Clear Sky Science · de
Ein hybrides CNN- und Reinforcement-Learning-Framework zur Sprecheridentifikation unter Verwendung von Mel-Spectrogramm- und kontinuierlichen Wavelet-Transformationsmerkmalen
Warum Ihre Stimme ein digitaler Schlüssel sein kann
Stellen Sie sich vor, Sie entsperren Ihr Bankkonto, Ihre Haustür oder Ihr Telefon nur mit Ihrer Stimme. Damit das sicher funktioniert, müssen Computer zuverlässig eine Person von einer anderen unterscheiden können – selbst bei Hintergrundgeräuschen, emotionaler Sprechweise oder schlechtem Mikrofon. Dieses Paper untersucht einen neuen Ansatz, Maschinen beizubringen, wer spricht, nicht nur was gesagt wird, indem moderne Deep-Learning-Techniken mit einer Form des Trial-and-Error-Lernens aus der Robotik kombiniert werden.
Von Schallwellen zu Stimm-Fingerabdrücken
Die Stimme jeder Person trägt subtile Hinweise, geformt durch Größe und Form des Vokaltrakts, die Vibration der Stimmlippen und den sprecherbezogenen Stil. Die Forschenden fragten zunächst: Welche messbaren Eigenschaften aufgezeichneter Sprache unterscheiden sich tatsächlich zwischen Personen? Mit 2.703 Audioclips von 40 englischen Sprechern aus dem LibriSpeech-Datensatz analysierten sie 22 einfache akustische Merkmale, etwa Lautstärkevariationen, Energie in verschiedenen Frequenzbändern, Rhythmus und ein Maß namens Entropie, das erfasst, wie komplex oder unvorhersehbar der Klang ist. Statistische Tests zeigten, dass 21 dieser 22 Merkmale starke sprecherspezifische Informationen tragen; besonders auffällig waren Entropie und Energie im Hochfrequenzbereich. Anders gesagt: Der „Stimm-Fingerabdruck“ einer Person verteilt sich auf viele Klangaspekte, nicht nur Tonhöhe oder Lautstärke.
Zwei Wege, Klang in Bilder zu verwandeln
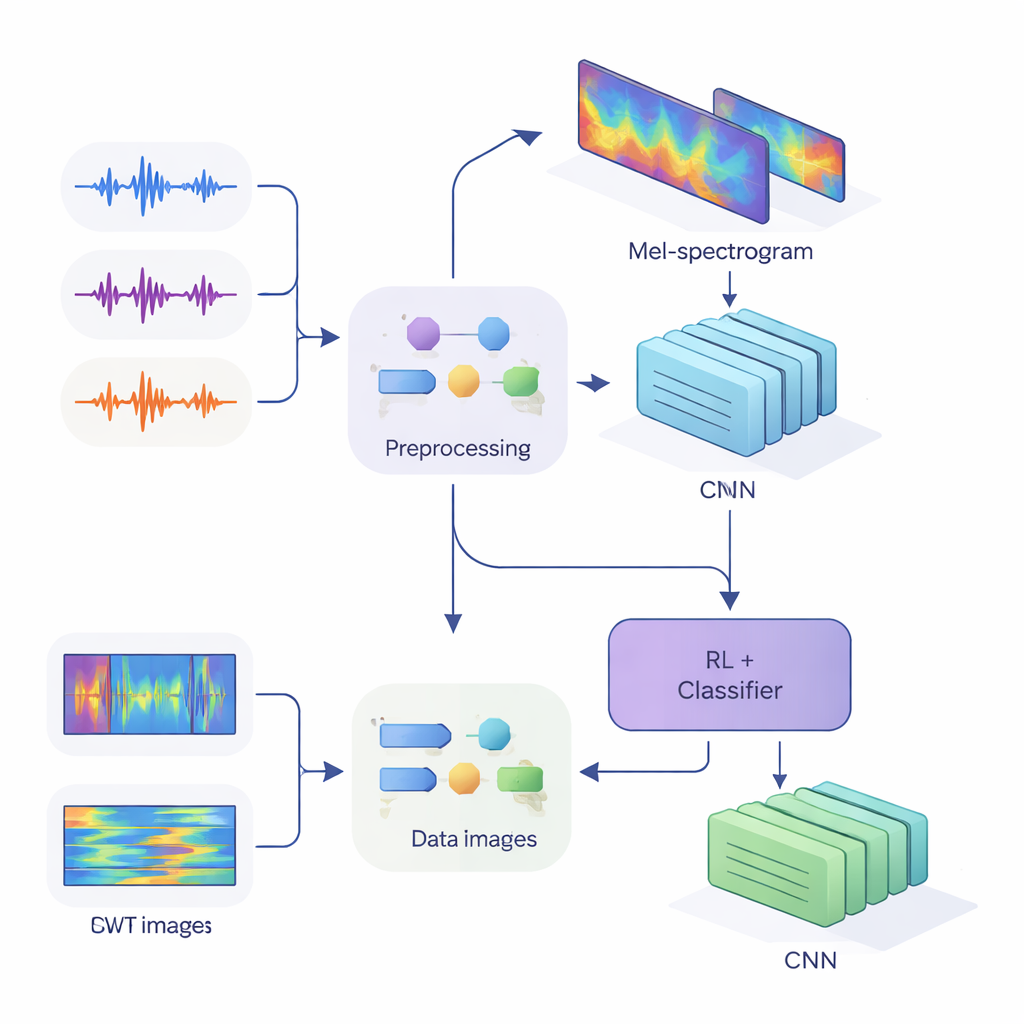
