Wann immer Regierungen, Wissenschaftler oder Meinungsforscher etwas über eine gesamte Population erfahren wollen – etwa den durchschnittlichen Einkommen, Ernteertrag oder Schadstoffgehalt – können sie kaum jede einzelne Person messen. Stattdessen ziehen sie eine Stichprobe und skalieren hoch. Das funktioniert nur dann gut, wenn sich die Daten gutartig verhalten. In der Praxis sind Umfragen und Messungen jedoch häufig von Fehlern und extremen Werten durchsetzt, die Ergebnisse stark verzerren können. Dieser Artikel stellt eine neue Methode zur Berechnung von Populationsdurchschnitten vor, die auch bei unordentlichen Daten zuverlässig bleibt und damit auf Stichproben basierende Entscheidungen vertrauenswürdiger macht.
Wenn einfache Durchschnitte versagen
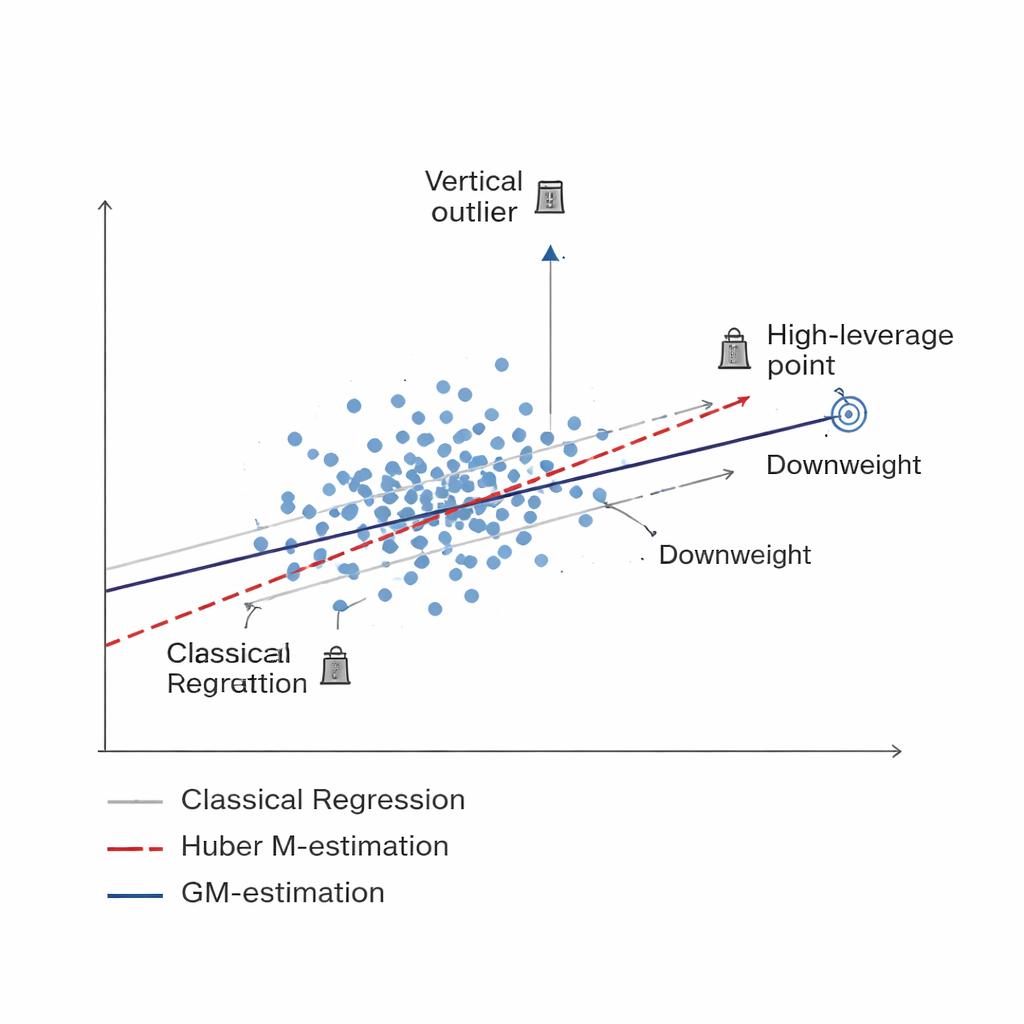
Standardwerkzeuge zur Schätzung eines Populationsmittels, wie das einfache Stichprobenmittel oder die gewöhnliche Regression, setzen voraus, dass die meisten Datenpunkte glatten Mustern folgen, ohne extreme Ausreißer oder ungewöhnliche Fälle. In sozialen und wirtschaftlichen Umfragen, der Umweltüberwachung und der Agrarstatistik wird diese Annahme oft nicht erfüllt. Einige fehlerhafte Messwerte, seltene aber extreme Ereignisse oder falsch gemeldete Antworten können Schätzungen vom wahren Wert wegziehen und sowohl Verzerrung als auch Unsicherheit erhöhen. Frühere Arbeiten versuchten, den Einfluss solcher Ausreißer mit sogenannten robusten Methoden abzumildern, darunter ein populärer Ansatz namens Huber‑M‑Schätzung. Diese Methoden helfen zwar, schützen aber hauptsächlich vor extremen Werten der Zielgröße und bleiben gegenüber ungewöhnlichen Mustern in den begleitenden Erklärungsvariablen anfällig.
