Clear Sky Science · de
Genaues Erstellen von Entlassungsberichten mithilfe feinabgestimmter großer Sprachmodelle mit Selbstbewertung
Warum die Bürokratie im Krankenhaus wirklich wichtig ist
Wenn ein Patient das Krankenhaus verlässt, endet die Geschichte seiner Erkrankung nicht an der Ausgangstür. Ärzte in anderen Kliniken, Hausärzte und die Patienten selbst sind auf ein zentrales Dokument angewiesen – den Entlassungsbericht –, um zu verstehen, was im Krankenhaus geschehen ist und wie es weitergehen soll. Das Verfassen dieser Berichte ist jedoch langsame, repetitive Arbeit, die beschäftigte Kliniker pro Patient oft eine halbe Stunde oder mehr kostet. Diese Studie untersucht, wie moderne KI-Sprachwerkzeuge dabei helfen können, Entlassungsberichte schneller und genauer zu erstellen, während Patientendaten privat bleiben und unter der Kontrolle des Krankenhauses stehen.
Verstreute Aufzeichnungen in eine klare Erzählung verwandeln
Krankenhausinformationen sind über viele elektronische Systeme verteilt: Laborergebnisse in einer Tabelle, Operationsberichte in einer anderen, Pflegedokumentationen in einer dritten, und so weiter. Der Aufenthalt jedes Patienten erzeugt Tausende kleiner Textfragmente. Die Forschenden bauten zunächst eine Pipeline, die diese verstreuten, unordentlichen Informationen in saubere Eingaben umwandelt, die ein KI-Modell verstehen kann. Mit Methoden zum Zusammenführen und Entfernen von Duplikaten überlappender Einträge, zum Herausfiltern privater Angaben wie Namen und IDs, zur Rechtschreibkorrektur und zur Standardisierung medizinischer Begriffe erzeugten sie strukturierte Eingabedaten für jeden Krankenhausaufenthalt. Dieser Prozess wurde auf Daten von mehr als 6.000 Schilddrüsenoperationen an einem großen chinesischen Krankenhaus angewendet und lieferte gepaarte Beispiele echter Entlassungsberichte und der Rohdaten, aus denen sie erstellt wurden. 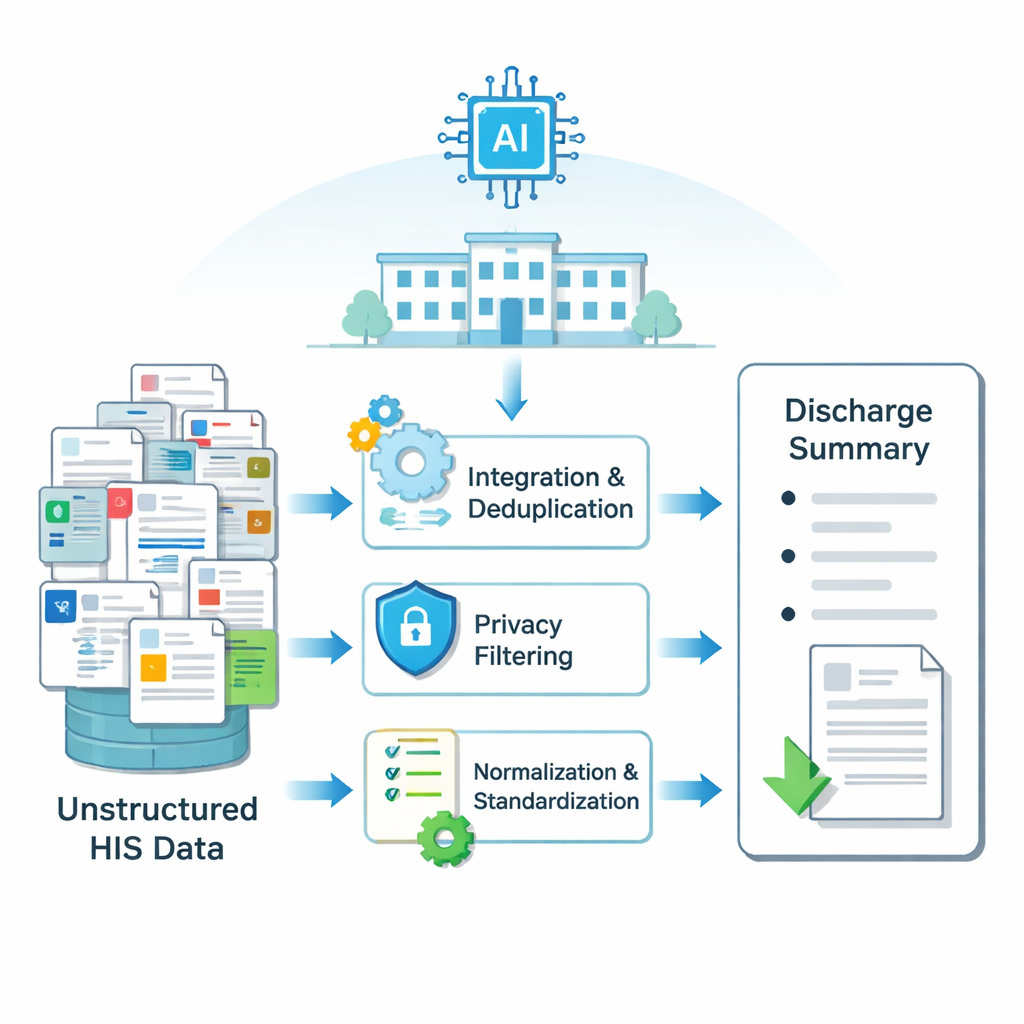
Die KI so abstimmen, dass sie die Sprache der Medizin spricht
