Clear Sky Science · de
Mehrfach‑Merkmals‑Verstärkungs‑Fusionsnetzwerk für die semantische Segmentierung ferngesteuerter Bilder
Scharfere Karten aus der Luft
Jeden Tag erfassen Satelliten und Drohnen detaillierte Bilder unserer Städte und landwirtschaftlichen Flächen. Aus diesen Rohbildern klare Pixel‑für‑Pixel‑Karten von Straßen, Dächern, Bäumen und Feldern zu erstellen, ist grundlegend für Aufgaben wie die Überwachung der Pflanzengesundheit oder die Planung neuer Wohngebiete. Diese Arbeit stellt einen neuen Ansatz vor, der diese Karten genauer macht — insbesondere an schwierigen Übergängen, an denen Gebäude, Felder und Vegetation ineinander übergehen.
Warum Luftbilder schwer zu interpretieren sind
Fernerkundungsbilder unterscheiden sich von Alltagsfotos. Sie werden aus großer Höhe aufgenommen, oft in flachem Winkel und bei wechselnden Lichtverhältnissen. Verschiedene Objekte können aus der Luft sehr ähnlich erscheinen: ein Betonparkplatz und ein flaches Dach können fast dieselbe Farbe haben; unterschiedliche Nutzpflanzen können verwirrend ähnliche Muster zeigen. Gleichzeitig kann dieselbe Objektklasse je nach Schatten, Feuchtigkeit oder Kameraeinstellungen sehr unterschiedlich aussehen. Traditionelle Programme und viele moderne Deep‑Learning‑Systeme tun sich unter diesen Bedingungen schwer, scharfe Grenzen zu erhalten. Sie verwischen oft Kanten zwischen Kategorien oder übersehen kleine Details wie parkende Autos oder schmale Bewässerungsgräben.
Sowohl das große Ganze als auch die feinen Linien sehen
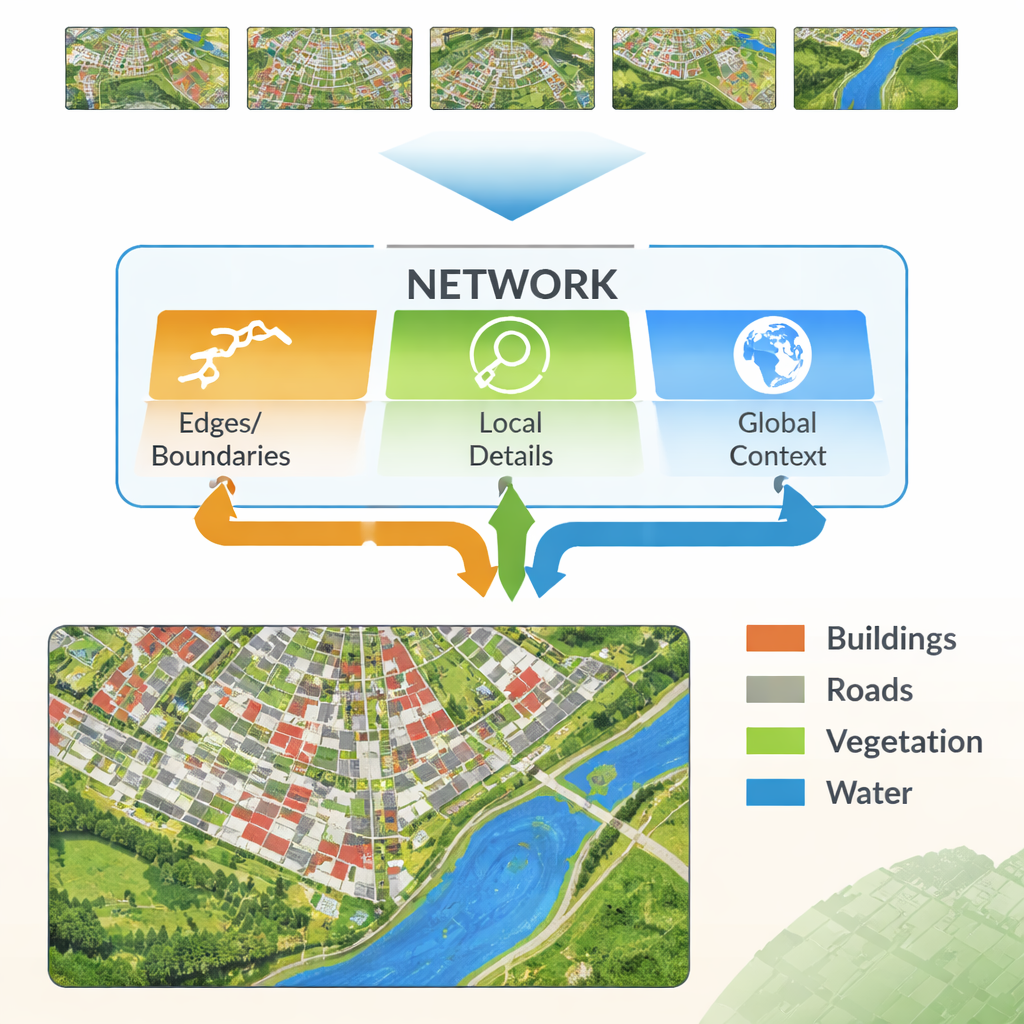
Moderne neuronale Netze lernen, indem sie ein Bild durch viele Schichten leiten. Frühe Schichten erfassen feine Details wie Linien und Texturen, während tiefere Schichten breite Muster lernen, etwa „dieser Bereich ist wahrscheinlich Gebäude“. Die Herausforderung besteht darin, diese beiden Informationsarten zusammenzuführen. Niedrigstufige Details können rauschen oder redundant sein, und hochstufige Muster können Kanten kaschieren und zu unscharfen Umrissen führen. Die Autoren schlagen eine neue Architektur vor, das Multi‑Feature Enhancement Fusion Network (MFEF‑UNet), das gezielt darauf ausgelegt ist, lokale Details mit globalem Verständnis ins Gleichgewicht zu bringen. Es behandelt Kanten, lokale Muster und breiten Kontext als getrennte, aber kooperierende Informationsquellen.
