Clear Sky Science · de
Transformer-unterstützter dualer Siamese-Tracker mit vertrauensbewusster Regression und adaptiver Template-Aktualisierung
Computern beibringen, einem Objekt in einer überfüllten Szene zu folgen
Von selbstfahrenden Autos über Überwachungskameras bis zu Drohnen müssen viele moderne Geräte ein einzelnes sich bewegendes Objekt in einer geschäftigen, sich verändernden Umgebung verfolgen. Diese Aufgabe, visuelle Objektverfolgung genannt, klingt für Menschen einfach, ist für Maschinen aber überraschend schwierig: Personen laufen vor die Kamera, Lichtverhältnisse ändern sich, das Objekt verkleinert sich in der Entfernung oder wird kurz verdeckt. Dieses Paper stellt TSDTrack vor, ein neues Tracking-System, das mit modernen Deep-Learning-Methoden und Transformern entwickelt wurde, um ein Ziel in solchen realen Bedingungen zuverlässiger im Blick zu behalten.
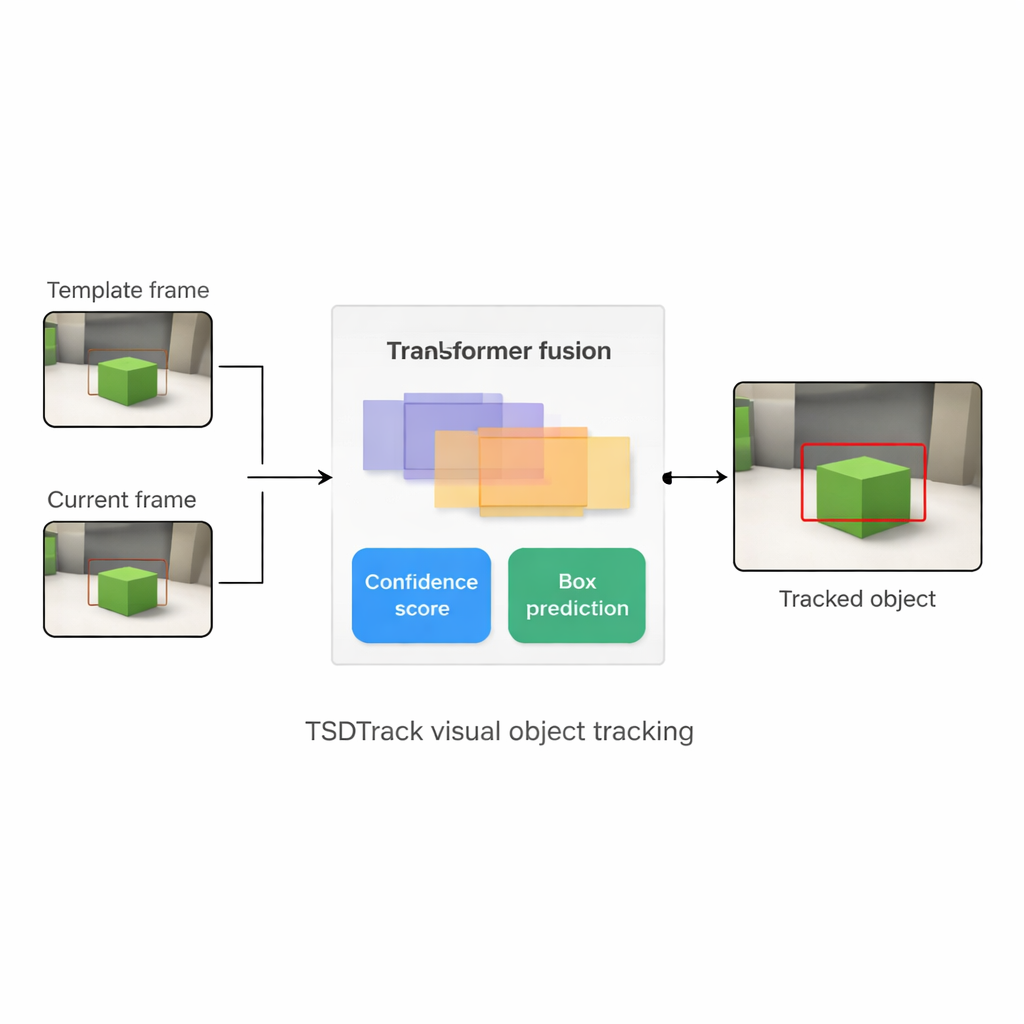
Warum das Folgen eines einzelnen Objekts so schwierig ist
Ein Tracker sieht das Objekt meist nur im ersten Frame klar und muss es dann wiederfinden, während sich die Szene verändert. Traditionelle Methoden setzten entweder auf handgefertigte Bildmerkmale oder auf ein neuronales Netz, das den ersten Frame (die „Template“) mit jedem neuen Frame verglich. Diese älteren Systeme hatten drei große Schwächen. Erstens hielten sie das ursprüngliche Template typischerweise unverändert, sodass der Tracker Probleme bekam, wenn sich das Objekt drehte, teilweise verdeckt wurde oder seine Größe änderte. Zweitens konzentrierten sie sich oft auf eine einzige Detailtiefe im Bild und verpassten so die Kombination aus feinen Kanten und weiterem Kontext, die Menschen beim Wiedererkennen hilft. Drittens wussten sie nicht, wann sie sich selbst infrage stellen sollten: Sie erzeugten eine Box um das vermeintliche Objekt, ohne klar anzugeben, wie verlässlich diese Vermutung ist, wodurch sie leicht auf den Hintergrund abdriften konnten.