Um diese Hinweise modernen neuronalen Netzen zuzuführen, wandelte das Team eindimensionale Audiosignale in zweidimensionale Bilder um, die zeigen, wie sich Energie über Zeit und Frequenz verändert. Im ersten Verfahren verwendeten sie Mel-Spektrogramme, die nachahmen, wie das menschliche Ohr Frequenzen gruppiert und in der Sprachtechnologie üblich sind. Im zweiten Verfahren setzten sie kontinuierliche Wavelet-Transformationen ein, eine flexiblere Methode, um sowohl kurze, scharfe Geräusche als auch längere Vokale zu erfassen. Nach sorgfältiger Bereinigung der Audiodaten – Entfernen von Stille, Standardisierung der Lautstärke und Hinzufügen kleiner Verzerrungen wie Rauschen und Tonhöhenverschiebungen zur Robustheit – erzeugten sie Mel-“Bilder” in der Größe 80×313 und Wavelet-“Bilder” in der Größe 128×128, bereit für die Verarbeitung durch Convolutional Neural Networks (CNNs).
Netze beibringen zuzuhören und zu zweifeln
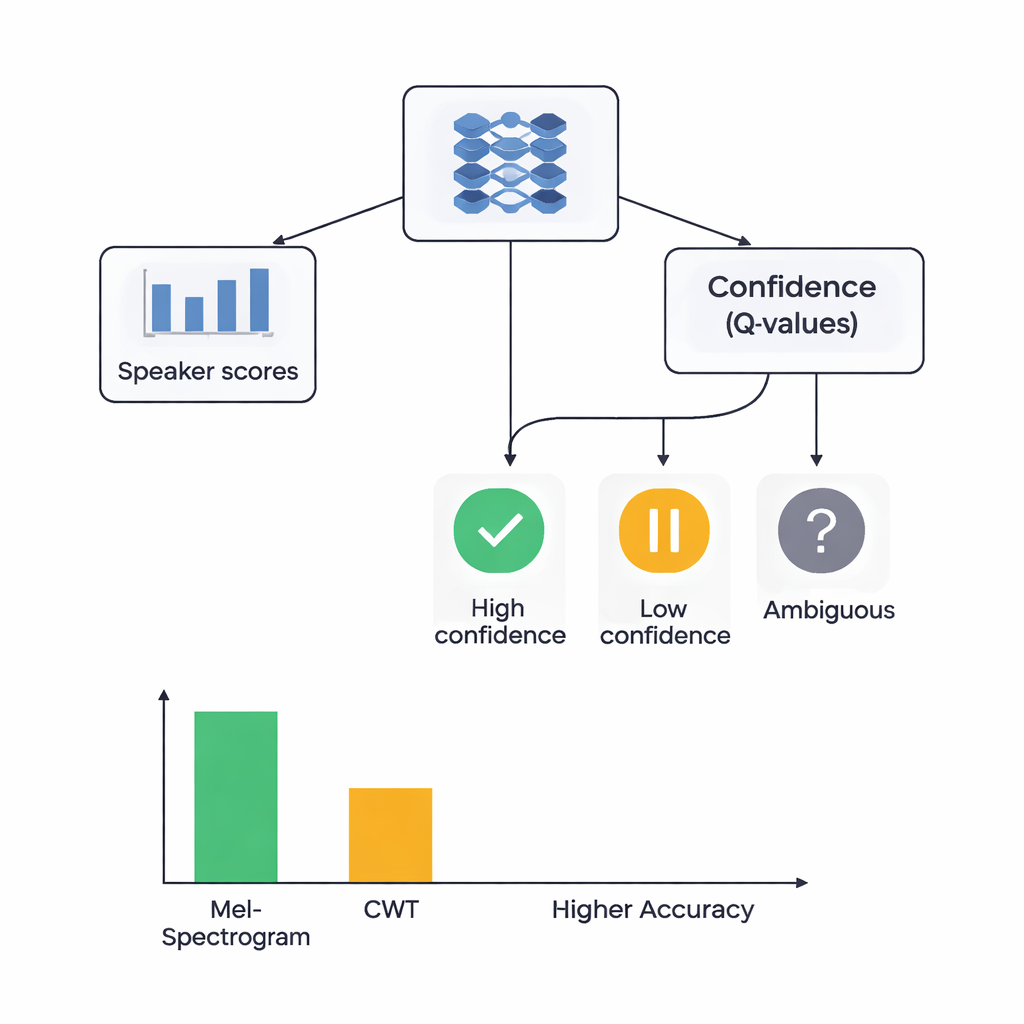
Kern der Studie ist eine hybride Architektur, die zwei Lernparadigmen verbindet. Zuerst scannen CNNs die Mel- oder Wavelet-Bilder, um Muster zu extrahieren, die typischerweise zu bestimmten Sprechern gehören – ähnlich wie Bild-Erkennungsnetze Augen oder Kanten lernen zu erkennen. Beim Mel-basierten System fügen die Autoren ein Self-Attention-Modul hinzu, das dem Netzwerk erlaubt, sich auf die informativsten Zeitsegmente zu konzentrieren. Auf diesen Merkmalsextraktoren liegt eine Reinforcement-Learning-(RL-)Komponente, die lernt, wie sicher das System bei jeder Entscheidung sein sollte. Statt immer eine harte Entscheidung zu treffen, weist der RL-Teil Aktionen Werte zu wie „als sichere Vermutung akzeptieren“, „als geringe Sicherheit behandeln“ oder „als unklar markieren“. Über viele Trainingsrunden wird er belohnt, wenn sichere Entscheidungen korrekt sind, was das Netzwerk zu besser kalibrierten Urteilen hinführt.
Wie gut funktioniert das hybride System?
