Clear Sky Science · de
HEViTPose: hin zu hochgenauer und effizienter 2D-Mensch-Pose-Schätzung mit kaskadierender gruppenweiser räumlicher Reduktions-Attention
Computern beibringen, Körpersprache zu lesen
Von Fitness-Apps bis zu Fahrerassistenzsystemen verlassen sich viele Technologien inzwischen darauf, dass ein Computer versteht, wie sich Menschen bewegen. Diese Fähigkeit, genannt Mensch‑Pose‑Schätzung, besteht darin, die Positionen von Gelenken—wie Schultern, Knien und Knöcheln—in einem Bild oder Video zu finden. Die Herausforderung ist, dies sowohl genau als auch schnell genug für die Echtzeitnutzung auf alltäglicher Hardware zu tun. Dieses Papier stellt HEViTPose vor, eine neue Methode, die darauf abzielt, hohe Genauigkeit beizubehalten und dabei weniger Rechenleistung zu benötigen als viele aktuelle Systeme.
Warum das Finden von Gelenken in Bildern so schwierig ist
Auf den ersten Blick mag das Lokalisieren von Gelenken einfach erscheinen: man suche nach Armen und Beinen. In der Praxis treten Menschen jedoch in unterschiedlichen Größen, ungewöhnlichen Posen, in überfüllten Szenen und oft hinter Objekten wie Möbeln oder Autos auf. Moderne Pose‑Schätzsysteme erzeugen hierfür meist für jedes Gelenk eine detaillierte „Heatmap“, in der helle Bereiche wahrscheinliche Positionen markieren. Heatmaps sind sehr präzise, aber rechenintensiv. Traditionelle Systeme setzen überwiegend auf Convolutional Neural Networks, die gut darin sind, lokale Muster zu erkennen, aber immer tiefer und schwerer werden müssen, um fernere Beziehungen über den ganzen Körper zu erfassen. Neuere transformer‑basierte Modelle glänzen beim Einfangen solcher Langstrecken‑Beziehungen, benötigen aber oft große Datensätze und viel Rechenaufwand, was ihren Einsatz in Echtzeit oder auf kleineren Geräten erschwert.
Überlappende Ausschnitte für flüssigere Wahrnehmung
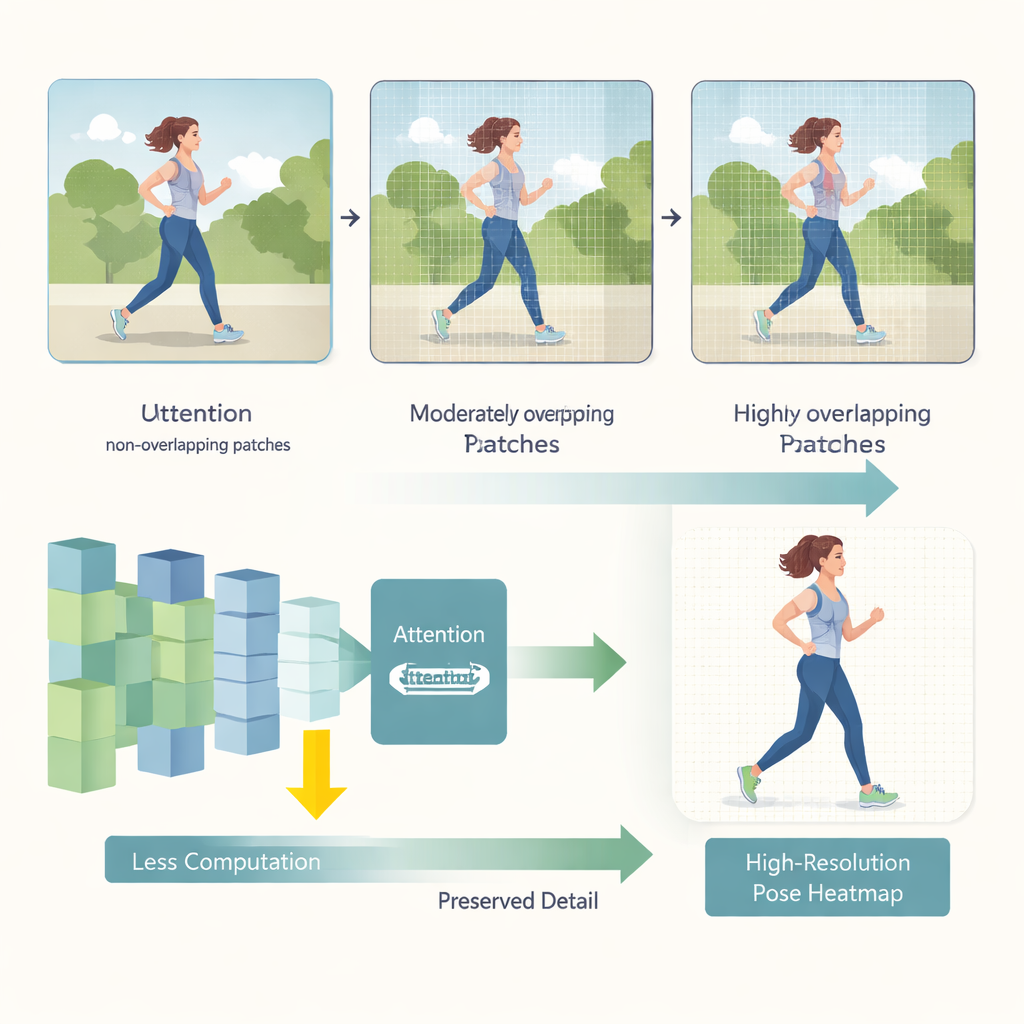
HEViTPose beginnt damit, neu zu denken, wie ein Bild in Teile zerlegt wird, die analysiert werden. Frühere Transformer‑Modelle zerteilten Bilder häufig in nicht überlappende Kacheln, wodurch die visuelle Kontinuität zwischen benachbarten Regionen gestört werden kann—ähnlich dem Abschneiden eines Arms an der Kachelgrenze. HEViTPose baut auf der Idee der überlappenden Patch‑Einbettung auf und führt eine klarere, einstellbare Größe namens Patch Embedding Overlap Width (PEOW) ein. PEOW zählt einfach, wie viele Pixel benachbarte Kacheln entlang ihrer Ränder teilen. Durch systematisches Variieren dieser Überlappung zeigen die Autoren, dass moderate Überlappung dem Netzwerk erlaubt, den sanften Übergang von Farbe und Form zwischen Kacheln besser „zu spüren“. Diese reichere lokale Kontinuität führt zu genaueren Gelenkpositionen, ohne die Modellgröße oder den Rechenaufwand in die Höhe zu treiben.
