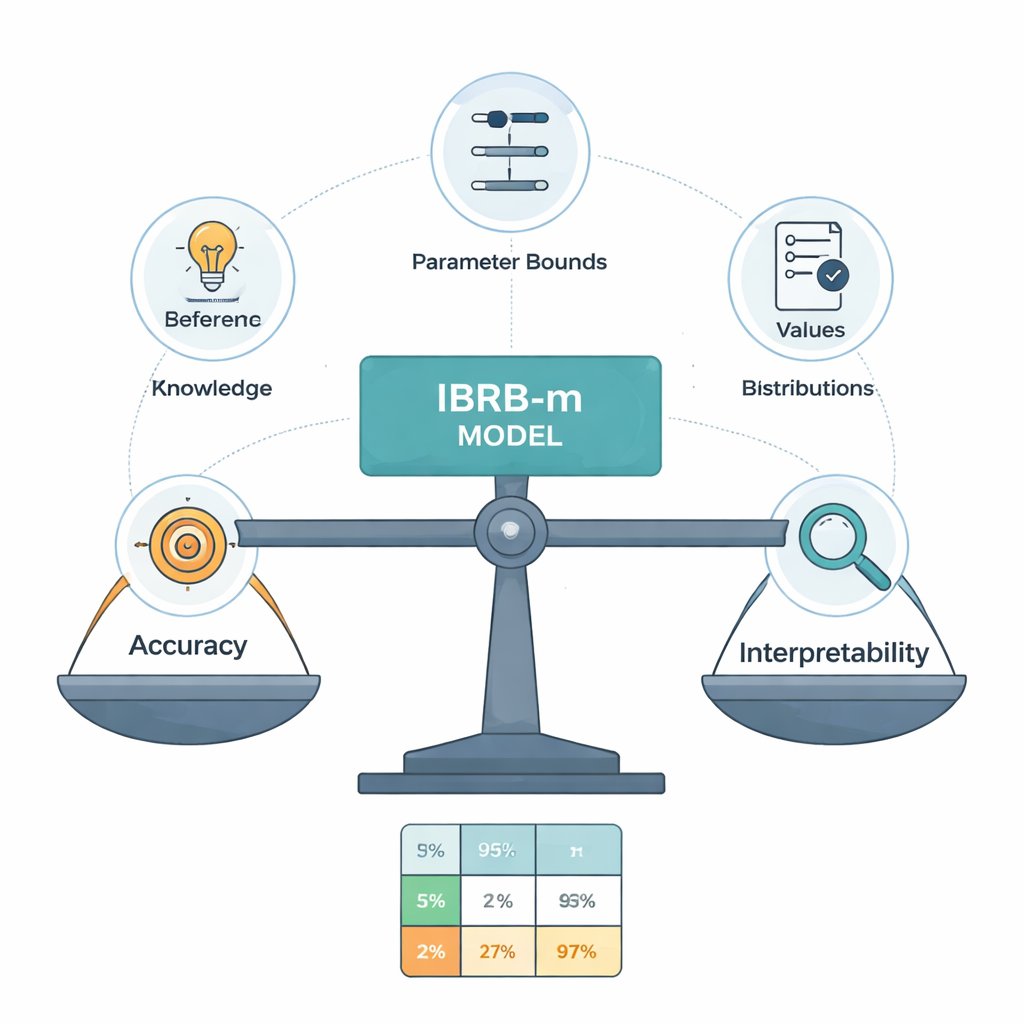
Der Kern des neuen Modells, genannt IBRB-m, ist ein sorgfältig strukturiertes Regelwerk aus 25 Regeln, die GPA- und Fehlzeitenstufen mit Überzeugungsgraden für die fünf Leistungskategorien kombinieren. Die Autorinnen und Autoren formalisieren, was es bedeutet, dass ein solches Modell „interpretierbar“ ist. Zu ihren Anforderungen gehören: Jede Referenzstufe (etwa „niedriger GPA“) muss einen klaren und unterscheidbaren Bereich abdecken; die Regelbasis muss alle realistischen Kombinationen von Eingaben abdecken; Parameter wie Regelgewichte und Attributgewichte müssen anschauliche Bedeutungen haben; und die internen Berechnungen des Systems müssen Informationen auf transparente, mathematisch konsistente Weise transformieren. Zusätzlich zu diesen traditionellen Bedingungen fügen sie bildungsspezifische Leitlinien hinzu, die erzwingen, dass die Modellvorhersagen vernünftigen, alltäglichen Mustern folgen — zum Beispiel um absurde Fälle zu vermeiden, in denen ein Schüler gleichzeitig sehr wahrscheinlich exzellent und durchfallgefährdet eingeschätzt wird.