Die Forschenden verglichen vier Modelle: Mel-basiert mit RL, Mel-basiert ohne RL, Wavelet-basiert mit RL und Wavelet-basiert ohne RL. Getestet wurden sie mittels sorgfältiger Fünf-Fach-Cross-Validierung, sodass jeder Audioclip in verschiedenen Durchgängen sowohl zum Trainieren als auch zum Testen diente. Das Mel-plus-RL-System erzielte die besten Ergebnisse: Es identifizierte den Sprecher in etwa 88 % der Fälle korrekt und zeigte laut einem Standardmaß für Diskriminationskraft eine nahezu perfekte Trennung zwischen Sprechern. Das Wavelet-plus-RL-System erreichte rund 78 % Genauigkeit. Entscheidend ist, dass die Hinzunahme der RL-Komponente die Leistung bei beiden Feature-Typen um etwa 3 Prozentpunkte verbesserte und die Ergebnisse über unterschiedliche Datenaufteilungen konsistenter machte. Mehr Sprecherklassen erzielten hohe Erkennungsqualität, wenn RL einbezogen war, was darauf hindeutet, dass die vertrauensbewussten Entscheidungen besonders bei schwer zu unterscheidenden, leicht verwechselbaren Stimmen halfen.
Was das für alltägliche Sprachsicherheit bedeutet
Für Nicht‑Fachleute lautet die zentrale Erkenntnis, dass zuverlässige sprachbasierte Identitätsprüfungen sowohl reichhaltige Repräsentationen des Klangs als auch ein gesundes Maß an Zweifel seitens der Maschine erfordern. Diese Arbeit zeigt, dass ohr‑inspirierten Mel-Spektrogramme, kombiniert mit Attention und einem Reinforcement-Learner, der „Ich bin mir nicht sicher“ sagen kann, für die Aufgabe, Sprecher zu unterscheiden, besser abschneiden als die exotischeren Wavelet-Bilder. Obwohl die Studie einen relativ kleinen, sauberen Datensatz verwendet und noch nicht auf laute, reale Umgebungen zugeschnitten ist, demonstriert sie, dass das Hinzufügen einer vertrauensbewussten Ebene über tiefen neuronalen Netzen Sprach-Authentifizierung sowohl genauer als auch vertrauenswürdiger machen kann – ein wichtiger Schritt, wenn unsere Stimmen zu sicheren digitalen Schlüsseln werden sollen.
Zitation: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
Schlüsselwörter: Sprecheridentifikation, Stimmenbiometrie, Deep Learning, Reinforcement Learning, Mel-Spektrogramme