Clear Sky Science · de
Ein satellitenbasiertes Machine‑Learning‑Verfahren zur Schätzung hochauflösender täglicher mittlerer Lufttemperaturen in einer Megastadt in Brasilien
Warum es in der Stadt nicht überall gleich heiß ist
An einem heißen Tag in einer Großstadt kann die Temperatur, die Sie in einer baumbestandenen Straße fühlen, sehr unterschiedlich sein von derjenigen, die jemand auf einem betonierten Platz wenige Blocks entfernt erlebt. Trotzdem behandeln die meisten Gesundheits‑ und Klimastudien eine ganze Stadt noch immer so, als hätte sie eine einzige Temperatur. Diese Arbeit zeigt, wie Wissenschaftler Satelliten, Wettermodelle und Machine Learning nutzten, um tägliche Temperaturen in São Paulo, Brasilien, detailliert zu kartieren — und damit offenzulegen, wer tatsächlich gefährlicher Hitze ausgesetzt ist und wo Kühlmaßnahmen am dringendsten nötig sind.
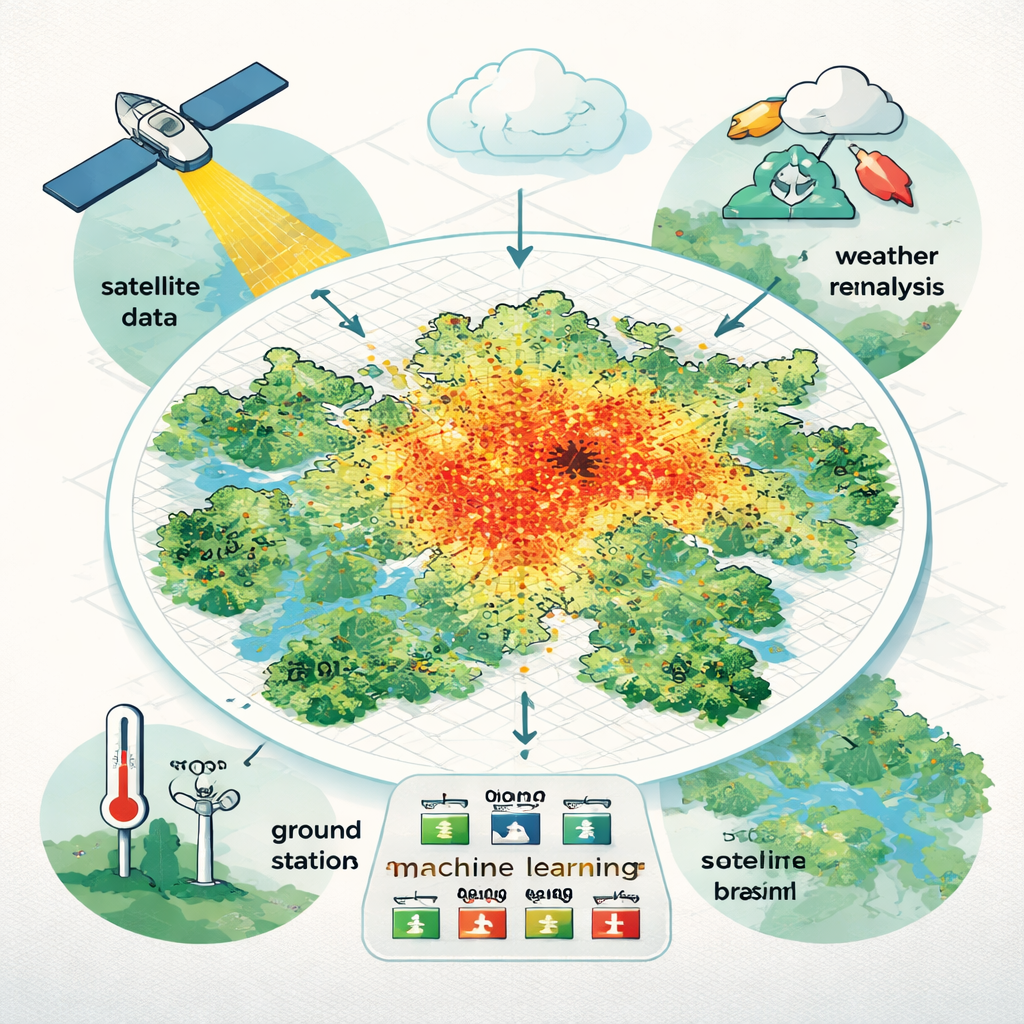
Die Temperatur der Stadt in hoher Auflösung messen
Traditionelle Temperaturaufzeichnungen stützen sich auf eine begrenzte Anzahl von Wetterstationen, die oft in der Nähe von Flughäfen oder wohlhabenderen Bezirken konzentriert sind. Dadurch ist es schwierig zu erkennen, wie sich die Hitze in den realen Stadtvierteln verteilt, insbesondere in großen Städten und in Ländern mit niedrigem und mittlerem Einkommen, wo Überwachungsnetze dünn sind. Die Forscher konzentrierten sich auf São Paulo, eine riesige und sehr heterogene Megastadt mit mehr als 22 Millionen Menschen. Ihr Ziel war es, die tägliche mittlere Lufttemperatur für jedes 500-mal-500-Meter‑Feld im Metropolgebiet über fünf Jahre hinweg, von 2015 bis 2019, zu schätzen und damit einen der detailliertesten stadtweiten Temperatursätze in Südamerika zu erstellen.
