Clear Sky Science · de
Visuell geführte KI-Farbkunst-Bildgenerierung mit verbessertem GAN
Warum klügere Kunstmaschinen wichtig sind
Digitale Werkzeuge können inzwischen Porträts, Landschaften und abstrakte Szenen in Sekunden malen, doch viele dieser KI-Kunstwerke wirken noch leicht fehl am Platz: Farben stören sich, Texturen erscheinen flach oder der „Stil“ entspricht nicht ganz der menschlichen Vorstellung. Dieses Paper stellt eine neue Methode vor, Computern beizubringen, Farbkunstwerke zu erzeugen, die reicher, kohärenter und näher an echten Gemälden sind, während Nutzer das Ergebnis mit einfachen visuellen Hinweisen wie Skizzen und Farbvorgaben beeinflussen können. Ziel ist es, KI zu einem verlässlicheren kreativen Partner für Künstler, Designer und Alltagsanwender zu machen, die personalisierte Kunst wollen, ohne jahrelange Ausbildung zu benötigen.
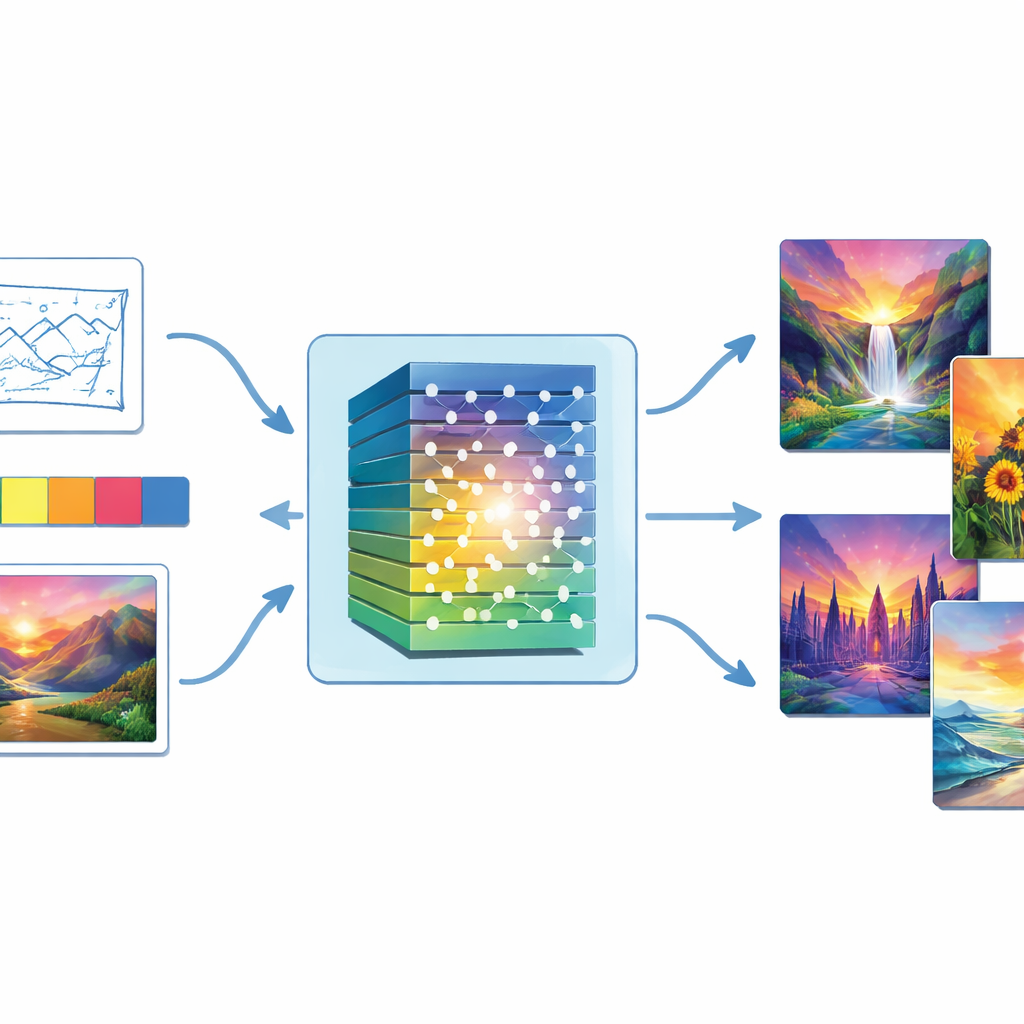
Vom zufälligen Rauschen zum fertigen Gemälde
Im Kern der Studie steht eine Art KI, die als Generative Adversarial Network oder GAN bezeichnet wird. Ein GAN besteht aus zwei gegensätzlichen Teilen: einem „Generator“, der versucht, aus zufälligem Rauschen überzeugende Bilder zu erzeugen, und einem „Diskriminator“, der beurteilt, ob ein Bild echt oder künstlich wirkt. Durch viele Trainingsrunden im Wechsel wird der Generator besser darin, den Diskriminator zu täuschen, und die Bilder werden nach und nach lebensechter. Die Autoren stärken diese Grundidee, indem sie einen tiefen Bildverarbeitungs-Stack — ein konvolutionales neuronales Netzwerk — sowohl in den Generator als auch in den Diskriminator einbauen, sodass das System besser alles erfasst, von groben Formen bis hin zu feinen pinselähnlichen Details.