Daten das Expertenwissen feinjustieren lassen
Menschenexpertinnen und -experten sind nicht immer einer Meinung, und ihre anfänglichen Regeln können ungenau sein. Um diese Regeln zu verfeinern, ohne das Modell wieder in eine Black Box zu verwandeln, entwickeln die Autorinnen und Autoren einen verbesserten Optimierungsalgorithmus, der nach besseren Parameterwerten sucht und gleichzeitig strenge Interpretierbarkeitsbeschränkungen einhält. Dieser Algorithmus passt nicht nur Regelgewichte und Überzeugungsgrade an, sondern auch die Grenzwerte, die Kategorien wie Excellent oder Pass definieren. Er hält alle Änderungen innerhalb von von Expertinnen und Experten genehmigten Grenzen und erzwingt vernünftige, glatte Überzeugungsmuster über die Noten hinweg. Effektiv „stößt“ der Computer das Expertensystem zu höherer Genauigkeit, darf aber keine Regeln erfinden, die eine sachkundige Lehrkraft verwirren würden.
Wie gut funktioniert das in der Praxis?
Getestet am Kaggle-Datensatz zur Schülerleistung sagt das IBRB-m-Modell die endgültigen Leistungsstufen in mehr als 99 % der Fälle korrekt voraus und übertrifft damit sowohl frühere Belief-Rule-Systeme als auch gängige Machine-Learning-Werkzeuge wie neuronale Netze, Random Forests und k-Nearest Neighbors. Ebenso wichtig ist, dass die optimierten Regeln beim Vergleich mit einem einfachen Distanzmaß nahe an den ursprünglichen Expertenbewertungen bleiben, was bedeutet, dass sich die Begründung jeder Vorhersage weiterhin zurückverfolgen und rechtfertigen lässt. Kreuzvalidierungen über mehrere Datenaufteilungen zeigen, dass die Modellleistung stabil ist und kein Zufall einer günstigen Partition darstellt.
Was das für den Unterricht bedeutet
Für nicht fachkundige Leserinnen und Leser ist die wichtigste Erkenntnis, dass Vorhersageinstrumente für Schüler sowohl leistungsfähig als auch verständlich sein können. Statt rätselhafter Risikowerte kann das Modell konkrete Muster hervorheben wie „mäßiger GPA, aber häufige Fehlzeiten“ und zeigen, wie diese in eine Einschätzung wie Fair oder Fail eingehen. Lehrkräfte und Beratende können dann mit gezielten Maßnahmen reagieren — etwa Unterstützung bei der Anwesenheit oder Coaching zu Lernstrategien — und gleichzeitig Schülerinnen und Schülern sowie Eltern sicher erklären, warum das Modell zu dieser Schlussfolgerung gelangte. Die Autorinnen und Autoren argumentieren, dass diese Kombination aus Genauigkeit und Transparenz entscheidend ist, damit datengetriebene Systeme eine vertrauenswürdige Rolle bei der Förderung einer fairen und effektiven Bildung spielen können.
Zitation: Li, J., Zhou, W., Jiang, S. et al. The multi-parameter optimized belief rule base for predicting student performance with interpretability. Sci Rep 16, 5772 (2026). https://doi.org/10.1038/s41598-026-35950-3
Schlüsselwörter: Vorhersage von Schülerleistungen, interpretierbare KI, Belief-Rule-Base, Educational Data Mining, Erklärbares maschinelles Lernen