Clear Sky Science · de
Blinde Erkennung von Kanalcodes basierend auf einem dual-Branch-Feature-Fusions-Convolutional-Neural-Network
Intelligentere Funkgeräte für überfüllte Frequenzbänder
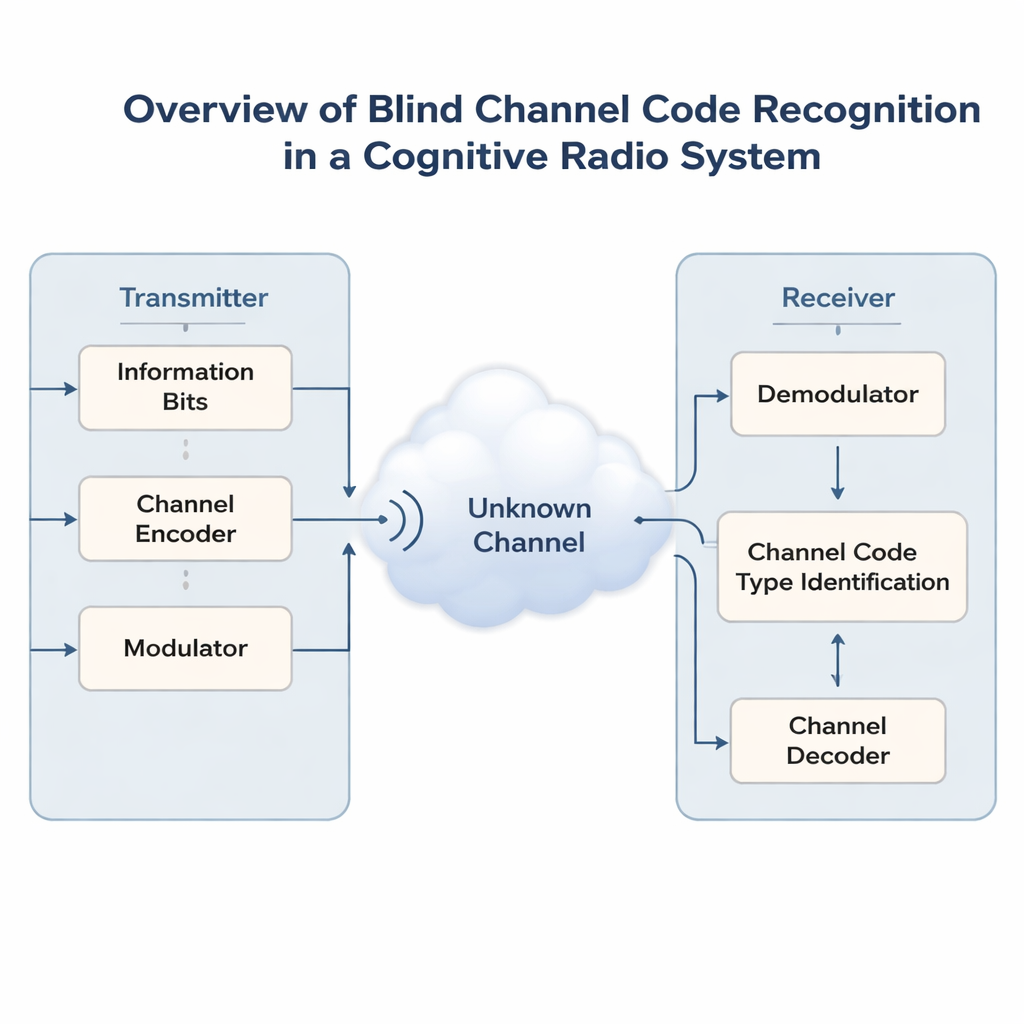
Drahtlose Netze werden immer dichter, da Telefone, Sensoren und Fahrzeuge um dieselben Frequenzbänder konkurrieren. Um Chaos zu vermeiden, müssen künftige „kognitive Funkgeräte“ zuerst zuhören und dann das bereits von anderen genutzte Spektrum intelligent teilen. Ein zentrales Problem ist, dass diese Empfänger oft nicht wissen, wie das ursprüngliche Signal vor dem Senden gegen Fehler geschützt wurde. Diese Arbeit stellt eine neue Methode der künstlichen Intelligenz vor, die den verborgenen fehlerkorrigierenden Code eines Signals erraten kann — ohne Vorinformationen — und so intelligenten Empfängern das zuverlässige Erfassen und Kommunizieren erleichtert.
Warum versteckte Fehlerkorrekturcodes wichtig sind
Moderne Funkverbindungen schützen Daten mit Fehlerkorrekturcodes, die sorgfältig strukturierte Redundanz hinzufügen, damit Empfänger Fehler durch Rauschen und Störungen beheben können. Unterschiedliche Situationen erfordern unterschiedliche Codes: einfache Hamming-Codes, leistungsfähigere BCH- und Reed–Solomon-Codes, flexible LDPC- und Polar-Codes oder stromorientierte Faltungs- und Turbo-Codes. In nicht-kooperativen Umgebungen — etwa militärische Kommunikation, Spektrumsüberwachung oder offene, geteilte Bänder — kann ein Empfänger den Sender nicht fragen, welchen Code er verwendet. Er sieht nur einen verrauschten Bitstrom. Das korrekte Erraten des Codierungsschemas, eine Aufgabe, die als blinde Codeerkennung bezeichnet wird, ist essenziell, bevor sinnvolles Dekodieren oder höherstufige Verarbeitung möglich ist.