Dem System beibringen, wohin es schauen soll
Während Standard-GANs scharfe Bilder erzeugen können, übersehen sie oft das große Ganze: Sie legen möglicherweise zu viel Gewicht auf kleine Details und verlieren die globale Struktur oder halten einen konsistenten künstlerischen Stil nicht ein. Um dem entgegenzuwirken, fügt das Team einen adaptiven Aufmerksamkeitsmechanismus hinzu. Dieses Modul analysiert die internen Merkmalskarten des Generators und lernt während des Trainings, welche Bereiche eines Bildes in jedem Moment am wichtigsten sind. Es verstärkt dann diese Schlüsselregionen — etwa Kanten, Texturen und Fokusobjekte — und schwächt weniger wichtige Hintergrundzonen ab. Spezielle Verlustmaße verfolgen, wie gut das erzeugte Bild Stil und Textur eines Zielkunstwerks trifft, und treiben das Modell dazu, erkennbaren Inhalt mit einem kohärenten künstlerischen Erscheinungsbild in Einklang zu bringen.
Die Maschine mit visuellen Hinweisen lenken
Im Gegensatz zu rein textbasierten Systemen erlaubt dieser Ansatz den Nutzern, das Kunstwerk mit direkter visueller Führung zu steuern. Nutzer können eine Skizze zur Festlegung der Komposition, eine Farbpalette zur Stimmungsvorgabe, ein Beispielbild zum Nachahmen oder einfache Szenentags eingeben. Diese Eingaben gelangen zusammen mit dem Zufallsrauschen in den Generator. Das Modell berechnet dann Farbeigenschaften wie Farbton, Sättigung und Helligkeit und passt seine Ausgabe so an, dass das endgültige Gemälde sowohl die Farbintentionen des Nutzers als auch den Referenzstil respektiert. Ein farbabstimmendes Zielmaß verstärkt die Verbindung zwischen der Nutzerangabe und dem Ergebnis, sodass etwa eine kühle blaue Meereslandschaft nicht unerwartet in einen warmen Sonnenuntergang übergeht.
Durch Versuch und Irrtum besser werden
Das System geht einen Schritt weiter und nutzt Deep Reinforcement Learning, eine Technik, die vom Lernen durch Versuch und Irrtum inspiriert ist. Hier behandelt ein separates Entscheidungsmodul die Differenz zwischen der aktuellen Ausgabe und der Zielvorgabe als seinen „Zustand“ und schlägt kleine Anpassungen an Elementen wie Skizzenstärke oder Palettengewichten als „Aktionen“ vor. Nach jeder Änderung misst das System, wie stark sich wichtige Bildqualitätswerte verbessern — etwa Peak Signal-to-Noise Ratio, strukturelle Ähnlichkeit und Stilverlust — und verwendet dies als Belohnungssignal. Mit der Zeit lernt diese Schleife eine Politik, die die Vorgaben automatisch feinjustiert, um den Generator zu Bildern zu führen, die sowohl visuell treu als auch künstlerisch konsistent sind.
