Clear Sky Science · de
Maschinelles Lernen zur schnellen Schätzung makroseismischer Intensität aus seismometrischen Daten in Italien
Warum schnelle Erdbebenbewertungen wichtig sind
Wenn der Boden zu beben beginnt, haben Einsatzkräfte nur wenige Minuten, um zu entscheiden, wohin Retter und Ressourcen geschickt werden sollen. Die übliche Art, wie stark ein Erdbeben an der Oberfläche empfunden wird – makroseismische Intensität, etwa die in Italien verwendete Mercalli-Skala – trifft jedoch oft erst Stunden, Tage oder sogar Monate später ein, nachdem Menschen Fragebögen ausgefüllt und Experten Schäden begutachtet haben. Dieser Artikel untersucht, wie modernes maschinelles Lernen die ersten Seismometer-Messwerte in schnelle, einigermaßen genaue Karten verwandeln kann, die zeigen, wie stark ein Erdbeben wahrgenommen wurde, und damit Behörden helfen, schneller und sicherer zu reagieren.
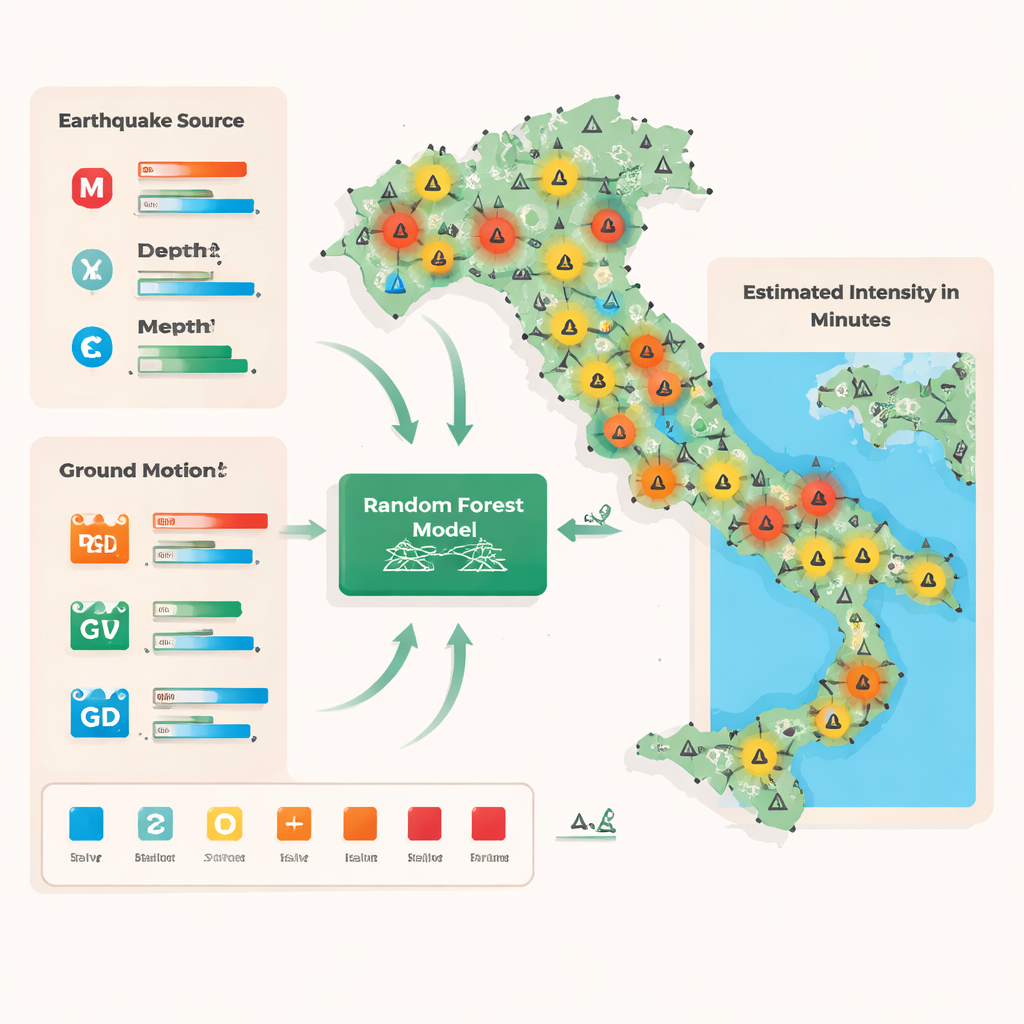
Von Wahrnehmungsmeldungen zu schnellen Schätzungen
Traditionelle Intensitätsschätzungen in Italien stützen sich auf zwei Hauptdatenströme. Der eine besteht aus Experten-Felduntersuchungen, die in einer offiziellen Datenbank protokolliert werden und sich auf beschädigte Orte konzentrieren, aber Zeit zur Organisation benötigen. Der andere stammt vom Online-System „Hai Sentito Il Terremoto“, in dem Bürger melden, was sie gefühlt und gesehen haben, wodurch viele Beobachtungen mit niedriger und mittlerer Intensität zusammenkommen. Beide Quellen bewerten die Intensität auf der Mercalli-Cancani-Sieberg-Skala, die das Beben anhand menschlicher und Gebäudereaktionen von sehr schwach bis zerstörerisch einstuft. Um diese menschenzentrierten Maße mit instrumentellen Messungen zu verknüpfen, haben die Autoren die beiden Datensätze um jede seismische Station herum zusammengeführt, alle gemeldeten Intensitäten innerhalb von 5 km gemittelt, um einen repräsentativen Wert für das Gebiet zu erhalten, und diesen auf eine Ganzzahlklasse zwischen 1 und 8 gerundet.
