Clear Sky Science · de
Verbesserter generalisierter Normalverteilungs-Optimizer mit Gaußscher Reparaturmethode und Cauchy-Umkehrlernen zur Merkmalwahl
Warum die richtige Datenauswahl wichtig ist
Das moderne Leben basiert auf Daten – von medizinischen Bildgebungen und Bankunterlagen bis hin zu Social-Media-Feeds. Mehr Daten sind dabei nicht immer besser. Wenn Computer aus Tausenden von Rohmessungen gleichzeitig lernen sollen, werden sie oft langsamer, teurer im Betrieb und mitunter überraschend ungenauer. Dieser Artikel stellt eine intelligentere Methode vor, um diese Messungen zu durchsieben und nur die wirklich relevanten beizubehalten, mithilfe eines neuen Algorithmus namens Binary Adaptive Generalized Normal Distribution Optimizer (BAGNDO).
Das Problem zu vieler Hinweise
Stellen Sie sich vor, eine Krankheit mit hunderten Laborwerten, Scans und Fragebogenantworten zu diagnostizieren. Viele dieser „Merkmale“ können verrauscht, redundant oder schlicht irrelevant sein; sie alle an einen Klassifikator zu übergeben, verwirrt eher, als dass es hilft. Die Merkmalauswahl zielt darauf ab, eine kleinere, informationsreichere Teilmenge von Eingaben zu wählen, damit Modelle des maschinellen Lernens schneller, günstiger und zuverlässiger werden. Einfache statistische Filter können offensichtlich nutzlose Merkmale entfernen, doch sie passen ihre Auswahl nicht an das jeweils verwendete Modell an und übersehen oft subtile Variablenkombinationen. Anspruchsvollere „Wrapper“-Methoden bewerten Merkmalsätze, indem sie direkt testen, wie gut ein Klassifikator mit ihnen arbeitet, was jedoch ein enormes Suchproblem erzeugt: Die Zahl möglicher Teilmengen explodiert mit wachsender Merkmalanzahl.
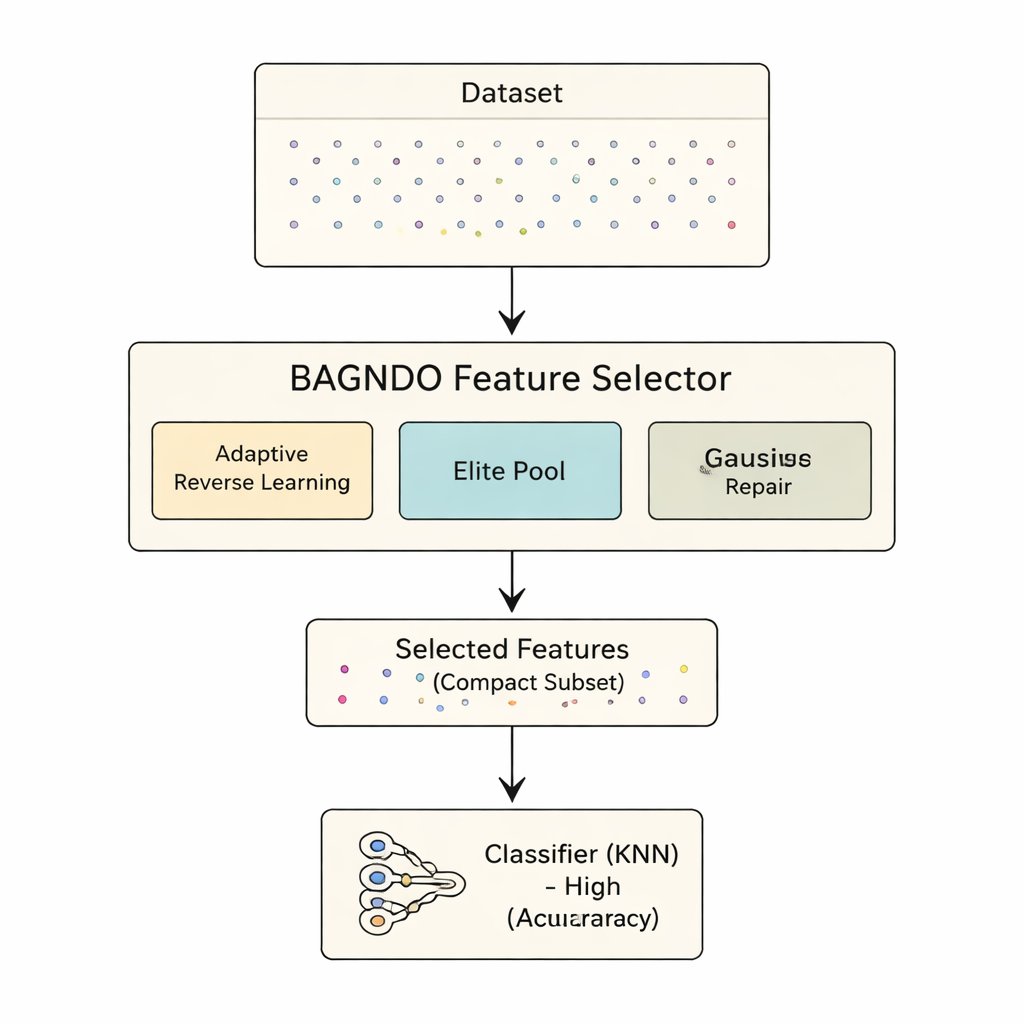
Intelligent statt blind suchen