Grenzen früherer Erkennungsverfahren
Frühere Forschungen konzentrierten sich entweder auf eine Codefamilie nach der anderen oder stützten sich auf handgefertigte Statistikmerkmale wie Häufigkeiten von Bitwiederholungen, wie zufällig eine Sequenz wirkt, oder algebraische Tricks, die auf einen bestimmten Code zugeschnitten sind. Diese Ansätze können allenfalls sagen: „das ist irgendeine Art von Blockcode“, tun sich jedoch schwer, mehrere verbreitete Formate gleichzeitig zu unterscheiden. Deep Learning hat die Lage kürzlich verbessert, indem Bitströme ein wenig wie Sätze in einem Sprachmodell behandelt werden. Allerdings betrachten die meisten neuronalen Netze entweder nur rohe Sequenzen oder nur manuell entworfene Merkmale und bewältigen typischerweise höchstens zwei oder drei Codetypen gleichzeitig. Ihre Genauigkeit fällt stark ab, wenn die Bitfehlerrate steigt — genau dann, wenn robuste Erkennung am dringendsten benötigt wird.
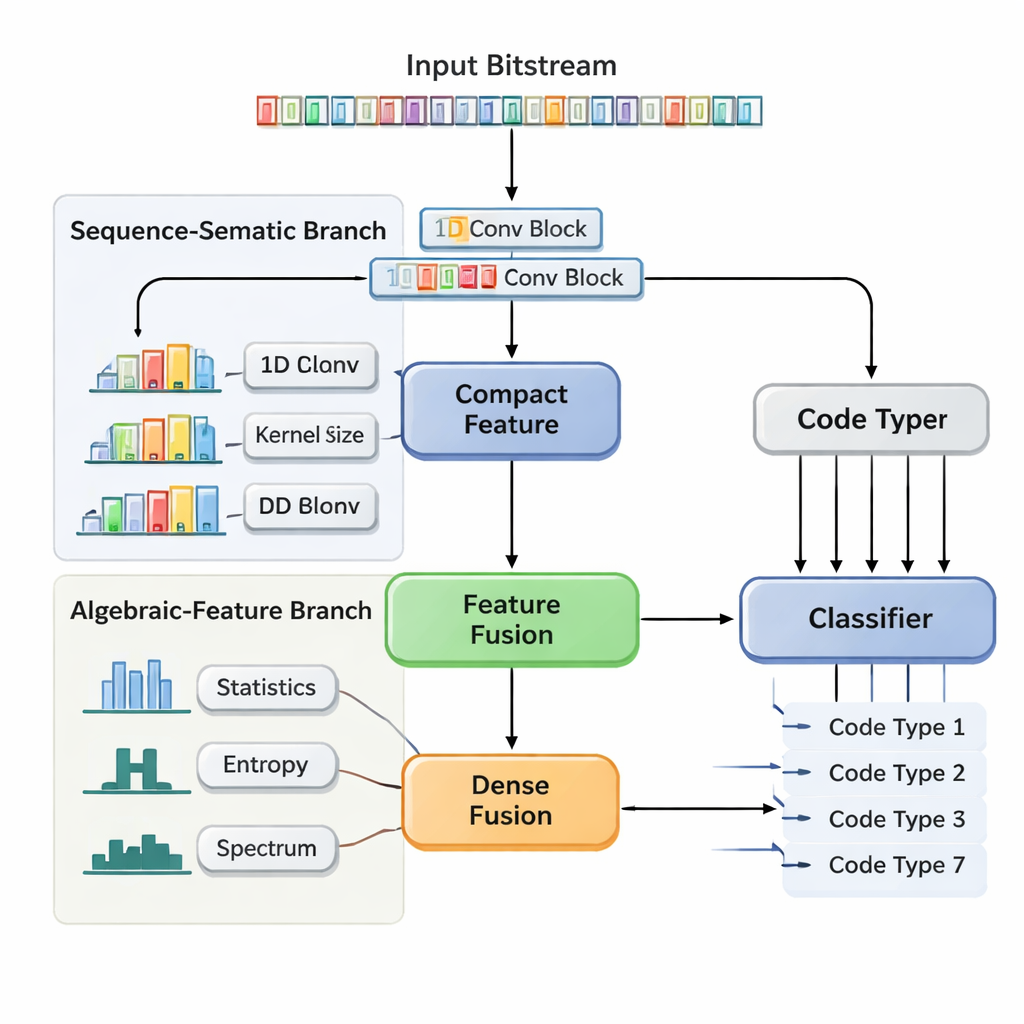
Ein zweigleisiges neuronales Netz, das Struktur und Statistik betrachtet
Die Autoren schlagen ein Dual-Branch Feature Fusion Convolutional Neural Network (DBFCNN) vor, das die blinde Erkennung von sieben weit verbreiteten Codes in einem Schritt bewältigt: Hamming, BCH, Reed–Solomon, LDPC, Polar, Faltungs- und Turbo-Codes. Der erste Zweig behandelt die eingehenden Bits als kurze „Wörter“, gruppiert sie in 8-Bit-Blöcke und bildet jeden Block auf einen dichten Vektor ab, ähnlich einem Wort-Embedding in der natürlichen Sprachverarbeitung. Anschließend werden eine Reihe eindimensionaler Faltungen mit unterschiedlichen Fenstergrößen und Dilatationsraten angewendet. Kleine Filter erfassen kurzreichweitige Muster, etwa die enge Struktur einfacher Blockcodes, während größere und dilatierte Filter längere Bereiche überspannen und Spuren von Interleavern und Paritätsmustern aufnehmen, wie sie typisch für Turbo- und LDPC-Codes sind. Ein globaler Pooling-Schritt verdichtet dies zu einer kompakten Zusammenfassung des strukturellen „Fingerabdrucks“ der Sequenz.