Kanten hervorheben und Merkmale verschmelzen
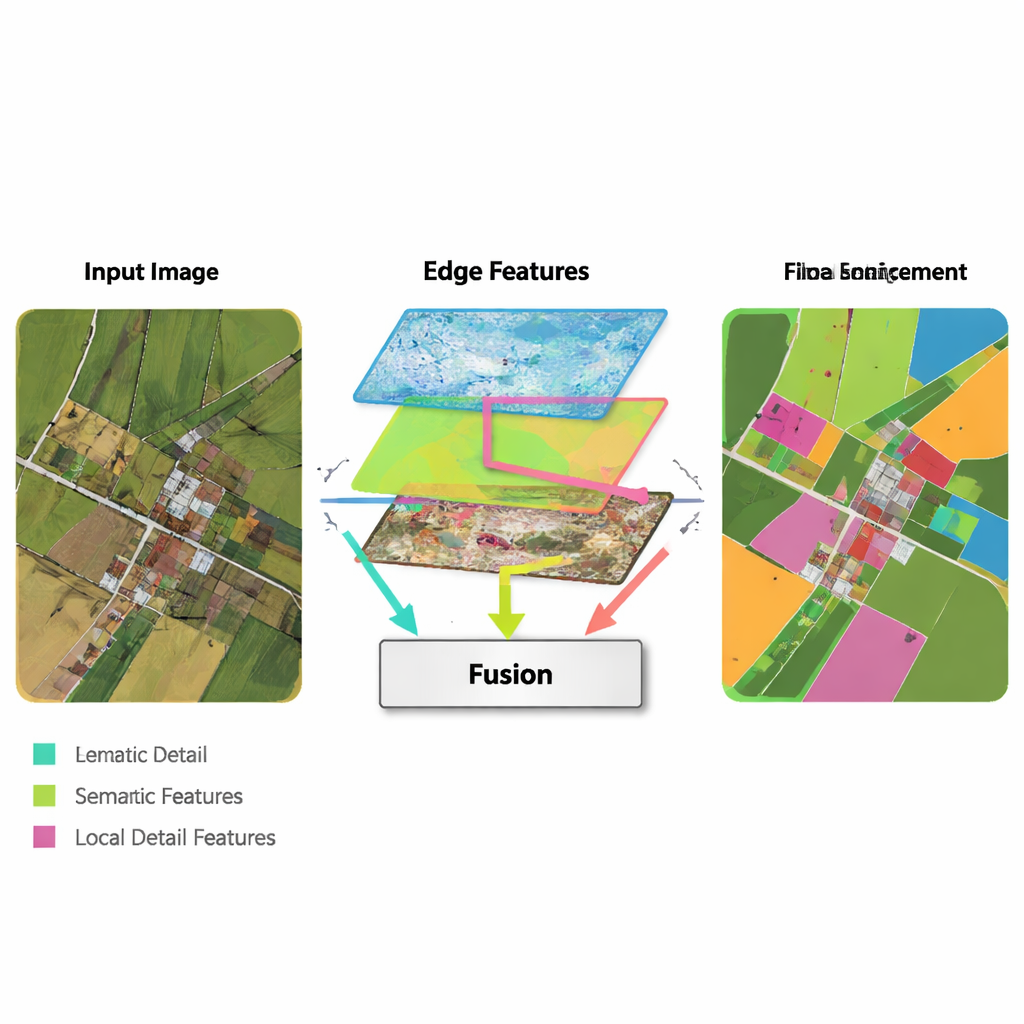
Eine zentrale Idee der neuen Methode ist, einfache, klassische Kantenerkennungswerkzeuge in eine moderne Deep‑Learning‑Pipeline einzubetten. Ein Edge‑Enhancement‑Modul nimmt die frühesten Merkmale des Netzes und führt sie durch Operatoren, die gut darin sind, Grenzen zu finden — ähnlich wie Basis‑Bildbearbeitungsprogramme Umrisse erkennen. Diese verbesserten Kantenkarten werden in mehreren Skalen erzeugt, sodass das Netzwerk sowohl feine als auch grobe Begrenzungen sieht. Ein Multi‑Feature‑Fusion‑Modul führt dann drei Ströme zusammen: die sich entwickelnden hochstufigen „Was ist diese Region?“-Informationen, die Rekonstruktion von Details durch den Decoder und die Kantenkarten. Anstatt sie einfach zu stapeln, verwendet das Modul einen aufmerksamsähnlichen Mechanismus, sodass semantische Merkmale die Kant‑ und Detailströme „befragen“ können, wo Grenzen und kleine Strukturen tatsächlich liegen, und die finale Repräsentation entsprechend anpassen.