Um mit dieser Explosion umzugehen, greifen Forscher auf metaheuristische Algorithmen zurück – Suchstrategien, die von natürlichen oder physikalischen Prozessen inspiriert sind und weite Erkundung mit gezielter Verfeinerung ausbalancieren. Ein solches Verfahren, der Generalized Normal Distribution Optimizer (GNDO), behandelt Kandidatenlösungen, als stammten sie aus einer flexiblen glockenförmigen Verteilung und verschiebt diese Verteilung schrittweise in Richtung besserer Lösungen. GNDO hat sich in Ingenieur- und Energieanwendungen bewährt, neigt jedoch dazu, sich zu früh auf nur mittelmäßige Lösungen festzulegen, und tut sich schwer, globales Erkunden und lokale Feinabstimmung beim Einsatz für Merkmalauswahl auszubalancieren. Die Autoren sehen hierin eine kritische Lücke: GNDOs elegante Mathematik führt nicht automatisch zu starker Leistung bei hochdimensionalen Ja/Nein-Entscheidungen darüber, welche Merkmale beibehalten werden sollen.
Ein dreiteiliges Upgrade für einen klassischen Motor
Das vorgeschlagene BAGNDO-Framework erweitert GNDO mit drei koordinierten Ideen. Erstens erzeugt eine Adaptive Cauchy Reverse Learning-Strategie regelmäßig „Spiegel“-Versionen aktueller Lösungen unter Verwendung einer schwergewichtigen (heavy-tailed) Wahrscheinlichkeitsverteilung. Das fördert mutige Sprünge in unerforschte Bereiche des Suchraums und verhindert, dass der Algorithmus in lokalen Tälern stecken bleibt. Zweitens bewahrt eine Elite-Pool-Strategie nicht nur die einzelne beste Lösung, sondern eine kleine Gruppe von Spitzenlösungen sowie einen gemischten „Guide“-Kandidaten. Diese reichere Führungsgruppe erhält Diversität, steuert die Suche aber zugleich in vielversprechende Regionen. Drittens betrachtet eine gaußsche Verteilungsbasierte Reparaturmethode für die schlechtesten Lösungen die schwächsten Kandidaten und lenkt sie in Richtung der vom Elite-Pool erkannten Muster, wodurch schlechte Lösungen effektiv recycelt werden, anstatt sie unmittelbar zu verwerfen.
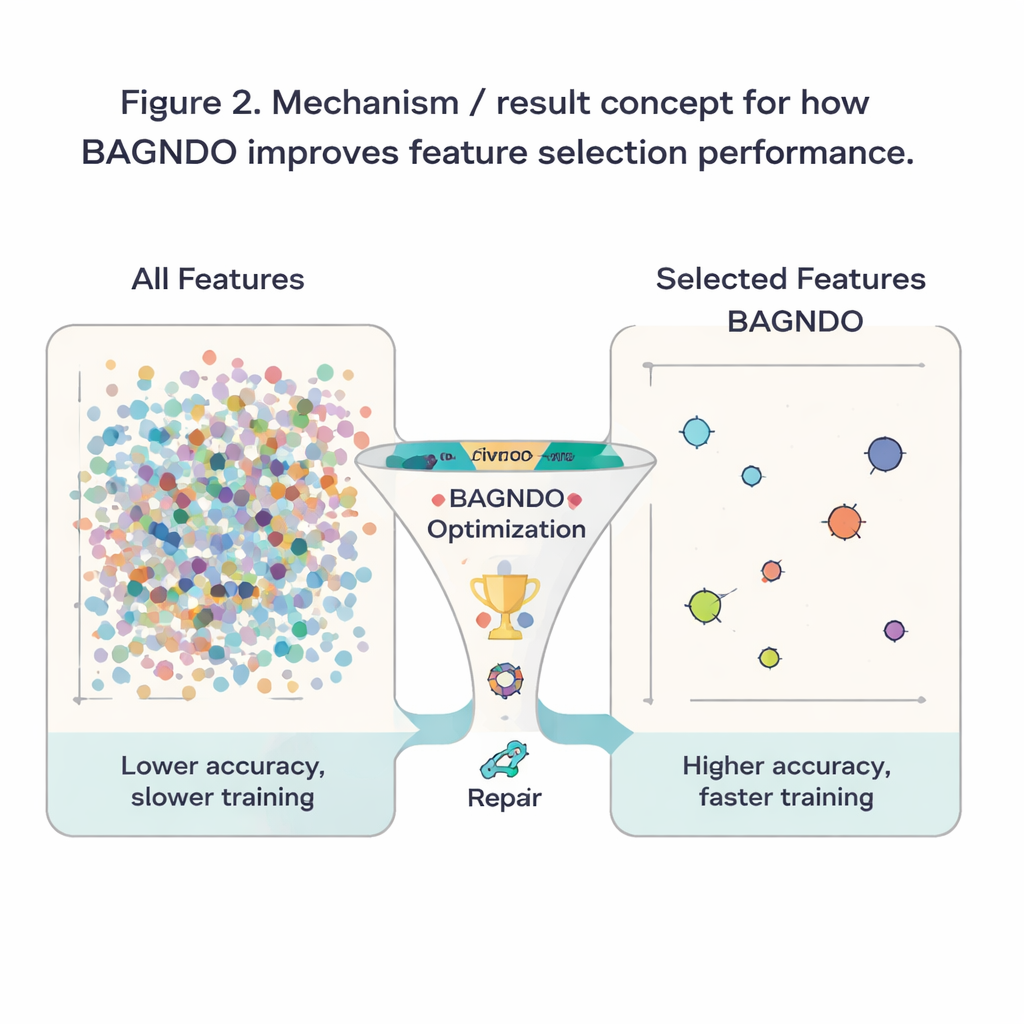
Den Ansatz auf die Probe stellen