Handgefertigte Messgrößen, die das Modell stabilisieren
Der zweite Zweig nimmt eine ganz andere Perspektive ein. Statt roher Bits berechnet er sieben Gruppen beschreibender Statistikmerkmale, von denen Ingenieure wissen, dass sie sensitiv gegenüber Codierungsentscheidungen sind. Dazu gehören wie häufig Läufe identischer Bits auftreten, wie komplex die Sequenz ist, wie zufällig sie erscheint, wie stark sie mit verschobenen Kopien von sich selbst korreliert und wie ihre Energie über Frequenzen verteilt ist. Zusätzliche Messgrößen prüfen, wie „linear“ der Code wirkt und wie sich lokale Bitblöcke verhalten. Da sich diese Statistiken bei steigendem Rauschen nur langsam ändern, geben sie dem Netzwerk eine stabile, rauschtolerante Sichtweise. Ein kleines neuronales Subnetz wandelt diesen Merkmalsvektor in eine weitere kompakte Repräsentation um. Schließlich konkatenieren DBFCNN die beiden Zweige, normalisiert und regularisiert die kombinierten Merkmale und führt sie einem Klassifikator zu, der Wahrscheinlichkeiten für jeden der sieben Codetypen ausgibt.
Nachweis der Zuverlässigkeit unter verrauschten Bedingungen
Um DBFCNN rigoros zu testen, erzeugten die Autoren mehr als eine Million synthetischer Beispiele, die sieben Codefamilien, verschiedene Parametersettings und Bitfehlerraten von nahezu fehlerfrei bis zu extrem verrauschten Bedingungen abdecken. Sie trainierten und testeten das Modell mit sorgfältigen Monte-Carlo-Verfahren, um versteckte Überlappungen zwischen Trainings- und Testdaten zu vermeiden. Über diesen weiten Bereich hinweg übertraf DBFCNN konsequent drei starke Basismodelle, darunter ein früheres multiskaliges dilatiertes CNN, das speziell für diese Aufgabe entwickelt wurde. Bei moderaten und niedrigen Fehlerraten (Bitfehlerrate unter 10⁻³) identifizierte das neue Netzwerk den Codetyp in etwa 98 % der Fälle korrekt und verbesserte die absolute Genauigkeit um rund 5–11 Prozentpunkte gegenüber dem stärksten vorherigen Modell. Selbst bei sehr hohem Rauschpegel behielt DBFCNN einen klaren Vorteil und konnte mehrere komplexe Codes weiterhin mit hoher Zuversicht erkennen.
Was das für künftige intelligente Funkgeräte bedeutet
Für Nicht-Experten ist die Kernbotschaft, dass diese Arbeit zeigt, wie die Kombination von Fachwissen und Deep Learning Funkgeräte deutlich selbstständiger machen kann. DBFCNN lernt die subtilen „Akzente“ verschiedener Fehlerkorrekturcodes in verrauschten Bitströmen, indem es gleichzeitig auf zwei Arten „zuhört“: Ein Zweig erfasst detaillierte lokale Muster, der andere misst globale statistische Hinweise. Durch die Fusion dieser Sichtweisen kann das System meist genau feststellen, welches Codierungsschema genutzt wird, ohne Kooperation des Senders. Diese Fähigkeit ist ein Baustein für kognitive Funkgeräte, die sich in unbekannte Netze einbinden, sich an wechselnde Umgebungen anpassen und das knappe Spektrum besser nutzen können — und dabei die Kommunikation zuverlässig halten, selbst wenn die Luft stark frequentiert und verrauscht ist.
Zitation: Ma, Y., Lei, Y., Liu, C. et al. Blind recognition of channel codes based on dual-branch feature fusion convolutional neural networks. Sci Rep 16, 5159 (2026). https://doi.org/10.1038/s41598-026-35558-7
Schlüsselwörter: kognitives Funkgerät, Kanalcodierung, Deep Learning, Fehlerkorrektur, Signalklassifikation