Clear Sky Science · de
Fusion von Infrarot- und sichtbaren Bildern durch visuelle Verbesserung und semantische Kopplung
Scharfere Sicht von Tag- und Nachtkameras
Moderne Autos, Drohnen und Sicherheitssysteme tragen oft zwei Arten von Augen: eine normale Kamera, die Farbe und Textur erfasst, und eine Infrarotkamera, die Wärme sichtbar macht. Jede hat Stärken und Schwächen, und sie zu einem einzigen klaren Bild zu verschmelzen, ist überraschend schwierig. Dieses Papier stellt einen neuen Ansatz vor, um diese beiden Perspektiven in ein Bild zu vereinen, das nicht nur angenehmer anzusehen ist, sondern auch leichter von Computerprogrammen zu interpretieren ist.
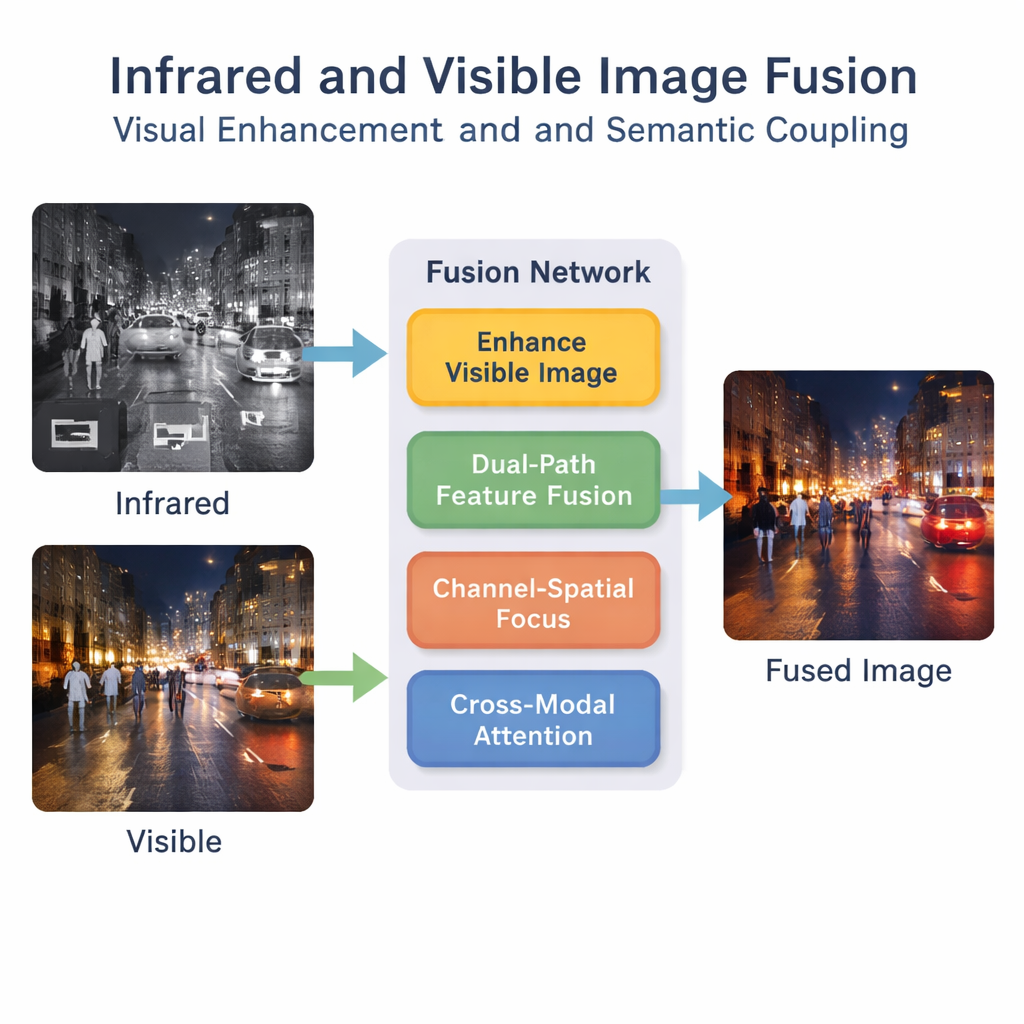
Warum zwei Augen besser sind als eins
Sichtbare Lichtkameras erfassen scharfe Details wie Fahrbahnmarkierungen, Gebäudekanten und Kleidung, haben jedoch bei Nacht, bei Nebel oder wenn Objekte mit dem Hintergrund verschmelzen, Schwierigkeiten. Infrarotkameras machen genau das Gegenteil: Sie heben warme Objekte wie Menschen und Fahrzeuge selbst in der Dunkelheit hervor, doch ihre Bilder wirken verschwommen und es fehlen feine Details. Die Fusion dieser beiden Ansichten zu einem „Best-of-both-worlds“-Bild kann bei Aufgaben helfen, die von Fußgängererkennung in Fahrerassistenzsystemen bis zu Überwachung und Suche-Rettung reichen. Viele bestehende Fusionsmethoden konzentrieren sich jedoch nur auf Oberflächenmerkmale – helle Stellen aus dem Infrarot und Texturen aus dem sichtbaren Bild – und vernachlässigen die tiefere, szenenbezogene Bedeutung, die für intelligente Maschinen wichtig ist.
