Clear Sky Science · de
Ein allgemeiner Rahmen für adaptive nichtparametrische Dimensionsreduktion
Warum das Verkleinern großer Datenmengen wichtig ist
Das moderne Leben läuft auf Daten: medizinische Aufnahmen, Einkaufsverläufe im Internet, Fotos, Nachrichten‑Feeds und mehr. Jeder Datensatz kann Hunderte oder Tausende Messwerte enthalten, was Speicherung, Analyse oder selbst die Visualisierung erschwert. Wissenschaftler nutzen „Dimensionsreduktion“, um diese Komplexität in einfachere Darstellungen und Modelle zu komprimieren und dabei die wichtigen Muster zu erhalten. Die heute verbreiteten Werkzeuge erfordern jedoch oft viele manuelle Entscheidungen und mühsames Ausprobieren. Dieses Papier stellt eine Methode vor, die die Entscheidung, wie stark komprimiert werden soll, dem Datensatz selbst überlässt, mit dem Ziel klarerer Darstellungen, präziserem Lernen und weniger Rätselraten für den Anwender.
Von einfachen Linien zu gekrümmten Realitäten
Ein klassisches Werkzeug zur Vereinfachung von Daten, die Hauptkomponentenanalyse, wirkt wie das Beleuchten eines Objekts und das Betrachten seines Schattens: Sie findet die besten flachen Richtungen, die den größten Teil der Variation erklären. Das ist leistungsfähig, wenn die Struktur der Daten ungefähr gerade oder flach ist. Reale Daten — etwa Bilder, Texte oder Sensormessungen — liegen jedoch häufig auf gekrümmten Flächen, die in hochdimensionalem Raum verborgen sind. In den letzten zwei Jahrzehnten wurden neue „nichtlineare“ Methoden wie Isomap, Locally Linear Embedding (LLE), spektrale Einbettung und UMAP entwickelt, um genau diese verschlungenen Formen zu entdecken. Sie bauen auf lokalen Nachbarschaften auf: Für jeden Punkt betrachten sie dessen nächste Nachbarn und versuchen, diese kleinmaßstäblichen Beziehungen beim Erstellen einer niedrigerdimensionalen Darstellung zu bewahren. Diese Methoden zwingen den Anwender jedoch, zwei wichtige Regler zu wählen: wie viele Nachbarn zu berücksichtigen sind und auf wie viele Dimensionen projiziert werden soll. Eine schlechte Wahl kann zu irreführenden oder rechenintensiven Ergebnissen führen.
Dem Datensatz selbst die Wahl der Nachbarschaft überlassen
Die Autoren bauen auf ein jüngeres statistisches Werkzeug auf, das eine Schätzung der intrinsischen Dimension liefert und die einfache Frage beantwortet: In wie vielen unabhängigen Richtungen variiert die Datenmenge wirklich, wenn Rauschen entfernt ist? Ihr Schätzer, ABIDE genannt, geht darüber hinaus. Um jeden Punkt herum sucht er automatisch nach einer Nachbarschaft, die einigermaßen homogen aussieht — weder zu klein und verrauscht noch zu groß und verzerrt. Dabei liefert er zwei Informationen: eine globale Schätzung der wahren Dimension der Daten und eine individuell angepasste Nachbarschaftsgröße für jeden Punkt. So wird die übliche feste „Anzahl von Nachbarn“ zu einer lokal adaptiven Größe, die in dünn besiedelten Bereichen wachsen und in dicht besiedelten schrumpfen kann und damit der tatsächlichen Dichtestruktur der Daten entspricht.
