Clear Sky Science · de
Von Daten zu Entscheidungen: Der Einsatz erklärbarer KI zur Vorhersage der Sojabohnenerträge in den wichtigsten Produktionsländern
Warum bessere Ernteprognosen wichtig sind
Von Supermarktpreisen bis zum Welthandel spielt die unscheinbare Sojabohne im Alltag eine überraschend große Rolle. Regierungen, Händler und Landwirte müssen oft Monate vor der Ernte wissen, wie groß die Ernte ausfallen wird. Heute können leistungsfähige Werkzeuge der künstlichen Intelligenz (KI) Berge von Wetter- und Satellitendaten auswerten, um diese Prognosen zu erstellen – viele dieser Modelle agieren jedoch wie „Black Boxes“ und geben kaum Auskunft darüber, warum sie zu einer bestimmten Vorhersage kommen. Diese Studie untersucht eine neue Form erklärbarer KI, die nicht nur Sojabohnenerträge in den wichtigsten Anbauländern der Welt vorhersagt, sondern auch klar aufzeigt, welche Faktoren diese Vorhersagen antreiben.
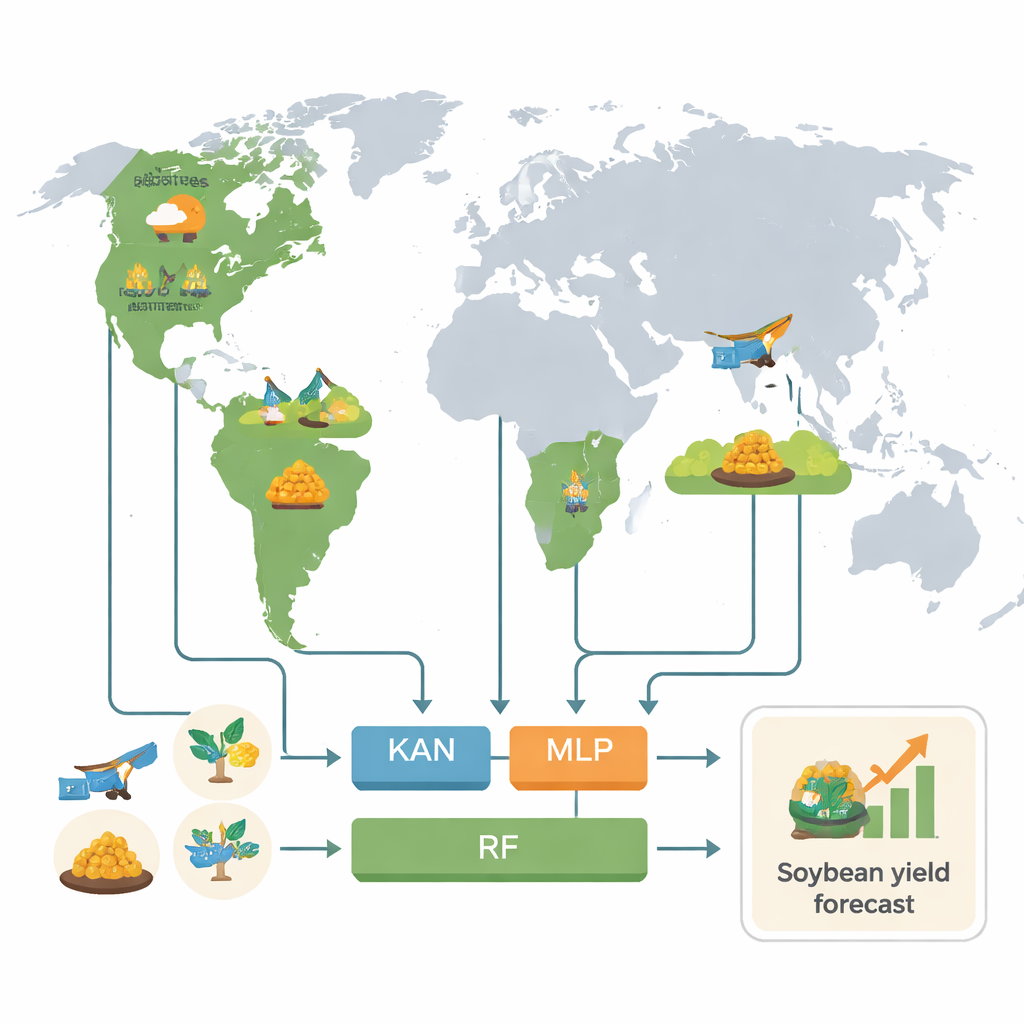
Drei Länder, die die Welt ernähren
Die Forschenden konzentrierten sich auf die drei Länder, die die globale Sojabohnenerzeugung dominieren: die Vereinigten Staaten, Brasilien und Argentinien, die zusammen mehr als 80 % der weltweiten Sojabohnen produzieren. Sie zoomten auf feiner Ebene hinein – Counties in den USA und äquivalente kleine Regionen in Brasilien und Argentinien – und nutzten aktuelle Daten aus den Jahren 2018 bis 2022. Für jede Region stellten sie ein umfangreiches Bild der Wachstumsbedingungen zusammen: detaillierte Wetteraufzeichnungen, Bodeneigenschaften und mehrere Arten von Satellitendaten, die Pflanzenwachstum, Wasserstatus und sogar ein schwaches Leuchten der Photosynthese messen, bekannt als solar-induzierte Chlorophyllfluoreszenz (SIF). Insgesamt wurden 154 verschiedene numerische Merkmale extrahiert, um jede Vegetationsperiode zu beschreiben, bevor sie in die Modelle eingespeist wurden.
