Clear Sky Science · de
Echtzeit-Erkennung von Phishing-Angriffen durch maschinelles Lernen in Browser‑Erweiterungen
Warum gefälschte Websites ein Problem für alle sind
Jeden Tag erhalten Menschen Nachrichten, die so aussehen, als kämen sie von ihrer Bank, einem Paketdienst oder dem Arbeitgeber – aber manche davon sind sorgfältig ausgelegte Fallen. Phishing‑Betrug nutzt täuschend echte E‑Mails und Websites, um Passwörter, Kreditkartendaten und andere persönliche Informationen zu stehlen. Da Kriminelle immer geschickter echte Seiten nachahmen, reichen einfache Blocklisten und Bauchgefühl nicht mehr aus. Dieser Artikel beschreibt ein neues Browser‑Add‑on, das unauffällig die besuchten Seiten überwacht und mit Hilfe von maschinellem Lernen gefährliche Seiten in Echtzeit markiert. Ziel ist es, normalen Nutzern starken Schutz zu bieten, ohne dass sie zu Sicherheitsexperten werden müssen.
Wie moderne Phishing‑Angriffe uns täuschen
Phishing hat sich zu einer der verbreitetsten Online‑Straftaten weltweit entwickelt und ist für einen großen Anteil gemeldeter Cybervorfälle und finanzieller Verluste verantwortlich. Angreifer versenden überzeugende E‑Mails, die zu schnellem Handeln drängen – „verifizieren Sie Ihr Konto“, „aktualisieren Sie Ihre Zahlung“, „verfolgen Sie Ihr Paket“ – und leiten Opfer auf gefälschte Websites, die echten Bank‑, Einkaufs‑ oder Cloud‑Service‑Seiten stark ähneln. Viele dieser Seiten verwenden inzwischen gültige HTTPS‑Zertifikate und gepflegte Designs, sodass altmodische Warnsignale wie „kein Vorhängeschloss“ oder „hässliche Seite“ nicht mehr greifen. Umfragen und Kriminalitätsberichte zeigen, dass vor allem Erwachsene in den 20ern bis 40ern stark ins Visier geraten, und Sicherheitsteams bleiben besorgt über E‑Mail‑basierte Betrügereien, die Filter umgehen.
Ein schlauer Blick auf Webadressen und Seitenaufbau
Die Forschenden argumentieren, dass der sicherste Ort, Phishing zu stoppen, direkt im Browser liegt – in dem Moment, in dem eine Seite geladen wird. Ihre Erweiterung für Google Chrome (und kompatible Browser) prüft zwei zentrale Hinweise: die Webadresse selbst und das Erscheinungsbild der Seite. Von jeder Seite sammelt sie „lexikalische“ Details der URL, wie Länge, ungewöhnliche Zeichen oder verdächtige Subdomains; „strukturelle“ und Domain‑Details wie Traffic und Registrierungsdaten; sowie „visuelle“ Hinweise wie Layout‑Blöcke, Farben und Logos. Ein Headless‑Browser rendert jede Seite kontrolliert, zerlegt sie in rechteckige Regionen und protokolliert, wo Formulare, Logos und Navigationsleisten erscheinen. Anschließend vergleicht das System diesen visuellen Fingerabdruck mit denen vertrauenswürdiger Seiten, um Nachahmungen zu erkennen, die betrügerisch sein könnten.
Digitale „Wölfe“ wählen die aussagekräftigsten Merkmale
Weil das System von jeder Seite Dutzende Messwerte sammelt, muss es entscheiden, welche tatsächlich helfen, Betrug von sicheren Seiten zu trennen. Dafür übernehmen die Autor:innen einen Algorithmus, der vom Jagdverhalten grauer Wölfe inspiriert ist. In diesem „Grey Wolf Optimizer“ treten viele Kandidaten‑Merkmalsmengen gegeneinander an, und der Algorithmus konvergiert schrittweise auf eine kompakte Teilmenge, die das beste Gleichgewicht zwischen Erkennungsrate und Fehlalarmen liefert. Diese ausgewählten Merkmale werden dann in drei Machine‑Learning‑Modelle eingespeist – Support Vector Machine, Decision Tree und vor allem Random Forest, das viele Entscheidungsbäume zu einem starken Ensemble vereint. Das Training nutzt 80.000 Websites aus öffentlichen Sammlungen wie PhishTank und akademischen Archiven, ergänzt durch Techniken, um das Ungleichgewicht zwischen legitimen und bösartigen Seiten zu behandeln.