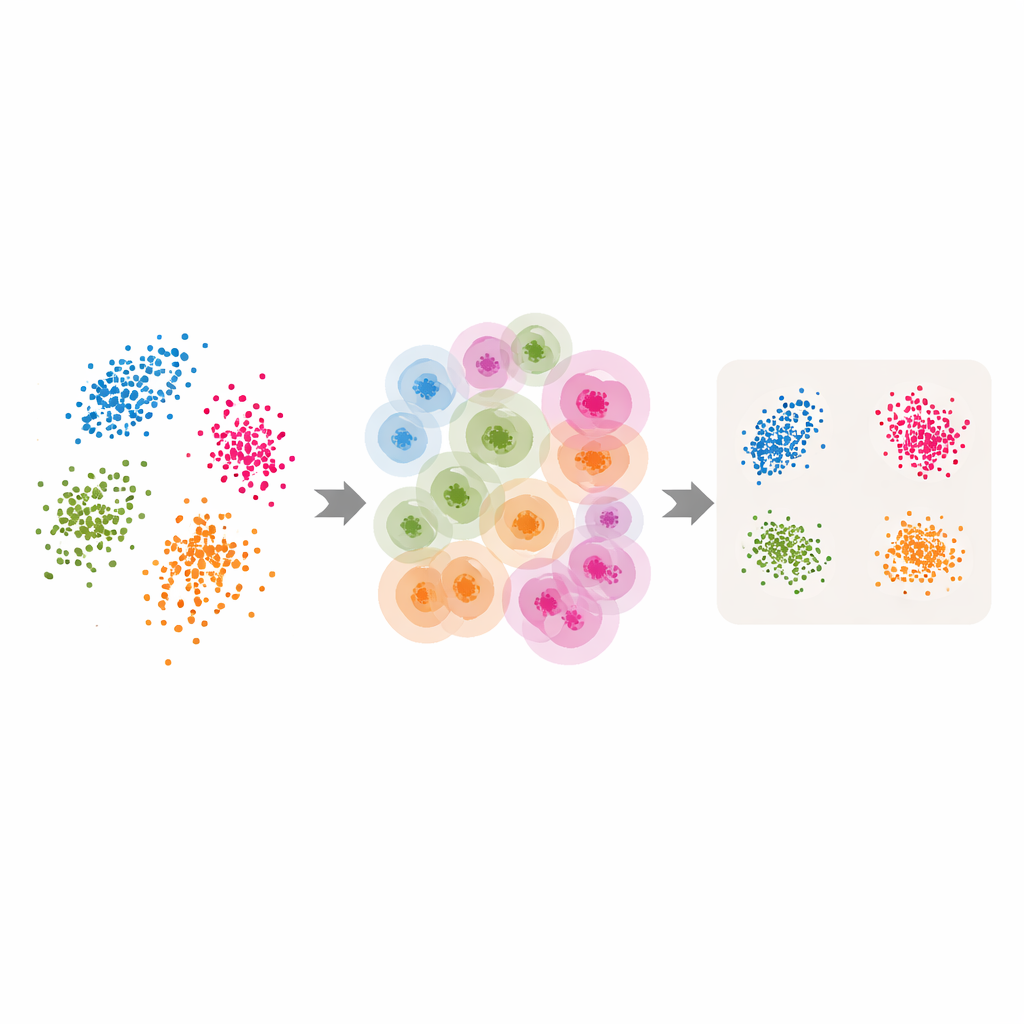
Klassische Werkzeuge in adaptive verwandeln
Mit diesen adaptiven Nachbarschaften und der geschätzten intrinsischen Dimension rüsten die Autoren mehrere populäre Methoden zur Dimensionsreduktion und zum Clustering nach. Für LLE ersetzen sie die einzelne, vom Anwender gewählte Nachbaranzahl durch die pro Punkt von ABIDE gelieferten Werte und setzen die Zieldimension gleich der geschätzten intrinsischen Dimension. Der Algorithmus lernt dann, jeden Punkt aus einer sorgfältig ausgewählten lokalen Gruppe zu rekonstruieren, bevor er eine globale niedrigdimensionale Anordnung findet, die diese lokalen Rekonstruktionen bestmöglich bewahrt. Ähnliche Ideen werden auf spektrales Clustering angewandt — bei dem ein Ähnlichkeitsgraph für die Gruppierung genutzt wird — und auf UMAP, das eine fuzzy Karte der Punktverbindungen erstellt. In jedem Fall wird die starre Nachbarschaftsgröße durch eine flexible, datengetriebene Struktur ersetzt, die der natürlichen Geometrie der Daten folgt.
Tests an Blumen, Ziffern, Texten und synthetischen Formen
Um zu prüfen, ob sich dieser adaptive Ansatz auszahlt, führen die Autoren Experimente auf mehreren Benchmark‑Datensätzen durch: den klassischen Iris‑Blütenmessungen, handschriftlichen Ziffernbildern (MNIST), Nachrichtenartikeln, dargestellt durch Sprachmodell‑Einbettungen, und synthetischen dreidimensionalen Formen mit zusätzlichem Rauschen. Sie vergleichen die adaptiven Versionen mit Standardsoftwareeinstellungen und mit sorgfältig abgestimmten Hyperparameter‑Gittern. In unüberwachten Aufgaben wie Clustering und Visualisierung liefern die adaptiven Methoden typischerweise klarere Cluster, dichtere Gruppierungen und bessere Werte bei gängigen Qualitätsmaßen. Auf komplexen Mannigfaltigkeiten mit ungleichmäßiger Punktdichte stellen die adaptiven Methoden beispielsweise die wahre Struktur deutlich besser wieder her als Versionen mit festen Nachbarn. In überwachten Tests, bei denen die reduzierten Daten in einen Klassifikator eingespeist werden, erreicht der adaptive Ansatz ebenfalls die Leistung der besten fixen Einstellungen oder übertrifft sie, ohne aufwändiges Tuning.