Fertige große Sprachmodelle werden mit allgemeinem Text aus dem Internet und Büchern trainiert und haben daher oft Schwierigkeiten mit spezialisiertem medizinischem Vokabular und lokalen Dokumentationsstilen. Das Team verglich mehrere Wege, bestehende Modelle so "fein-abzustimmen", dass sie chinesische medizinische Aufzeichnungen besser verstehen. Eine neue Methode namens gewichtzerlegte nieder-rangige Anpassung, oder DoRA, justiert die internen Gewichte des Modells gezielter als ältere Techniken wie LoRA und QLoRA. Über verschiedene Modelle hinweg, darunter Qwen2, Mistral und Llama 3, erzeugte DoRA konsistent flüssigere Zusammenfassungen, die inhaltlich näher an menschlich verfassten Berichten waren und weniger Verwirrung zeigten (gemessen mit einer standardisierten Metrik namens Perplexity). Im Kern half DoRA der KI, medizinische Formulierungen und Terminologie zu lernen, ohne ein vollständiges Neutrainieren auf massiver Hardware zu erfordern.
Der KI beibringen, ihre eigene Arbeit zu überprüfen
Auch ein gut trainiertes Modell kann beim Verfassen eines langen Berichts wichtige Details vergessen oder kleine Fehler einbauen. Inspiriert von psychologischen Vorstellungen eines schnellen "System-1"-Denkens versus eines langsameren, sorgfältigeren "System-2"-Nachdenkens entwickelten die Autorinnen und Autoren eine Selbstbewertungsschleife. Zuerst schreibt das Modell aus den aufbereiteten Krankenhausdaten einen ersten Entlassungsbericht. Dann werden die Originaldaten in Segmente aufgeteilt – etwa Pathologiebefunde, ärztliche Anordnungen oder Laborbefunde – und jedes Segment wird erneut mit dem Entwurfspapier gepaart. Das Modell wird praktisch gefragt: „Spiegelt sich alles aus diesem Segment im Bericht wider?“ Falls nicht, überarbeitet es den Text, um fehlende oder inkonsistente Informationen hinzuzufügen. Dieser Zyklus wiederholt sich bis zu dreimal oder bis das Modell den Bericht als vollständig einstuft und so eine verfeinerte Version erzeugt, die die Patientenakte treuer wiedergibt. 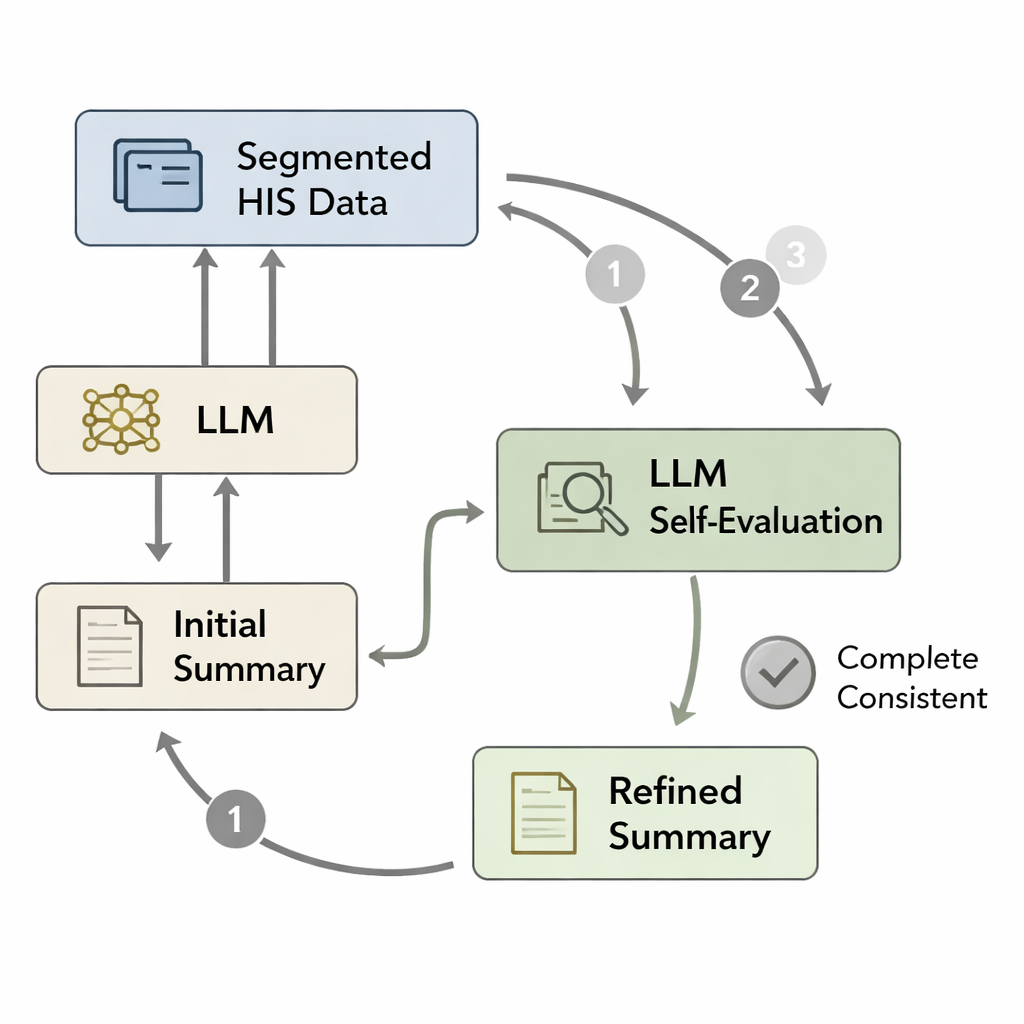
Wie gut schnitt die KI im Vergleich zu Menschen ab?