Eine intelligentere Art, schlechte Daten zu reduzieren Figure 1.
Die Studie entwickelt eine neue Familie von Schätzern, die auf der generalisierten M‑Schätzung (GM‑Schätzung) beruht. Anstatt jede Stichprobeneinheit gleich zu behandeln, weisen GM‑Methoden adaptive Gewichte zu, die gleichzeitig von zwei Faktoren abhängen: wie extrem die Antwort einer Einheit ist (vertikaler Ausreißer) und wie ungewöhnlich ihre zugehörigen Informationen sind (High‑Leverage‑Punkt). Drei konkrete Varianten – Mallows‑GM, Schweppes‑GM und SIS‑GM – sind für gängige Stichprobenkonfigurationen entworfen, einschließlich einfacher Zufallsstichproben ohne Zurücklegen und komplexerer geschichteter Designs, bei denen die Population in relativ homogener Gruppen aufgeteilt ist. Durch die gemeinsame Kontrolle beider Arten problematischer Beobachtungen zielen diese Schätzer darauf ab, die endgültige Schätzung des Populationsmittels stabil zu halten, selbst wenn die Daten stark kontaminiert sind.
Die neuen Schätzer im Test
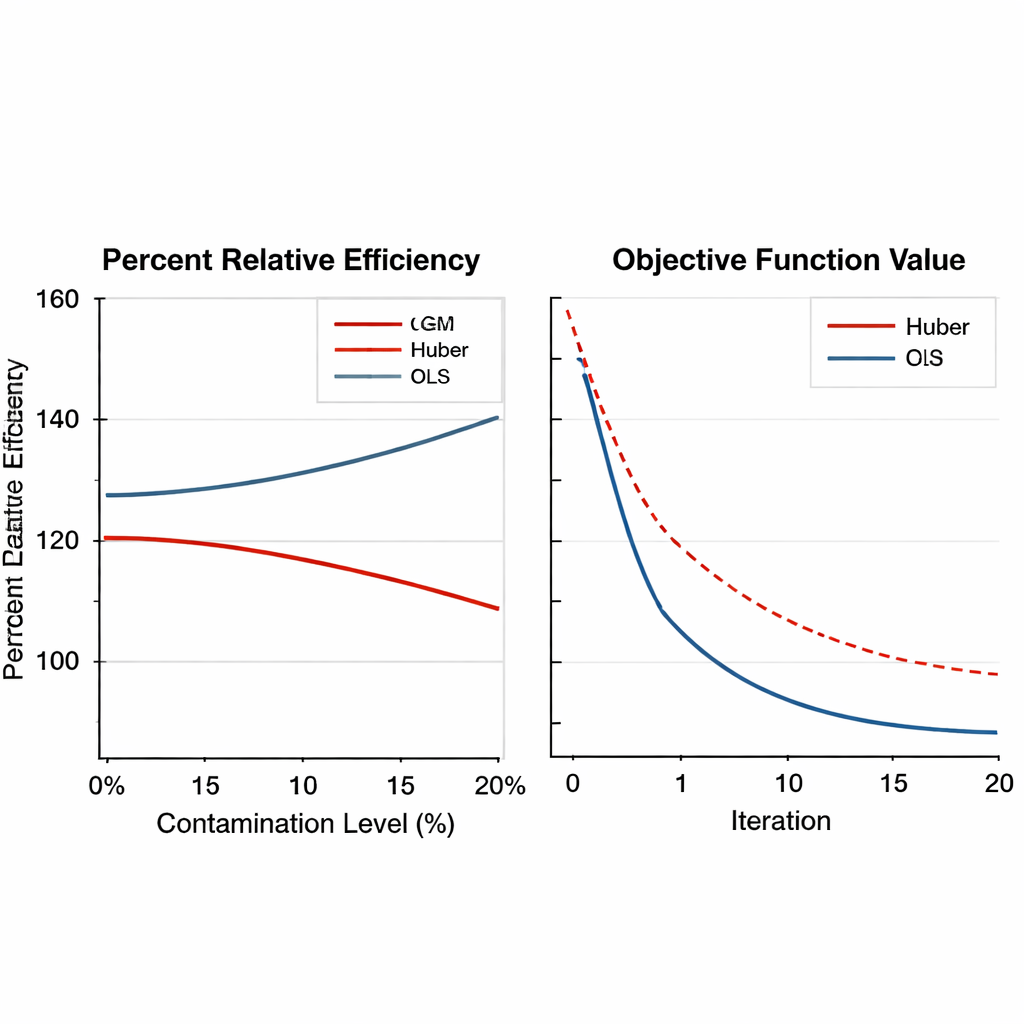
Um die Leistungsfähigkeit der GM‑basierten Schätzer zu prüfen, führt der Autor umfangreiche numerische Experimente durch. Zunächst werden reale Daten aus dem Tabakanbau in zwei Formen analysiert: eine saubere Version und eine absichtlich kontaminierte Version, in der eine Einheit durch extreme Werte ersetzt wurde. Die neuen Schätzer werden mit traditioneller Regression und Huber‑basierten robusten Verfahren verglichen, mithilfe einer Kennzahl namens prozentuale relative Effizienz, die widerspiegelt, um wie viel kleiner der Schätzfehler ist. Über eine breite Palette von Stichprobengrößen schneiden die GM‑Schätzer durchweg besser ab als die älteren Methoden, insbesondere wenn die Daten extreme Werte enthalten. In einigen Szenarien reduziert der am besten abschneidende GM‑Schätzer den Fehler um mehr als 50 Prozent im Vergleich zum Huber‑Ansatz.