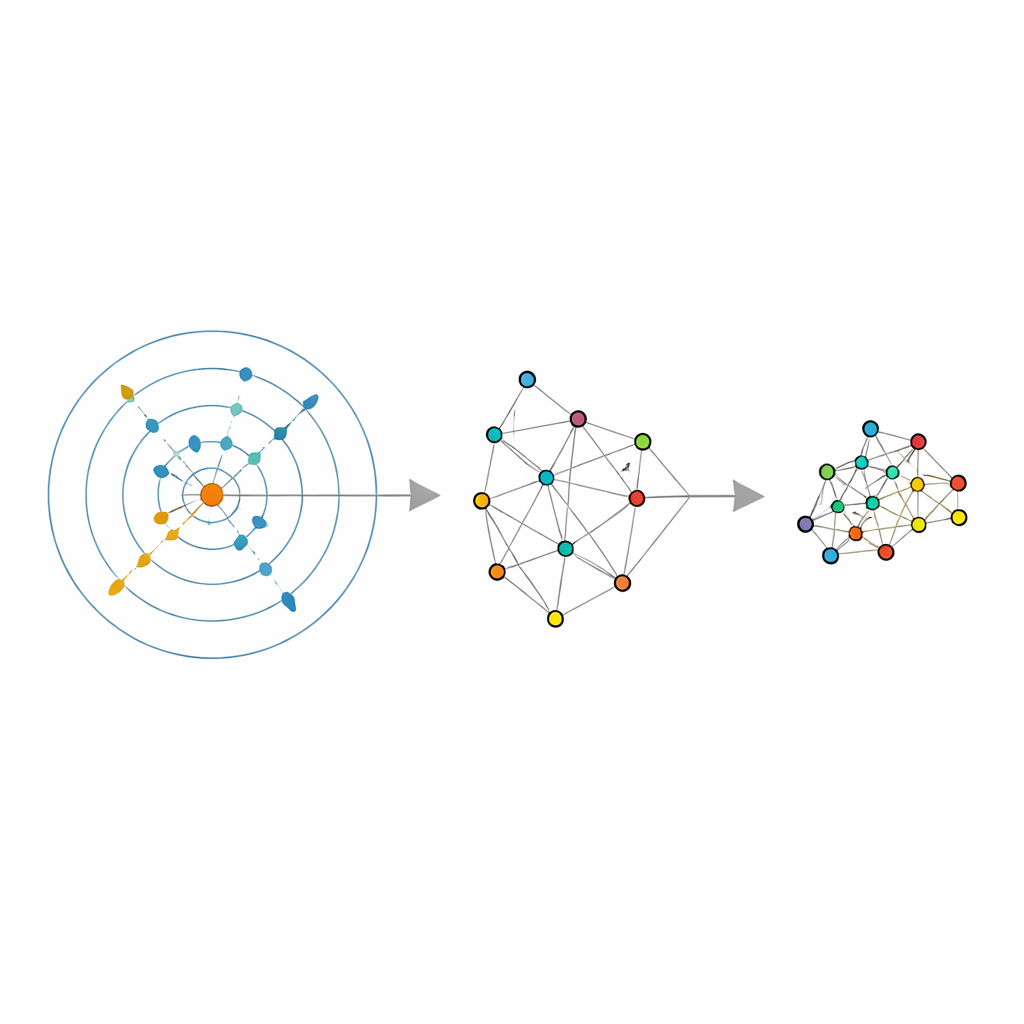
Was das für die alltägliche Datenanalyse bedeutet
Für Nicht‑Experten und Praktiker ist die Hauptaussage, dass das Verkleinern von Daten nicht vom Raten abhängen muss. Indem die Geometrie der Daten selbst über „wie viele Nachbarn“ und „wie viele Dimensionen“ entscheidet, verwandelt dieser Rahmen weit verbreitete Werkzeuge wie LLE, spektrales Clustering und UMAP in intelligentere, robustere Varianten. Das Ergebnis sind verlässlichere niedrigdimensionale Ansichten — Diagramme und Merkmale, die die wahre Form der Daten besser widerspiegeln — und oft eine Reduzierung der Zeit für manuelle Hyperparameter‑Suchen. Praktisch bedeutet das, dass Aufgaben wie die Visualisierung großer Bildsammlungen, das Gruppieren von Dokumenten oder das Vorbereiten von Eingabedaten für Vorhersagemodelle einfacher und verlässlicher werden können, allein dadurch, dass die Daten adaptiv steuern, wie sie komprimiert werden.
Zitation: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
Schlüsselwörter: Dimensionsreduktion, Manifold‑Lernen, nächste Nachbarn, intrinsische Dimension, Datenvisualisierung