Satelliten, Wettermodelle und Bodensensoren verbinden
Um dieses hochauflösende Bild zu erstellen, kombinierte das Team verschiedene frei verfügbare Datentypen. Sie sammelten Messungen von 48 Bodenstationen, die die direktesten Lufttemperaturmessungen liefern, jedoch nur an einzelnen Punkten. Zusätzlich nutzten sie Satellitenbeobachtungen der Bodentemperatur, des Sonnenwinkels und der Bodenreflexion sowie Informationen zu Luftfeuchtigkeit, Wind und Druck aus einem globalen Wetter‑„Reanalyse“‑Produkt, das stündliche Wetterdaten auf einem groben Gitter rekonstruiert. Diese Daten wurden so auf das 500‑Meter‑Raster resamplet und bereinigt, dass Lücken durch Wolken oder fehlende Satellitenüberflüge gefüllt werden konnten. Insgesamt testeten sie 23 mögliche Prädiktorvariablen, die helfen könnten, räumliche und zeitliche Hitzevariationen zu erklären.
Ein Lernmodell trainieren, das die Hitze liest
Anstelle einer einfachen Geradengleichung (linear) griffen die Wissenschaftler zu einem Random Forest, einer verbreiteten Machine‑Learning‑Methode, die viele Entscheidungsbäume erzeugt und deren Ergebnisse mittelt. Dieser Ansatz eignet sich gut, um komplexe, nichtlineare Zusammenhänge aufzudecken, etwa wie die Temperatur in verschiedenen Stadtteilen oder Jahreszeiten unterschiedlich auf Oberflächenerwärmung, Luftfeuchte und Wind reagiert. Um ein Überanpassen an die Eigenheiten weniger Stationen zu vermeiden, verwendeten sie einen schrittweisen Merkmalsauswahlprozess, der nur Variablen beibehält, die die Vorhersage tatsächlich verbessern. Das Modell validierten sie auf zwei Arten: durch wiederholtes Auslassen von Stationengruppen während des Trainings und durch Zurückhalten von fünf gesamten Stationen als strengen externen Test, wie gut das Modell an neuen Orten funktioniert.
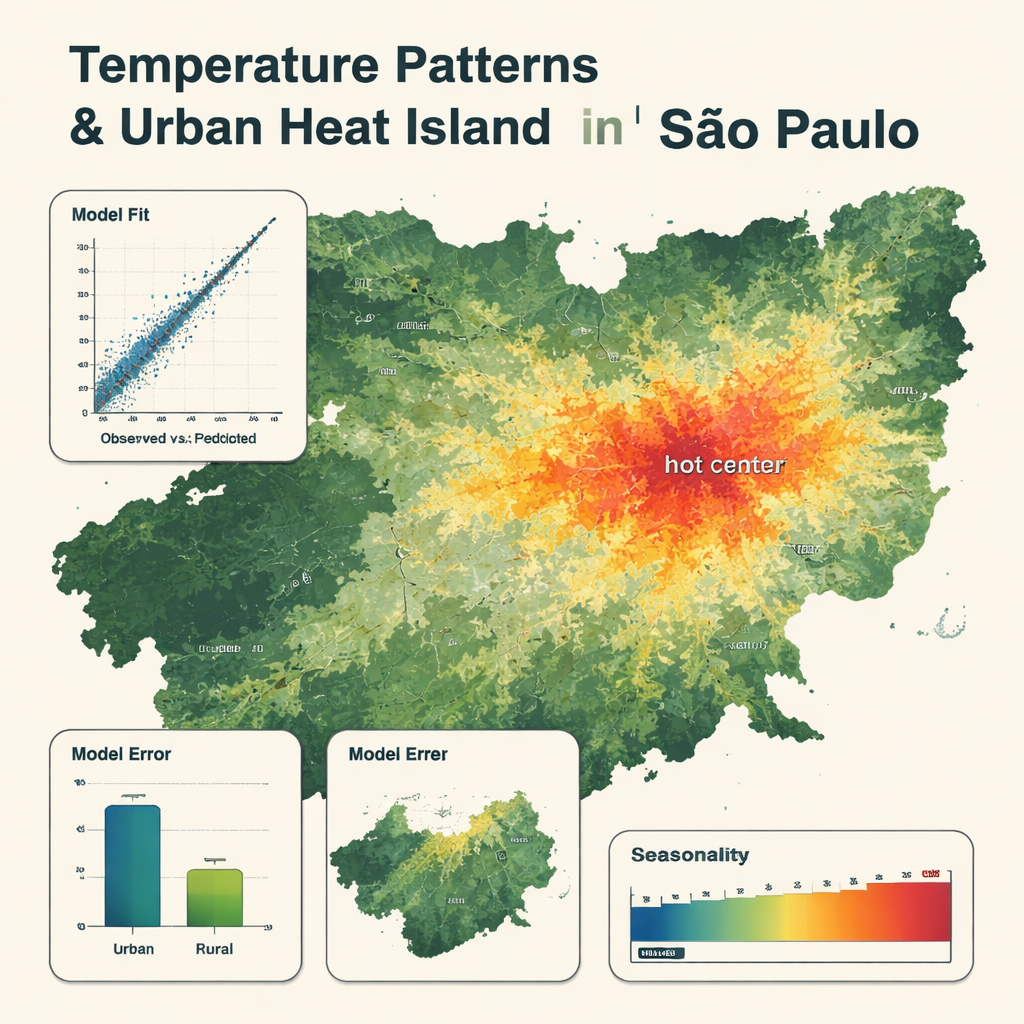
Was die detaillierten Karten zeigen