Klügere Attention bei geringerem Aufwand
Die zweite wichtige Innovation ist ein neues Attention‑Modul namens Cascaded Group Spatial Reduction Multi‑Head Attention (CGSR‑MHA). Attention‑Mechanismen sagen dem Netzwerk, welche Bildteile jede Vorhersage beeinflussen sollten, skaliert aber typischerweise schlecht, wenn Bilder größer werden. CGSR‑MHA begegnet dem auf drei Arten. Erstens teilt es Merkmale in Gruppen auf, sodass jede Gruppe nur einen Teil der Informationen verarbeitet, statt alles auf einmal. Zweitens reduziert es die räumliche Auflösung innerhalb jeder Gruppe, bevor Attention berechnet wird, was die Anzahl der Operationen stark vermindert. Drittens verwendet es mehrere kleine Attention‑Heads statt weniger großer, wodurch die Vielfalt dessen, worauf das Modell „achten“ kann, erhalten bleibt, während die Kosten niedrig bleiben. Sorgfältig gewählte Einstellungen für Gruppenzahl, Reduktionsstärke und Anzahl der Heads finden ein Gleichgewicht zwischen Geschwindigkeit und Genauigkeit.
Leichte Modelle, die trotzdem an der Spitze mitspielen
Um HEViTPose zu testen, bewerten die Autoren es auf zwei weit verbreiteten Benchmarks: dem MPII‑Datensatz für alltägliche menschliche Aktivitäten und dem größeren COCO‑Datensatz mit Personen in vielen verschiedenen Szenen. Über mehrere Modellgrößen hinweg erreicht HEViTPose die Genauigkeit führender Pose‑Schätzsysteme oder kommt ihr sehr nahe, während es deutlich weniger Parameter und Rechenaufwand benötigt. Beispielsweise erzielt eine Version eine ähnliche Genauigkeit wie ein populäres hochauflösendes Netzwerk (HRNet), reduziert dabei die Anzahl der gelernten Parameter um mehr als 60 % und den Rechenaufwand um über 40 %. Im Vergleich zu einem modernen Hybridmodell, das Convolutions und Transformer mischt, liefert HEViTPose ähnliche Leistung, läuft auf einer Grafikkarte jedoch etwa 2,6‑mal schneller. Diese Einsparungen führen direkt zu flüssigerer Echtzeitperformance und geringeren Hardwareanforderungen.
Was das für alltägliche Anwendungen bedeutet
Einfach ausgedrückt zeigt HEViTPose, dass man sich beim Lehren von Computern, Körpersprache zu lesen, nicht zwischen Genauigkeit und Effizienz entscheiden muss. Durch die gezielte Überlappung der betrachteten Bildteile und die Neugestaltung, wie Attention innerhalb des Netzwerks berechnet wird, kann das System Gelenke mit hoher Präzision lokalisieren und zugleich kompakt und schnell bleiben. Das macht es attraktiv für reale Anwendungen wie Sport‑Tracking, Videoüberwachung, Mensch‑Roboter‑Interaktion und Fahrzeug‑Innenraumüberwachung, wo sowohl Geschwindigkeit als auch Energieverbrauch wichtig sind. Die Ideen hinter HEViTPose—intelligentere Überlappung und effiziente Attention—könnten auch auf verwandte Aufgaben wie Tier‑Pose‑Tracking oder Gesichtslandmarkenerkennung übertragen werden und so vielen Geräten schärfere „digitale Augen“ ermöglichen, ohne Supercomputer‑Hardware zu benötigen.
Zitation: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
Schlüsselwörter: Menschen-Pose-Schätzung, Computer Vision, Vision Transformer, effizientes Deep Learning, Attention-Mechanismus