Ein Wald von Modellen lernt, das Beben zu lesen
Die Forschenden formulierten die Intensitätsschätzung als Klassifikationsproblem: Bei gegebenen frühen Messungen soll vorhergesagt werden, welche von acht Intensitätsklassen für die Umgebung jeder Station zutrifft. Sie verwendeten einen Random Forest, ein Ensemble aus vielen Entscheidungsbäumen, die jeweils eine einfache Reihe von Wenn‑Dann-Aufteilungen der Daten vornehmen, beispielsweise Kombinationen aus Magnitude, Tiefe, Entfernung zur Quelle und direkten Bodenbewegungsgrößen wie Spitzenbeschleunigung, -geschwindigkeit und -verschiebung. Trainiert an 5.466 Beobachtungen aus 523 Erdbeben in Italien (2008–2020) lernte das Modell komplexe, nichtlineare Zusammenhänge zwischen dem, was Seismometer aufzeichnen, und dem, was Menschen berichten. Um damit umzugehen, dass starkes Beben in den Daten seltener vorkommt, passten die Autoren das Training so an, dass alle Intensitätsstufen gleich gewichtet wurden, wodurch verhindert wurde, dass das Modell sich nur auf die häufigeren, schwächeren Ereignisse konzentriert.
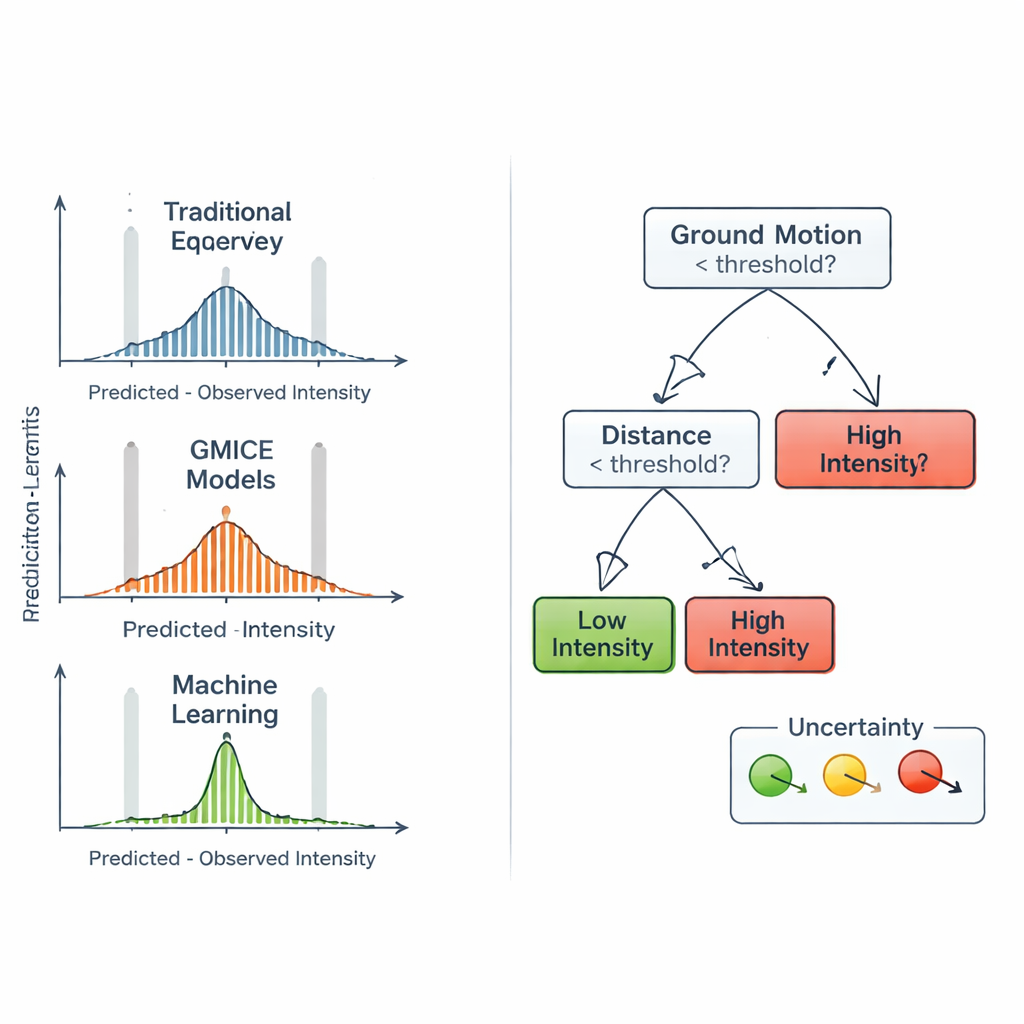
Vergleich mit etablierten Regeln
Um zu prüfen, ob der maschinelle Lernansatz tatsächlich einen Mehrwert liefert, verglich das Team seine Vorhersagen mit zwei weithin genutzten Gruppen empirischer Beziehungen. Die erste, sogenannte Intensity Prediction Equations, schätzt die Intensität hauptsächlich aus Magnitude, Tiefe und Distanz und geht davon aus, dass die Bewegung mit der Entfernung auf glatte Weise abklingt. Die zweite, Ground Motion to Intensity Conversion Equations, übersetzt instrumentelle Messungen der Spitzenbewegung in erwartete Intensitätsklassen. Diese Formeln sind kompakt und einfach anzuwenden, können aber nicht vollständig erfassen, wie lokale Geologie, Gebäudebestand oder Wellenausrichtung das Empfinden beeinflussen. Im Gegensatz dazu integriert der Random Forest natürlich sowohl Quellparameter als auch Bodenbewegungsgrößen und kann sich ohne Festlegung einer starren mathematischen Form an subtile Muster im italienischen Datensatz anpassen.