Robustheit über Designs, Einstellungen und Abstimmungsvarianten hinweg Figure 2.
Das Papier erweitert die Tests anschließend mit groß angelegten Computersimulationen. Künstliche Populationen werden unter mehreren Verteilungen erzeugt – normal, schief und schwerer Schwanz – und mit variierenden Anteilen an Ausreißern kontaminiert, von keinem bis zu 20 Prozent. Es werden sowohl einfache als auch geschichtete Stichpläne betrachtet, und die Stärke der Beziehung zwischen der Zielvariable und ihren Hilfsvariablen variiert von schwach bis stark. Die GM‑Schätzer behalten nicht nur ihren Vorsprung bei starker Kontamination bei, oft mit Effizienzgewinnen über 150 Prozent, sondern zeigen auch eine glatte und verlässliche numerische Konvergenz. Wichtig ist, dass sich ihre Leistung kaum verändert, wenn die internen Abstimmungsparameter innerhalb vernünftiger Bereiche angepasst werden, was bedeutet, dass Anwender sie nicht für jede neue Umfrage fein justieren müssen.
Was das für praktische Umfragen bedeutet
Kurz gesagt zeigt der Artikel, dass die vorgeschlagenen GM‑basierten Schätzer eine sicherere Methode bieten, um unvollkommene Stichproben in Schätzungen von Populationsdurchschnitten zu verwandeln. Unter idealen, sauberen Datenbedingungen sind sie etwa so genau wie klassische Methoden. Wenn die Daten jedoch Messfehler, falsch gemeldete Werte oder seltene Extremereignisse enthalten – wie es in nationalen Umfragen, der Umweltüberwachung und finanziellen Statistiken häufig vorkommt – liefern sie deutlich verlässlichere Antworten. Da sie rechnerisch praktikabel sind und in verschiedenen Designs und Einstellungen gut funktionieren, bieten diese Schätzer Praktikern in der Umfragepraxis ein nützliches Upgrade, das evidenzbasierte Entscheidungen widerstandsfähiger gegenüber der unvermeidlichen Unordnung realer Daten macht.
Zitation: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation.
Sci Rep16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5