Das finale Modell verwendete nur acht Schlüsselvariablen, angeführt von der Lufttemperatur aus dem globalen Wetterprodukt; auch Satelliten‑Bodentemperatur und Luftfeuchte spielten wichtige Rollen. Es reproduzierte die Stationsmessungen sehr genau, mit einem mittleren Fehler von etwa 0,8 °C und einer sehr hohen Übereinstimmung zwischen beobachteten und vorhergesagten Temperaturen. Die Karten zeigen deutliche Muster: kühlere Bereiche über Wäldern, Bergen und großen Reservoirs und heißere Zonen im dichten, bebauten Stadtzentrum, wo die Temperaturen bis zu 5 °C höher sein können als in nahegelegenen ländlichen Gebieten. Das Modell erfasste saisonale Schwankungen, mit den heißesten Bedingungen von Dezember bis März und den kühlsten von Mai bis August. Es war in ländlicheren Gebieten etwas ungenauer und tendierte dazu, die extremsten heißen und kalten Tage zu glätten, übertraf aber dennoch ein traditionelleres multipel‑lineares Regressionsmodell mit denselben Eingaben.
Warum diese Karten für die Gesundheit der Menschen wichtig sind
Indem verstreute Messungen und Satellitenaufnahmen in tägliche, straßenskalige Temperaturschätzungen verwandelt werden, liefert diese Arbeit ein mächtiges neues Werkzeug für Gesundheitsforschung und Stadtplanung in São Paulo und darüber hinaus. Forschende können jetzt untersuchen, wie Hitze verschiedene Viertel betrifft, einschließlich informeller Siedlungen, die in offiziellen Aufzeichnungen oft fehlen, und ermitteln, wo Bewohner während Hitzewellen am stärksten gefährdet sind. Da die Methode vollständig auf offenen Daten und Standardsoftware beruht, lässt sie sich auf andere Städte übertragen, die über einige Bodenstationen und vergleichbare Satellitenabdeckung verfügen. Kurz gesagt zeigt die Studie, dass wir urbane Hitze nun mit viel feinerer Detailgenauigkeit „sehen“ können und damit eine wichtige Grundlage für gerechtere, gezieltere Anpassungsmaßnahmen und den Schutz vulnerabler Gemeinschaften schaffen.
Zitation: Roca-Barceló, A., Schneider, R., Pirani, M. et al. A satellite based machine learning approach for estimating high resolution daily average air temperature in a megacity in Brazil. Sci Rep 16, 7459 (2026). https://doi.org/10.1038/s41598-026-35689-x
Schlüsselwörter: städtische Hitze, Machine Learning, Satellitendaten, São Paulo, Lufttemperatur