Ein Blick in die Blackbox und ihre Grenzen
Da Einsatzleiter die Grundlage automatisierter Entscheidungen verstehen müssen, bauten die Autoren einfachere „Surrogat“-Entscheidungsbäume, die das Verhalten des Random Forest nachahmen. Diese kleineren Bäume lassen sich als Diagramme darstellen und zeigen, welche Schwellen der Bodenbewegung niedrige von hohen Intensitäten trennen und wo Variablen wie Beschleunigung und Geschwindigkeit dominieren. Diese Analyse zeigte, dass direkte Bodenbewegungsmaße, insbesondere Spitzenbeschleunigung und -geschwindigkeit, stärker ins Gewicht fallen als Magnitude oder Tiefe allein. Die Autoren führten außerdem eine einfache Methode ein, um zu kennzeichnen, wie unsicher jede Surrogat‑Baum‑Vorhersage ist, indem sie messen, wie gemischt die Trainingsbeispiele in jedem Endknoten sind. Zugleich stellten sie fest, dass sehr starke Intensitäten schwer vorherzusagen bleiben, zum Teil weil sie in den historischen Aufzeichnungen naturgemäß selten sind, was gelegentlich zu Unterschätzungen der höchsten Erschütterungsgrade führt.
Praxisprüfung bei einem jüngeren italienischen Erdbeben
Das Team bewertete sein Verfahren an einem bemerkenswerten Realereignis: einem Erdbeben der Magnitude 5,5 vor der Adria-Küste bei Pesaro-Urbino im Jahr 2022. Innerhalb von etwa 15 Minuten lagen Seismologen die notwendigen Quellen- und Bodenbewegungsdaten vor, aber nur rund 90 öffentliche Intensitätsmeldungen waren eingegangen, was ein sehr lückenhaftes Bild ergab. Allein mit den instrumentellen Daten erzeugten der Random Forest und sein Surrogatbaum in weniger als zwei Sekunden auf einem Standardrechner detaillierte Intensitätsschätzungen rund um Hunderte von Stationen. Im späteren Vergleich mit der deutlich dichteren Karte, die aus mehr als 12.000 von Bürgern über Tage gesammelten Meldungen erstellt wurde, fingen die maschinellen Lernkarten sowohl das insgesamt betroffene Gebiet als auch die Verteilung mäßiger Erschütterungen bemerkenswert gut ein und entsprachen den klassischen Gleichungen oder übertrafen sie.
Was das für Menschen bedeutet, die mit Erdbeben leben
Insgesamt zeigt die Studie, dass ein sorgfältig trainiertes System des maschinellen Lernens die ersten Minuten von Seismometerdaten nutzen kann, um schnelle, einigermaßen transparente Karten der Erdbebenwirkung zu erstellen. Diese Karten ersetzen keine detaillierten Felduntersuchungen oder Crowdsourcing‑Meldungen, können aber die gefährliche frühe Lücke überbrücken, in der Behörden mit sehr begrenzten Informationen entscheiden müssen, wohin sie Rettungswagen, Feuerwehr und Bauprüfer schicken. Durch die Kombination fortschrittlicher Algorithmen mit interpretierbaren vereinfachten Modellen und grundlegenden Unsicherheitskennzeichen bietet das Rahmenwerk einen praktischen Schritt zu schnellerer, besser informierter Reaktion auf Erdbeben in Italien und ließe sich an andere Regionen mit ähnlichen seismischen Risiken anpassen.
Zitation: Patelli, L., Cameletti, M., De Rubeis, V. et al. Machine learning for prompt estimation of macroseismic intensity from seismometric data in Italy. Sci Rep 16, 7265 (2026). https://doi.org/10.1038/s41598-026-35740-x
Schlüsselwörter: Erdbebenintensität, Maschinelles Lernen, Random Forest, seismische Gefährdung, Italien