Clear Sky Science · de
Quanten-Kernel-Methoden für Marketinganalytik mit Konvergenztheorie und Trennungsgrenzen
Warum schlauere Kundenprognosen wichtig sind
Unternehmen verlassen sich zunehmend auf Daten, um zu entscheiden, welche Kunden sie mit Angeboten, Support- oder Retentionskampagnen ansprechen. Wenn die Daten jedoch komplexer werden, tun sich herkömmliche Werkzeuge schwer, subtile Muster zu erkennen — besonders wenn jeder verpasste Hochwertkunde teuer ist. Dieses Papier untersucht, ob aufkommende Quantencomputer — Maschinen, die die Regeln der Quantenphysik nutzen — diese Prognosen für marketingähnliche Probleme schärfen könnten, und zwar mit einem klaren Blick auf die heutigen unvollkommenen, „rauschbehafteten“ Geräte.

Von Kundenakten zu Quanten-Schaltkreisen
Die Autoren konzentrieren sich auf eine praktische Aufgabe, die sie Konsumentenklassifikation nennen: die Vorhersage, welche Nutzer mit einem digitalen Dienst interagieren oder ihn übernehmen werden. Jeder Nutzer wird durch eine kleine Menge numerischer Merkmale beschrieben, etwa Demografie und Verhalten auf einer Plattform. Anstatt diese Daten direkt in einen Standardalgorithmus einzuspeisen, kodieren sie sie zunächst in die Zustände weniger Quantenbits (Qubits) mithilfe eines kompakten Quanten-Schaltkreises. Dieser Schaltkreis fungiert als Merkmalsumwandlung und formt die Daten in eine Darstellung, die es erleichtern kann, sie in zwei Gruppen zu trennen — „wahrscheinlich aktiv“ und „wahrscheinlich nicht aktiv“. Auf diese Quanten-Transformation setzen sie eine bekannte Klassifikationsmethode auf: die Support-Vektor-Maschine in einer quanten-inspirierten Variante, der sogenannten Quantum-Kernel SVM (Q-SVM).
Quantenideen unter realistischen Bedingungen testen
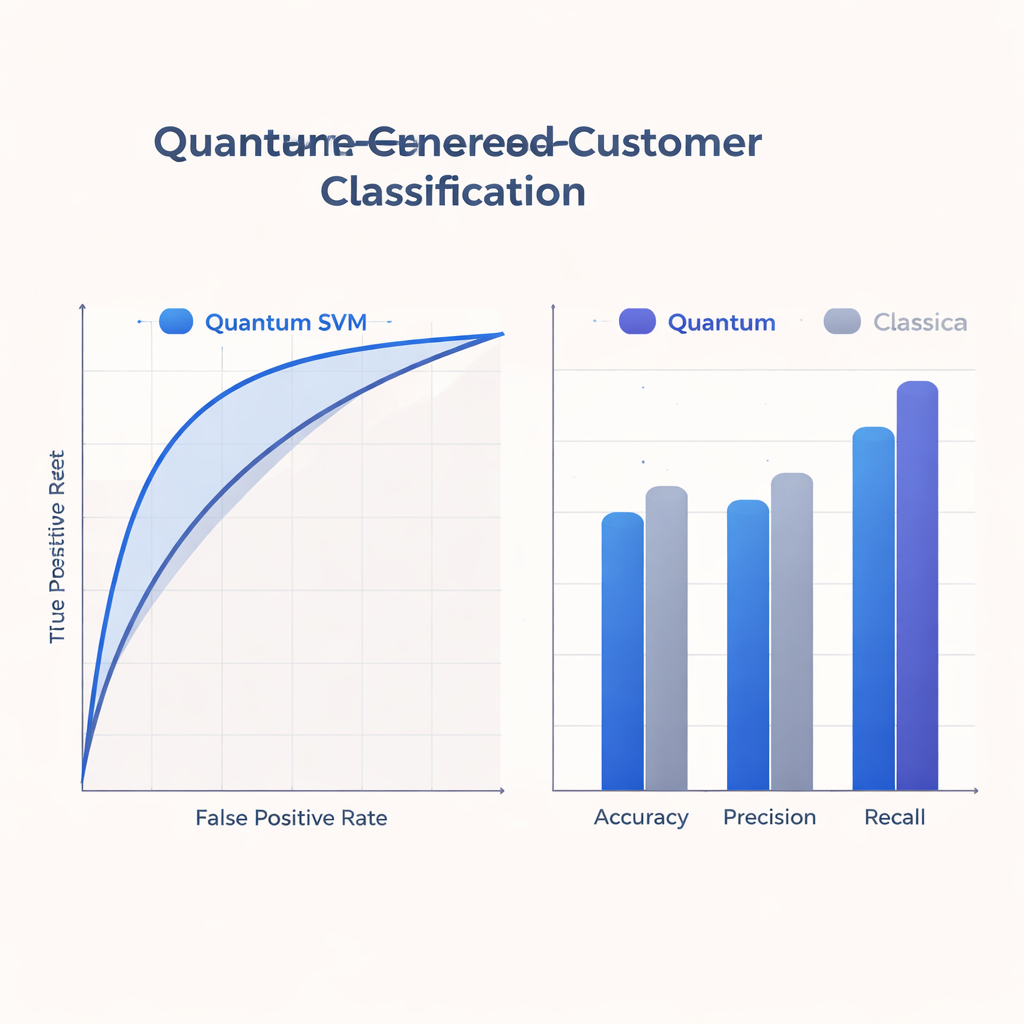
Da heutige Quantengeräte klein und fehleranfällig sind, beschränkt sich die Studie auf flache Schaltkreise, die zu dem passen, was kurzfristige Hardware leisten kann. Das Team trainiert und bewertet seine Q-SVM an einem realen, anonymisierten Datensatz mit etwa 500 Trainings- und 125 Testfällen und acht Merkmalen pro Nutzer und simuliert dabei sowohl ideales als auch rauschanfälliges Quantenverhalten. Sie vergleichen den quantenbasierten Ansatz mit starken klassischen Baselines, die gängige Kernel-Tricks auf Standardrechnern nutzen. In puncto Genauigkeit, Präzision, Recall und der Fläche unter der ROC-Kurve (eine Zusammenfassung der Abwägungen zwischen Trefferquote und Fehlalarmen) liefert die Q-SVM konkurrenzfähige oder bessere Ergebnisse, insbesondere beim Recall: Sie identifiziert einen höheren Anteil tatsächlich interessierter Nutzer als die klassischen Modelle.
