Clear Sky Science · de
Akustischer Wachposten: hierarchische Klassifikation von Schrittschall mittels feinkörniger und grobkörniger akustischer Merkmalsrepräsentationen für taktische Überwachung
Auf laute, versteckte Schritte hören
Stellen Sie sich vor, Menschen in einem dunklen Wald oder entlang einer abgelegenen Grenze zu entdecken, ganz ohne Kameras — allein durch das Zuhören ihrer Schritte. Diese Studie untersucht, wie die feinen Geräusche des Gehens in ein leistungsfähiges Frühwarnsystem für Soldaten, Polizei und Ermittler verwandelt werden können, insbesondere an Orten, an denen Kameras versagen oder Strom knapp ist.
Warum Kameras nicht ausreichen
Moderne Sicherheit beruht oft auf Videoüberwachung, doch Kameras haben klare Schwächen: Sie benötigen Sichtkontakt, verbrauchen viel Energie und sind in unwegsamem oder feindlichem Gelände schwer schnell zu installieren. Mobile Kontrollpunkte, Grenzpatrouillen und Antiterror‑Einheiten operieren häufig nachts, unter dichtem Laub oder in bergigen Regionen, wo das Aufstellen und Warten von Kameranetzen unpraktisch ist. In solchen Situationen wird Klang zu einer attraktiven Alternative. Mikrofone sind leicht, benötigen weniger Energie und können „um Ecken hören“, also Personen erfassen, bevor sie sichtbar werden. Schritte sind zwar relativ leise, heben sich aber in vielen taktischen Umgebungen mit geringem Hintergrundrauschen deutlich ab und stellen damit ein vielversprechendes Signal für Frühwarnung und forensische Rekonstruktion von Ereignissen dar.
Aufbau einer realen Schritt‑Bibliothek
Um diese Idee in ein funktionierendes System zu überführen, mussten die Forscher zunächst ein grundlegendes Problem lösen: Es gab keine geeignete Sammlung realer Schrittaufnahmen. Bestehende Klangdatenbanken enthalten zwar einige Schritte, meist für generelle Sounderkennung oder Identifikationsaufgaben, diese wurden jedoch oft unter kontrollierten Laborbedingungen aufgenommen. Häufig werden weder Umwelttyp (Wald, Straße, Innenraum) noch die Anzahl der beteiligten Personen angegeben. Das Team erstellte deshalb eine neue Ressource namens EWFootstep 1.0. Sie umfasst 1.650 Audioclips von 176 Freiwilligen, die natürlich über Wälder, Straßen und Innenräume in drei Regionen Indiens gingen. Die Aufnahmen erfassen eine Mischung aus weichen und harten Schuhsohlen, unterschiedliche Untergründe und realistische Feldbedingungen wie ungleichmäßige Mikrofonpositionen. Jeder Clip enthält mindestens 15 Schritte und ist sowohl nach Umgebungstyp als auch danach gelabelt, ob eine einzelne Person oder eine Gruppe zu hören ist.
Der Maschine beibringen, wie ein Späher zu hören
Mit diesem Datensatz entwickelten die Autoren ein Hörsystem, das nachahmt, wie ein erfahrener Späher akustisch schlussfolgert. Anstatt alle Aufgaben gleich zu behandeln, entscheidet ihr „hierarchisches Multi‑Task‑Modell“ zuerst, wo das Geräusch stattfindet — Wald, Straße oder Innenraum — und schätzt dann anhand dieses Kontexts, ob eine einzelne Person oder mehrere Personen vorhanden sind. Das Audio wird in farbige Spektrogramme umgewandelt, die zeigen, wie sich Energie über Frequenzen und Zeit verteilt. Eine Reihe von Faltungs‑(Convolutional-)Schichten extrahiert feine Details, die mit Oberflächen und Schuhwerk verknüpft sind, etwa das Knacken von Laub oder das dumpfe Auftreten von Stiefeln auf Beton. Diese Merkmale werden anschließend an ein Transformer‑Modul weitergegeben, eine moderne Sequenz‑Verarbeitungseinheit, die Muster über viele Schritte hinweg untersucht — Rhythmus, Abstände und wiederkehrende Impakte — statt isolierte Geräusche. Positionskodierung hilft dem Modell, die Reihenfolge in der Zeit zu behalten, was für das Erkennen von Gehmustern essenziell ist.