Lokale Details mit globalem Kontext ausbalancieren
Ein weiteres Element des MFEF‑UNet ist ein Local‑Global‑Feature‑Enhancement‑Modul. Für Laien lässt sich das als der Teil des Netzes verstehen, der sicherstellt, dass man den Wald nicht aus den Augen verliert, während man die Bäume betrachtet — beziehungsweise die Stadt nicht, während man jedes Gebäude verfeinert. Das Bild wird in handhabbare Teilfenster aufgeteilt, sodass nahegelegene Pixel gemeinsam modelliert werden können und Formen sowie Texturen erhalten bleiben. Nach dieser lokalen Modellierung werden die Fenster zu einem Gesamtbild zusammengesetzt, und ein zweiter Durchlauf ermöglicht den Informationsfluss über entfernte Regionen hinweg. Dieser zweistufige Prozess hilft dem Modell, sowohl kleine Strukturen wie Autos und schmale Feldgrenzen als auch großskalige Muster wie Wohnblöcke oder zusammenhängende Wasserflächen zu respektieren.
Die Methode an Städten und Feldern beweisen
Die Forschenden testeten ihren Ansatz an drei öffentlich zugänglichen Datensätzen: zwei, die europäische Städte und Gemeinden abdecken, und einen großen Bestand landwirtschaftlicher Aufnahmen aus den Vereinigten Staaten. Diese Datensätze enthalten eine Mischung aus Dächern, Straßen, Vegetation, Wasser und feinen Erntemustern. Über alle drei Benchmarks hinweg lieferte MFEF‑UNet durchgängig genauere Karten als eine Reihe führender Methoden, darunter klassische Faltungsnetze, Transformer‑basierte Architekturen und neuere „State‑Space“‑Modelle. Seine Vorteile zeigten sich besonders an komplexen Gebäudeumrissen, Ansammlungen kleiner Objekte wie Fahrzeuge und langen, dünnen Strukturen wie Entwässerungsgräben oder Anbaureihen — Stellen, an denen andere Methoden dazu neigen, die Segmentierung zu fragmentieren oder zu verwischen.
Was das in der Praxis bedeutet
Praktisch verwandelt das vorgeschlagene Netzwerk Luftbilder in sauberere, verlässlichere Landbedeckungskarten. Stadtplaner können bebauten Raum genauer messen, Ingenieure können Straßen und Dächer besser nachverfolgen, und Agrarwissenschaftler können Felder, Wasserläufe und Bereiche mit Pflanzenstress präziser abgrenzen. Zwar bringen die hinzugefügten Kanten‑ und Fusionskomponenten etwas zusätzlichen Rechenaufwand mit sich, das Gesamtdesign bleibt jedoch verhältnismäßig effizient und erzielt deutliche Verbesserungen bei Genauigkeit und Robustheit. Für Nicht‑Spezialisten lautet die Erkenntnis: Indem Kanten bewusst betont und verschiedene visuelle Hinweise sorgfältig verschmolzen werden, können Computer Satelliten‑ und Drohnenaufnahmen mittlerweile mit schärferem Blick lesen — was uns näher an aktuelle, hochpräzise Karten der Welt bringt.
Zitation: Zhang, W., Yang, W., Yin, Y. et al. Multi-feature enhancement fusion network for remote sensing image semantic segmentation. Sci Rep 16, 5023 (2026). https://doi.org/10.1038/s41598-026-35723-y
Schlüsselwörter: Fernerkundung, semantische Segmentierung, Satellitenaufnahmen, Deep Learning, Landbedeckungskartierung