Theoretische Garantien hinter den Kulissen
Über die rohe Leistungsbewertung hinaus stellt das Papier eine tiefere Frage: Wann sollten Quantenmethoden überhaupt zu Verbesserungen führen? Die Autoren entwickeln drei zentrale theoretische Ergebnisse. Erstens zeigen sie, dass, wenn das Lernproblem bestimmte Glattheitsbedingungen erfüllt und die Quanten-Schaltkreise flach bleiben, der Trainingsprozess für Quanten-Kernel zuverlässig in einer vernünftigen Anzahl von Schritten konvergieren sollte. Zweitens liefern sie Trennungsgrenzen, die nahelegen, dass ihre quantenbasierte Merkmalsextraktion unter spezifischen Annahmen den Abstand zwischen beiden Kundengruppen im Vergleich zu klassischen Transformationen vergrößern kann — wodurch das Problem im Wesentlichen leichter lösbar wird. Drittens analysieren sie, wie approximative Methoden die Kosten für die Arbeit mit großen, aus Quanten gewonnenen Merkmalsräumen drastisch reduzieren können, sodass der Ansatz weiterhin rechnerisch praktikabel bleibt.
Was das für Vermarkter bedeuten könnte
Für Marketing- und Kundenanalyseteams liegt der greifbarste Nutzen in der Balance des Quantenmodells zwischen verpassten Chancen und verschwendeter Ansprache. Der höhere Recall der Q-SVM bedeutet, dass sie weniger wahrscheinlich Nutzer übersieht, die positiv auf ein Angebot reagieren würden — ein wichtiger Vorteil bei Retentions- oder proaktiven Servicekampagnen. Gleichzeitig bleiben Präzision und Gesamtgenauigkeit in einem Bereich, der mit starken klassischen Baselines vergleichbar ist, gestützt durch eine robuste ROC-Kurve. Da die Methode über eine Bandbreite von Entscheidungsgrenzen gut funktioniert, könnten Teams einstellen, wie aggressiv oder vorsichtig sie vorgehen — zugunsten von Recall oder Präzision — ohne das Modell jedes Mal neu trainieren zu müssen.
Ein vielversprechender Anfang, noch keine Quantenrevolution
Die Autoren betonen, dass ihre Ergebnisse frühe Schritte sind und keinen Beweis für eine umfassende Quantenvorherrschaft darstellen. Die Resultate stammen aus Simulationen an einem Datensatz, nicht aus großflächigen Hardwareläufen oder vielen unterschiedlichen Märkten. Auch die mathematischen Garantien beruhen auf idealisierten Annahmen, die auf verrauschten Geräten nicht vollständig gelten könnten. Dennoch zeigt die Arbeit, dass sorgfältig entworfene Quanten-Kernel bereits mit guten klassischen Methoden bei einer realistischen Konsumentenaufgabe mithalten oder sie leicht übertreffen können, und sie bietet einen klaren Weg zu größeren Vorteilen, wenn die Quantenhardware skaliert. Für die Leserschaft lautet die Quintessenz: Quantenmaschinelles Lernen bewegt sich vom abstrakten Versprechen hin zu Werkzeugen, die eines Tages Kundenprognosen in realen Geschäftsumgebungen genauer und flexibler machen könnten.
Zitation: Sáez Ortuño, L., Forgas Coll, S. & Ferrara, M. Quantum kernel methods for marketing analytics with convergence theory and separation bounds. Sci Rep 16, 6645 (2026). https://doi.org/10.1038/s41598-026-35793-y
Schlüsselwörter: quantenmaschinelles Lernen, marketinganalytik, Kundenklassifikation, Support-Vektor-Maschinen, Quanten-Kernel