Von Datenpipelines zu lernenden Maschinen
Um mit dieser Datenflut umzugehen, baute das Team eine standardisierte Verarbeitungspipeline. Sie brachten alle Datensätze räumlich und zeitlich mithilfe von Anbaukalendern in Übereinstimmung, glätteten verrauschte Satellitensignale und fassten die Vegetationsperiode mit Statistiken wie Mittelwerten, Extremen und Variabilität zusammen. Anschließend trainierten sie drei Modelltypen zur Ertragsvorhersage: Random Forest (RF), ein weit verbreitetes Machine-Learning-Arbeitspferd; Multilayer Perceptron (MLP), ein klassisches tiefes neuronales Netzwerk; und Kolmogorov–Arnold-Netzwerke (KAN), eine neuere Architektur, die von Grund auf darauf ausgelegt ist, besser interpretierbar zu sein. Um sich nicht durch zu optimistische Leistungswerte in die Irre zu führen, teilten die Autorinnen und Autoren die Daten sorgfältig in räumliche Blöcke, sodass die Modelle in Regionen getestet wurden, die sie während des Trainings nicht „gesehen“ hatten.
Die Black Box der KI öffnen
Was diese Arbeit auszeichnet, ist nicht nur die Genauigkeit der Vorhersagen, sondern auch, wie sich die Modelle erklären. RF und MLP wurden mit Standardwerkzeugen untersucht, die zeigen, wie wichtig jedes Eingabemerkmal für ihre Vorhersagen ist. KAN geht einen Schritt weiter: Es stellt die Verbindungen zwischen Eingaben und Ausgaben als glatte eindimensionale Kurven dar, die geplottet und inspiziert werden können. Das erlaubt Forschenden buchstäblich zu sehen, wie etwa eine Änderung der SIF oder der Bodenfeuchte den Ertrag nach oben oder unten beeinflusst. Länderübergreifend und über Methoden hinweg zeigte sich ein klares Muster – SIF, das Satellitensignal, das direkt mit der Photosynthese verbunden ist, gehörte konsequent zu den wichtigsten Prädiktoren für Sojabohnenerträge. Andere Schlüsselfaktoren variierten je nach Region: In den USA hoben sich wasserbezogene Vegetationssignale hervor, während in Brasilien und Argentinien Temperatur und Bodenfeuchte stärkere Rollen spielten.
Wie gut schnitten die Modelle ab?
Beim Vergleich der Modellgenauigkeit gewann keine Methode in jeder Situation klar. In den USA, wo die Erträge von Jahr zu Jahr relativ stabil waren, schnitt Random Forest insgesamt etwas besser ab, aber KAN und MLP lagen dicht dahinter. In Brasilien, mit volatileren Erträgen und einem größeren Datensatz, erreichten alle drei Modelle hohe Genauigkeit, obwohl sie bei der Vorhersage sehr hoher Erträge etwas Probleme hatten. In Argentinien, wo die Daten begrenzter waren, übertraf KAN im Allgemeinen die Deep-Learning-Baseline (MLP) und kam der Leistung des Random Forest nahe. Diese Ergebnisse deuten darauf hin, dass KAN traditionelle Modelle bei schwierigen, kleinen landwirtschaftlichen Datensätzen erreichen kann, während es zugleich deutlich mehr Transparenz darüber bietet, wie es zu seinen Schlussfolgerungen gelangt.
Was das für Landwirte und Ernährungssicherheit bedeutet
Für Entscheidungsträger in der Praxis kann das Vertrauen in ein Modell ebenso wichtig sein wie dessen bloße Genauigkeit. Diese Studie zeigt, dass erklärbare KI-Ansätze wie KAN wettbewerbsfähige Sojabohnenertragsprognosen liefern können und gleichzeitig klar offenlegen, welche Umwelt- und Pflanzenindikatoren am wichtigsten sind. Diese Sichtbarkeit hilft Wissenschaftlerinnen und Wissenschaftlern, Fehler zu diagnostizieren, agronomisches Expertenwissen zu integrieren und Modelle an neue Regionen oder veränderliche Klimabedingungen anzupassen. Langfristig könnten solche transparenten Werkzeuge in nationale Erntemonitoringsysteme eingebettet werden, um Landwirten, Planern und Märkten frühere und verlässlichere Warnungen vor schlechten Ernten oder Rekordernte zu geben – und so widerstandsfähigere und nachhaltigere Ernährungssysteme zu unterstützen.
Zitation: Wang, X., He, Y., Chen, H. et al. From data to decisions: the use of explainable AI to forecast soybean yield in major producing countries. Sci Rep 16, 5103 (2026). https://doi.org/10.1038/s41598-026-35716-x
Schlüsselwörter: Prognose der Sojabohnenerträge, erklärbare KI, Fernerkundung, landwirtschaftliche Modellierung, Ernährungssicherheit