Globalen Kontext mit feinen Details verbinden
TSDTrack begegnet diesen Problemen, indem es das klassische „Siamese“-Tracking-Setup mit einem Transformer kombiniert, dem auf Aufmerksamkeit basierenden Modell, das Sprache und Vision verändert hat. Das System nutzt ein tiefes Netzwerk, um Merkmale aus zwei Eingaben zu extrahieren: einem kleinen Patch, der das Ziel definiert, und einem größeren Patch, der das aktuelle Suchgebiet enthält. Statt sich auf nur eine Merkmalsebene zu stützen, zieht es Informationen aus mehreren Netzwerkschichten, die Kanten, Formen und Objektmuster repräsentieren. Ein transformer-basiertes Fusionsmodul lernt dann, wie diese Schichten gemischt werden, sodass der Tracker sowohl versteht, wo Dinge im Bild sind, als auch wie sie sich zum weiteren Kontext verhalten. Das hilft ihm, das Ziel von ähnlichen Objekten und Unordnung zu unterscheiden, selbst wenn die Ansicht verrauscht oder teilweise verdeckt ist.
Wissen, wie sicher der Tracker wirklich ist
Im Kern von TSDTrack steht ein dualer Vorhersagekopf, der die Aufgabe in zwei verwandte Fragen aufteilt: „Wo ist das Objekt?“ und „Wie sehr können wir dieser Antwort vertrauen?“. Ein Zweig schätzt einen Vertrauenswert, der nicht nur widerspiegelt, wie ähnlich das Ziel aussieht, sondern auch wie gut die vorhergesagte Box mit wahrscheinlichen Objektregionen überlappt. Der andere Zweig behandelt die Box-Koordinaten nicht als einzelne Vermutung, sondern als Wahrscheinlichkeitsverteilung über viele mögliche Positionen, sodass das Modell Unsicherheit darstellen kann. Wenn das Bild klar ist, wird die Verteilung scharf und die Box präzise; wenn das Objekt verschwommen oder teilweise verdeckt ist, dehnt sich die Verteilung aus. Diese probabilistische Sicht führt zu glatteren, stabileren Box-Platzierungen im Vergleich zu älteren Trackern, die eine einzelne starre Vorhersage trafen.