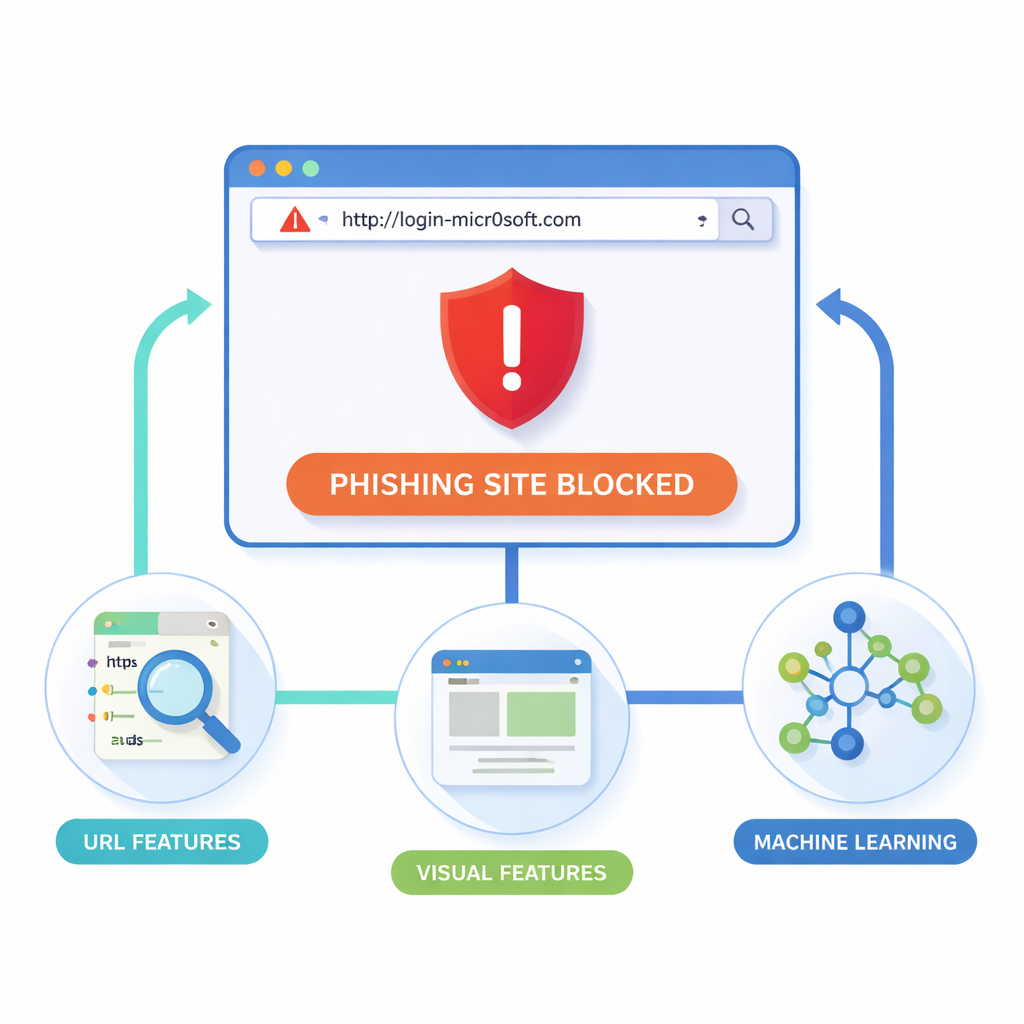
Labor‑Modelle in ein nützliches Browser‑Tool überführen
Das optimierte Random‑Forest‑Modell erreichte etwa 98–99 % Genauigkeit und einen Matthews‑Korrelationskoeffizienten nahe 0,96, eine strenge Metrik, die sowohl verpasste Angriffe als auch Fehlalarme berücksichtigt. In Live‑Tests mit einer Chrome‑Erweiterung scannte das System jede URL in rund 200 Millisekunden, schnell genug, dass Nutzer keine Verzögerungen bemerkten. Wenn eine riskante Seite erkannt wurde, zeigte das Add‑on eine klare Warnung und ließ Nutzer entscheiden, ob sie zurückkehren oder auf eigenes Risiko fortfahren möchten. Im Vergleich zu populären Tools wie Google Safe Browsing und bestehenden Anti‑Phishing‑Erweiterungen wies das neue System höhere Erkennungsraten, weniger Fehlwarnungen und die Fähigkeit auf, irreführende Adressen zu erkennen – selbst wenn diese verkürzt, leicht verschleiert oder neu erstellt waren.
Was das für das tägliche Surfen bedeutet
Für Nicht‑Spezialisten lautet die zentrale Erkenntnis, dass Phishing‑Schutz nicht länger ausschließlich auf Vermutungen oder manuelle Blacklists angewiesen sein muss. Indem Schreibeweise eines Links und das Seitenbild kombiniert sowie automatisch die informativsten Signale ausgewählt werden, kann die vorgeschlagene Erweiterung viele Betrugsfälle beim ersten Auftreten erkennen, nicht erst nachdem jemand sie gemeldet hat. Die Autor:innen räumen ein, dass Angreifer sich weiterentwickeln werden und Modelle neu trainiert sowie auf Telefone und andere Browser ausgeweitet werden müssen. Dennoch zeigt ihre Arbeit, dass ein intelligentes, datenschutzschonendes Add‑on auf dem eigenen Gerät als unermüdliches zweites Paar Augen fungieren kann – es prüft still jede besuchte Seite und greift ein, wenn etwas nicht stimmt, lange bevor ein übereilter Klick zu einem teuren Fehler wird.
Zitation: Dandotiya, M., Goyal, N., Khunteta, A. et al. Real time identification of phishing attacks through machine learning enhanced browser extensions. Sci Rep 16, 6612 (2026). https://doi.org/10.1038/s41598-026-35655-7
Schlüsselwörter: Phishing-Erkennung, Browser-Erweiterung, Maschinelles Lernen, Cybersicherheit, gefälschte Websites