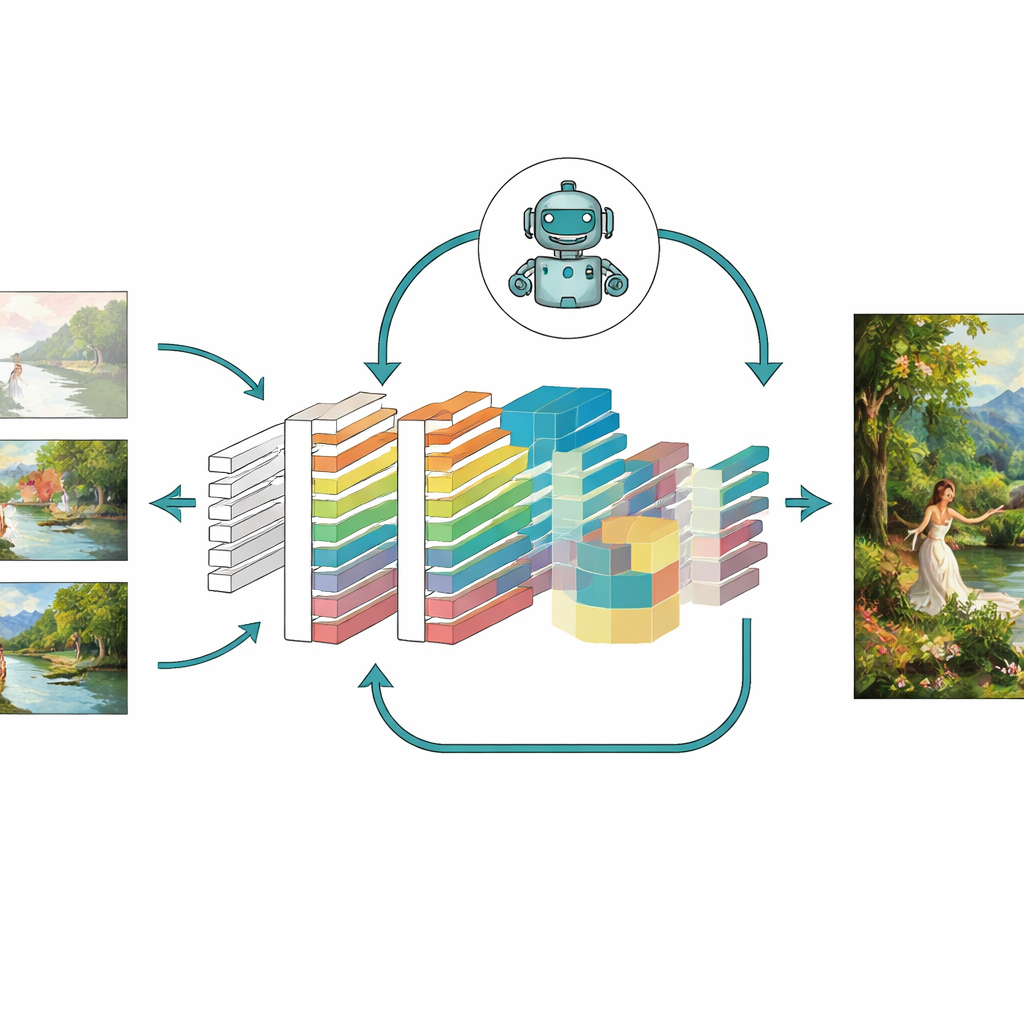
Das Modell auf die Probe stellen
Um zu beurteilen, ob diese Ideen tatsächlich helfen, testeten die Autoren ihr erweitertes Modell — genannt CNN-GAN — an einer großen Gemäldesammlung der University of Oxford und an einem eigenen Datensatz von mehr als 5.000 Farbkunstwerken in Stilen wie Porträts, Landschaften und abstrakten Szenen. Sie verglichen die Ergebnisse mit mehreren bekannten Systemen, darunter klassische GAN-Varianten, Autoencoder und sogar moderne, auf Diffusion basierende Generatoren. Über viele Metriken hinweg erzeugte das neue Modell schärfere Bilder mit weniger Artefakten, eine nähere strukturelle Übereinstimmung mit echten Kunstwerken, geringere wahrnehmungsbezogene Distanz zu Zielbildern und größere Vielfalt in den erzeugbaren Szenentypen. Ablationsstudien, bei denen jeweils ein Modul entfernt wurde, zeigten, dass Aufmerksamkeit, Reinforcement Learning und das kombinierte Verlustdesign jeweils bedeutende Verbesserungen beitrugen und zusammen die beste Leistung lieferten.
Was das für zukünftige Kreativwerkzeuge bedeutet
Alltäglich formuliert beschreibt das Paper eine Malmaschine, die nicht nur aus Tausenden von Kunstwerken lernt, sondern auch wichtigen Regionen besondere Aufmerksamkeit schenkt, auf visuelle Hinweise der Nutzer hört und sich schrittweise selbst beibringt, wie sie diese Hinweise besser anpassen kann. Das Ergebnis ist eine KI, die zuverlässiger hochqualitative, stilistisch einheitliche Bilder erzeugen kann als frühere Methoden, dabei aber weiterhin Raum für menschliche Steuerung lässt. Obwohl das System bei extrem feinen Texturen noch Schwierigkeiten hat und auf umfangreiche Trainingsdaten angewiesen ist, schlagen die Autoren künftige Erweiterungen vor — etwa Mehrskalenmodule und leichtergewichtige Netzwerke — um es effizienter und breiter einsetzbar zu machen. Zusammengenommen deuten diese Fortschritte auf KI-Kunstwerkzeuge hin, die schneller sind, die Nutzerabsicht treuer umsetzen und den feinen Charakter handgemachter Gemälde besser einfangen können.
Zitation: Wu, Z. Visual guided AI color art image generation using enhanced GAN. Sci Rep 16, 9345 (2026). https://doi.org/10.1038/s41598-026-35625-z
Schlüsselwörter: KI Kunstgenerierung, Bildstil-Transfer, generative gegnerische Netzwerke, künstliche Kreativität, neuronale Bildsynthese