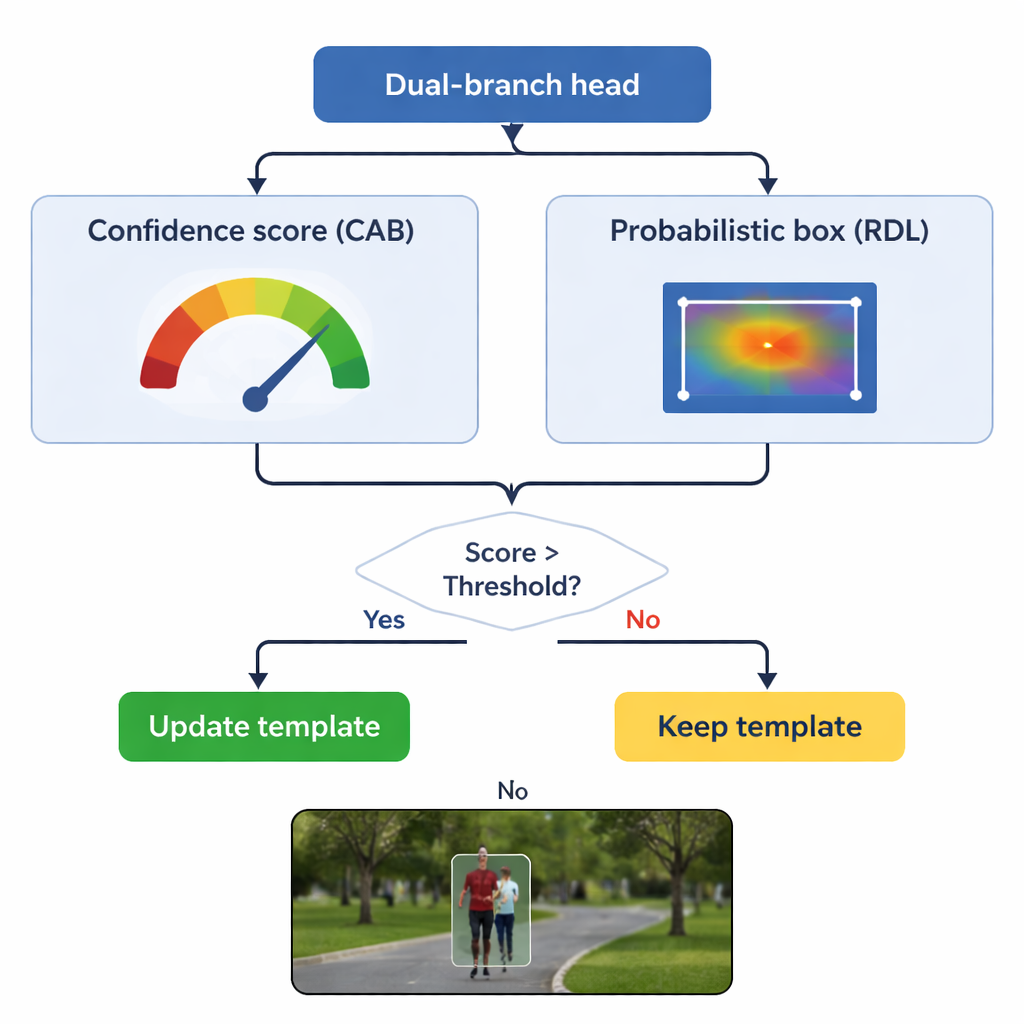
Speicher aktualisieren, ohne das Original zu vergessen
Eine zentrale Gefahr beim Tracking ist das „Template-Driften“: Wenn das Modell seine Vorstellung vom Objekt mit schlechten Frames weiter aktualisiert, kann es langsam den Hintergrund lernen. TSDTrack begegnet dem, indem sein Vertrauenszweig als Torwächter fungiert. Das System aktualisiert sein internes Template nur, wenn der Vertrauenswert einen festgelegten Schwellenwert überschreitet, und selbst dann mischt es neue Informationen behutsam mit der Originalansicht, anstatt sie vollständig zu ersetzen. Diese selektive Aktualisierung erlaubt es dem Tracker, sich an echte Veränderungen anzupassen, etwa wenn sich eine Person umdreht oder ein Auto rotiert, ohne durch momentane Verdeckungen oder Ablenkungen getäuscht zu werden. Das ursprüngliche Template wird außerdem als stabile Referenz zurückgehalten, falls spätere Updates sich als irreführend erweisen.
Was die Ergebnisse in der Praxis bedeuten
Die Autoren testeten TSDTrack auf mehreren weit verbreiteten Tracking-Benchmarks, darunter lange Videos, schnelle Bewegungen, Luftaufnahmen von Drohnen und Szenen mit starker Unordnung. In diesen Tests übertraf die neue Methode durchgehend viele führende Tracker sowohl in Genauigkeit (wie nah die Box am tatsächlichen Objekt liegt) als auch in Robustheit (wie selten das Objekt vollständig verloren wird), und lief dabei noch schnell genug für den Echtzeitbetrieb auf moderner Hardware. Für Nicht-Spezialisten lautet die Schlussfolgerung: TSDTrack kann ein gewähltes Ziel in den unübersichtlichen Bedingungen realer Kameras zuverlässiger im Blick behalten. Durch die Kombination aus mehrskaliger Transformer-Reasoning, einem Gefühl für die eigene Vertrauenswürdigkeit und sorgfältiger Template-Aktualisierung bietet es einen vertrauenswürdigeren Baustein für Anwendungen wie autonomes Fahren, intelligente Überwachung und autonome Roboter.
Zitation: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
Schlüsselwörter: visuelle Objektverfolgung, transformer-basierte Verfolgung, Siamese-Netzwerke, Computer Vision, autonome Systeme