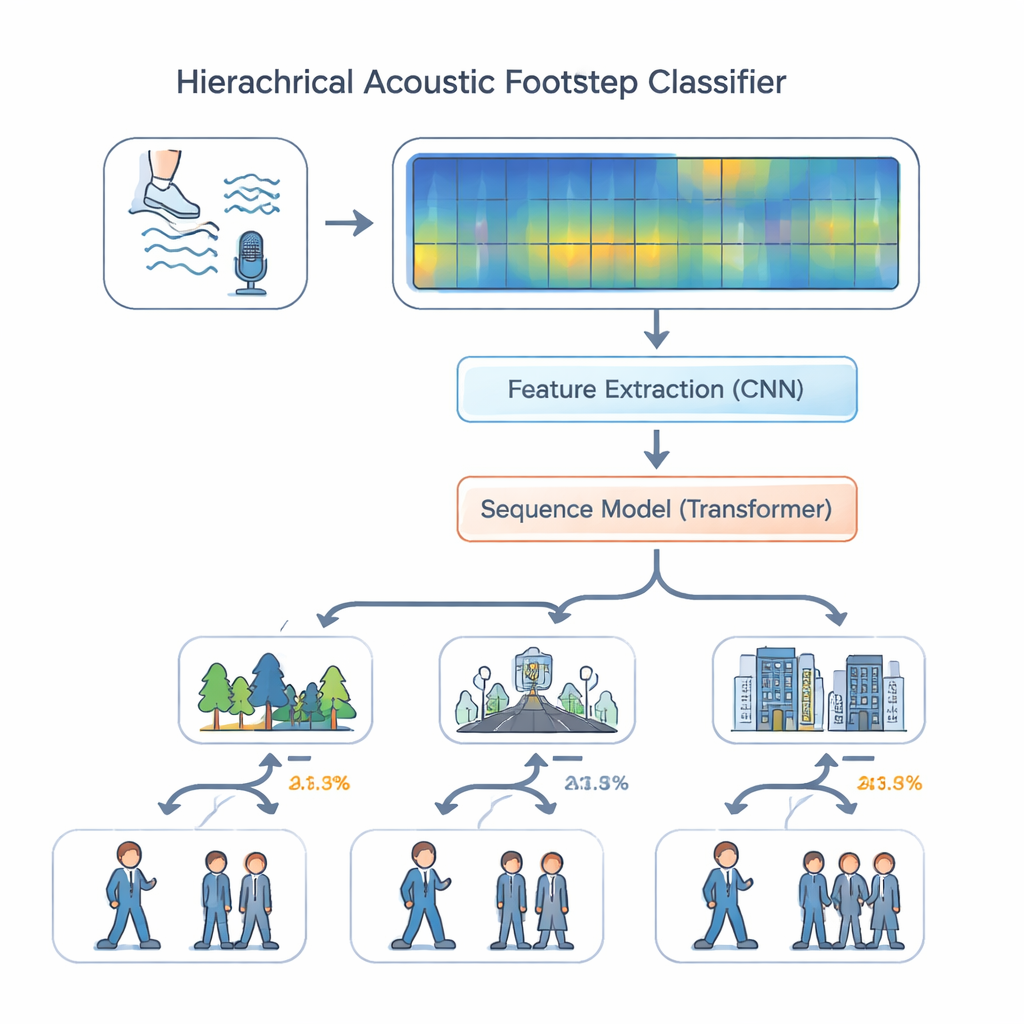
Wie gut funktioniert der akustische Wachposten?
Die Forscher verglichen ihr hierarchisches Modell mit einfacheren Ansätzen, etwa einem einzigen All‑in‑One‑Klassifikator und einem standardmäßigen Multi‑Task‑Design, bei dem Umgebung und Personenanzahl unabhängig vorhergesagt werden. Sie testeten auch Varianten, bei denen zentrale Komponenten wie die Faltungs‑Schichten oder der Transformer entfallen. Insgesamt lieferte das vollständige Design mit beiden Modulen und Positionskodierung die beste Leistung. Auf dem EWFootstep 1.0‑Datensatz erkannte es die Umgebung in etwa 96 Prozent der Fälle korrekt und die Personenanzahl mit ähnlicher Genauigkeit — deutlich besser als trainierte menschliche Zuhörer, die um 25 bis 30 Prozentpunkte zurücklagen. Zusätzliche Experimente mit einem Husten‑Klangdatensatz zeigten, dass dieselbe Architektur gut auf andere Klangarten verallgemeinert, was darauf hindeutet, dass sie sehr unterschiedliche Alltagsgeräusche verarbeiten kann.
Vom Schlachtfeld zum Tatort
Für Nicht‑Spezialisten ist die zentrale Erkenntnis: Leise, alltägliche Geräusche wie Schritte enthalten weit mehr Informationen, als wir üblicherweise wahrnehmen. Durch die Kombination großer, realistischer Datensätze mit fortschrittlichen Mustererkennungswerkzeugen zeigen die Autoren, dass ein kompaktes System in nahezu Echtzeit zuverlässig erkennen kann, welche Art von Umgebung es abhört und wie viele Personen vorhanden sind — und das ohne Kameras. Dieser „akustische Wachposten" könnte Patrouillen und abgelegene Einrichtungen schützen, und seine Fähigkeit, subtile Klangmuster zu analysieren, kann auch der Audioforensik dienen, etwa bei der Rekonstruktion von Bewegungen an einem Tatort, wenn Videoaufnahmen fehlen oder unzuverlässig sind.
Zitation: Agrahri, A., Maurya, C.K., Tiwari, R.S. et al. Acoustic sentinel: hierarchical classification of footstep sound using fine and coarse-grain acoustic feature representations for tactical surveillance. Sci Rep 16, 5635 (2026). https://doi.org/10.1038/s41598-026-35756-3
Schlüsselwörter: akustische Überwachung, Schritterkennung, Frühwarnsysteme, Tiefes Lernen Audio, taktische Sicherheit