Um zu prüfen, ob diese Ideen in der Praxis helfen, wendeten die Autoren BAGNDO auf 18 bekannte Benchmark-Datensätze aus dem UCI-Repository an, die Bereiche wie medizinische Diagnostik, Spiele und Signalverarbeitung abdecken. In jedem Fall suchte der Algorithmus nach einer Merkmalsmenge, mit der ein standardmäßiger k-Nearest-Neighbors-Klassifikator präzise Vorhersagen treffen konnte. BAGNDO trat gegen neun starke Konkurrenten an, darunter Particle-Swarm-Optimierung, genetisch inspirierte Verfahren und mehrere moderne schwarmbasierte Algorithmen. Über diese Tests hinweg fand BAGNDO durchweg kleinere Merkmalsmengen, während die Vorhersagegenauigkeit erhalten blieb oder sich häufig verbesserte. In 14 von 18 Datensätzen erreichte es die beste Genauigkeit bei den kompaktesten Merkmalsmengen, und statistische Tests bestätigten, dass diese Verbesserungen nicht zufällig waren.
Was das für alltägliches maschinelles Lernen bedeutet
Für Laien lässt sich das Ergebnis einfach zusammenfassen: Die Autoren haben einen disziplinierteren „Merkmalswähler“ entwickelt, der Lernalgorithmen hilft, sich auf das Wesentliche in einem Datensatz zu konzentrieren. Durch die bessere Balance aus weitreichender Erkundung, Eliteführung und Reparatur schlechter Kandidaten reduziert BAGNDO unnötige Eingaben und erhält oder steigert gleichzeitig die Genauigkeit. Das bedeutet schnellere Modelle, geringere Speicher- und Rechenkosten und oft klarere Einsichten, welche Messwerte oder Fragen am aussagekräftigsten sind. Obwohl die Methode rechenintensiver ist als manche einfachere Alternativen, bietet sie ein leistungsfähiges Werkzeug für Probleme, bei denen Genauigkeit und Interpretierbarkeit vorrangig sind – von medizinischer Entscheidungsunterstützung bis hin zur industriellen Überwachung und darüber hinaus.
Zitation: Ghetas, M., Elaziz, M.A. & Issa, M. Enhanced generalized normal distribution optimizer with Gaussian distribution repair method and cauchy reverse learning for features selection. Sci Rep 16, 4794 (2026). https://doi.org/10.1038/s41598-026-35804-y
Schlüsselwörter: Merkmalauswahl, metaheuristische Optimierung, maschinelles Lernen, Dimensionsreduktion, Klassifikationsgenauigkeit