Eine intelligentere Art, Bilder zu mischen
Die Autoren schlagen ein Deep-Learning-Framework vor, das Fusion nicht als einfache Überlagerung betrachtet. Zuerst hellt ein spezieller Verbesserungs-Schritt das sichtbare Bild auf und balanciert es aus, besonders in schwach beleuchteten Szenen, damit wertvolle Details nicht schon vor der Fusion verloren gehen. Dann verarbeitet ein dualer Pfadnetzwerk sowohl Infrarot- als auch sichtbare Eingaben parallel. Ein Pfad konzentriert sich auf lokale Muster wie Kanten und Texturen, während der andere den weiteren Kontext der Szene betrachtet. Durch die Kombination dieser Pfade erzeugt das System eine reichhaltigere interne Beschreibung dessen, was in den Bildern vor sich geht.
Dem Netzwerk beibringen, worauf es achten soll
Viele Merkmale zu extrahieren reicht nicht aus; das Netzwerk muss lernen, welche davon wichtig sind. Ein „Channel–Spatial“-Modul hilft dem Modell, kritische Bereiche und Informationsarten hervorzuheben, etwa Fußgänger oder helle Scheinwerfer, und weniger nützlichen Hintergrundlärm zu unterdrücken. Darüber hinaus ermutigt ein bimodaler interaktiver Aufmerksamkeitsmechanismus die Infrarot- und Sichtbarkeitsströme zur gegenseitigen Kommunikation. Er lernt, wie Wärmezeichen und visuelle Texturen szenenweit aufeinander abgestimmt sind und erfasst höherstufige Konzepte wie „dieser helle Fleck im Infrarot entspricht jener Person im sichtbaren Bild“. Diese semantische Kopplung hilft, dass das gefügte Bild logisch konsistent bleibt und nicht nur visuell vermischt wirkt.

Die Methode auf die Probe gestellt
Um zu prüfen, ob die gefügten Bilder nicht nur ansprechend, sondern auch realistisch sind, fügen die Autoren ein Diskriminatornetzwerk hinzu, ähnlich denen, die in generativen gegnerischen Netzen verwendet werden. Dieses zusätzliche Netzwerk lernt, echte sichtbare Bilder von gefügten zu unterscheiden, und treibt so den Fusionsprozess dazu, Ausgaben zu erzeugen, die sowohl für Menschen als auch für Maschinen natürlich wirken. Die Methode wird auf drei herausfordernden Sammlungen von Infrarot–Sichtpaaren trainiert und getestet, die Tages- und Nachtaufnahmen von Straßen sowie militärisch geprägte Szenen abdecken. Über eine Reihe standardisierter Qualitätsmaße hinweg übertrifft der neue Ansatz im Allgemeinen zehn bestehende Fusionstechniken und erzeugt Bilder mit schärferen Kanten, besserem Kontrast und informativeren Inhalten.
Bessere Bilder für sicherere Maschinen
Über die visuelle Qualität hinaus stellen die Autoren eine praktische Frage: Helfen diese gefügten Bilder Computern, bessere Entscheidungen zu treffen? Mithilfe eines verbreiteten Objekterkennungssystems zur Identifikation von Fußgängern zeigen sie, dass ihre gefügten Bilder die Erkennungsgenauigkeit im Vergleich zu Einzel-Sensor-Bildern und früheren Fusionsmethoden verbessern. Alltäglich gesprochen erzeugt die Technik Bilder, die sowohl für Menschen als auch für Algorithmen leichter zu interpretieren sind, besonders unter schwierigen Bedingungen wie nächtlicher Fahrt. Zwar muss das System noch für den Echtzeiteinsatz in ressourcenbeschränkten Geräten optimiert werden, doch es stellt einen vielversprechenden Schritt zu sichererer, zuverlässigerer Sicht in autonomen Fahrzeugen, Überwachung und anderen Technologien dar, die in kritischen Situationen klar sehen müssen.
Zitation: Yang, Y., Li, Y., Li, J. et al. Infrared and visible image fusion via visual enhancement and semantic coupling. Sci Rep 16, 5666 (2026). https://doi.org/10.1038/s41598-026-35763-4
Schlüsselwörter: Bildfusion, Infrarotbildgebung, Nachtsicht, Deep Learning, Objekterkennung