Zur Beurteilung der Qualität nutzte das Team automatische Metriken und menschliche Gutachter. Ärztinnen, Ärzte und medizinische Forschende bewerteten Berichte hinsichtlich Genauigkeit, Vollständigkeit, Klarheit, Konsistenz und Nützlichkeit für die weitere Versorgung. Das beste System – die Kombination aus DoRA-Feinabstimmung und der Selbstbewertungsschleife – kam in allen Kategorien den menschlich verfassten Berichten am nächsten. Besonders die Vollständigkeit verbesserte sich, was weniger übersehene Diagnosen, Behandlungen oder wichtige Laborwerte bedeutet. In einem detaillierten Beispiel hatte die KI zunächst versäumt, ein kleines Schilddrüsenkarzinom und ein bestimmtes Hormonpräparat zu erwähnen; nach zwei Selbstbewertungsdurchläufen wurden beide Details korrekt ergänzt. Im Durchschnitt generierte das System einen Entlassungsbericht in etwa 80 Sekunden auf einem Krankenhausserver, verglichen mit 30–50 Minuten, die ein Kliniker für die Neufassung von Grund auf benötigt, wobei eine menschliche Überprüfung weiterhin unerlässlich ist, bevor der Text in die amtliche Patientenakte gelangt.
Was das für Patienten und Klinikpersonal bedeuten könnte
Die Studie zeigt, dass KI-Systeme mit sorgfältigem Training und eingebauter Selbstprüfung Entlassungsberichte erstellen können, die nach einer kurzen menschlichen Prüfung klinisch akzeptabel sind. Das ersetzt nicht die Ärztinnen und Ärzte, kann ihre Zeit jedoch von routinemäßigem Tippen hin zu höherwertigen Prüf- und Entscheidungsaufgaben verlagern. Indem alle Berechnungen innerhalb des Krankenhausnetzwerks bleiben und identifizierende Details entfernt werden, respektiert der Ansatz zudem die Privatsphäre der Patientinnen und Patienten. Zwar stammen die bisherigen Ergebnisse aus einer einzigen Abteilung eines Krankenhauses, doch das Rahmenwerk weist in Richtung einer Zukunft, in der KI hilft, komplexe medizinische Daten in klare, verlässliche Berichte für viele Fachrichtungen zu verwandeln und so sicherere Übergaben in der Versorgung sowie ein besseres Verständnis für Patientinnen, Patienten und Angehörige zu unterstützen.
Zitation: Li, W., Feng, H., Hu, C. et al. Accurate discharge summary generation using fine tuned large language models with self evaluation. Sci Rep 16, 5607 (2026). https://doi.org/10.1038/s41598-026-35552-z
Schlüsselwörter: Entlassungsberichte, medizinische KI, große Sprachmodelle, klinische Dokumentation, Selbstbewertung