Clear Sky Science · de
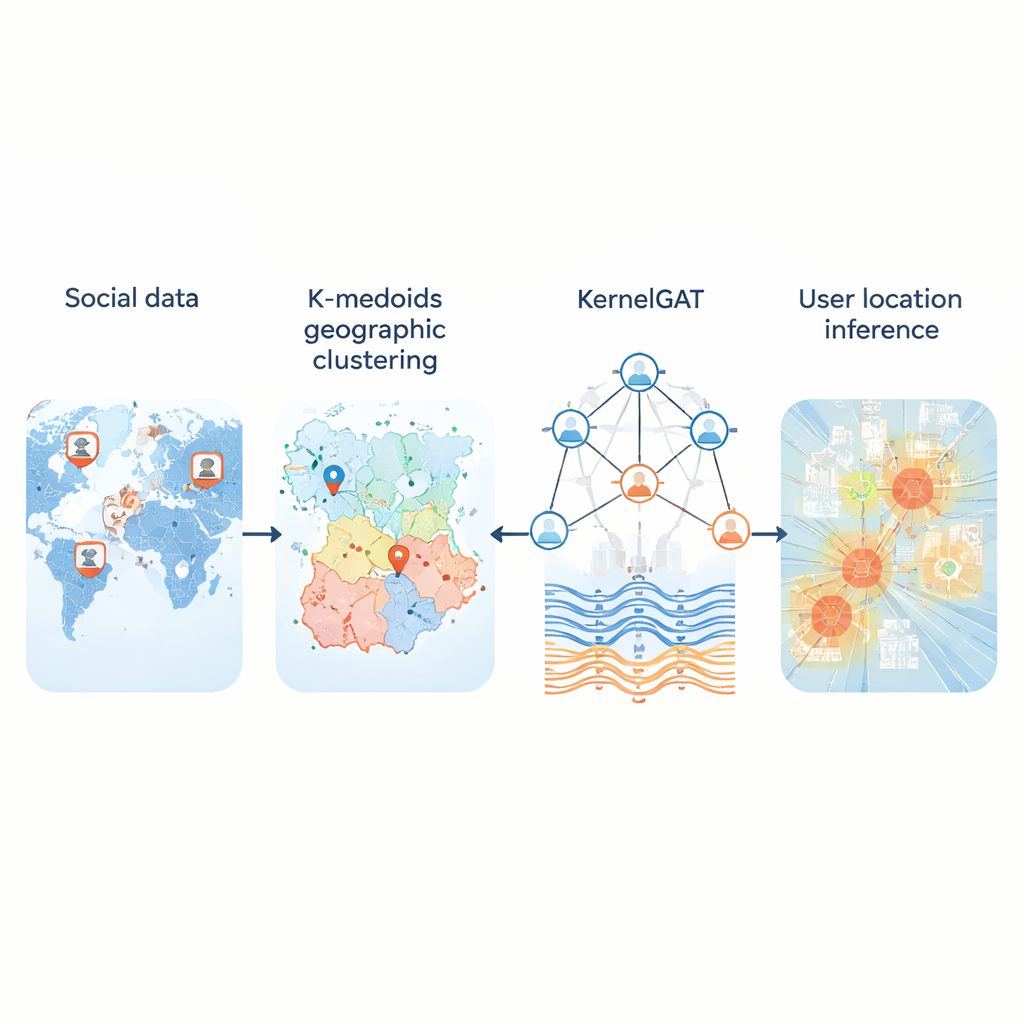
Geolokalisierung von Social-Media-Nutzern auf Basis von K-Medoids und einem Graph-Attention-Netzwerk mit Gaußschem Kernel
Warum Ihre Tweets verraten können, wo Sie leben
Jeden Tag posten Millionen Menschen in sozialen Medien, ohne ihre GPS-Koordinaten anzugeben. Dennoch hinterlassen diese Beiträge Hinweise darauf, wo Nutzer leben, arbeiten und unterwegs sind. Die Möglichkeit, aus dieser öffentlichen Spur den Standort abzuleiten, ist wichtig für alles von der Notfallhilfe und der Krankheitsüberwachung bis zu lokalen Empfehlungen und gezielten Diensten. Diese Arbeit stellt eine neue Methode vor, KMKGAT genannt, die sowohl das, was Menschen sagen, als auch ihre online-Verbindungen nutzt, um ihren Standort genauer zu schätzen als frühere Ansätze.
Von Online-Gespräch zu realen Orten
Wenn Nutzer Tweets oder Microblogs schreiben, nennen sie möglicherweise Ortsnamen, verwenden lokale Begriffe oder interagieren mit nahen Freunden. Firmen wie Twitter (jetzt X) kennen die Internetadresse eines Nutzers, doch externe Forschende und Dienstleister meist nicht. Stattdessen müssen sie mit öffentlichen Informationen arbeiten: dem Text selbst, Nutzerprofilen und wer mit wem spricht. Frühere Methoden fielen in drei Gruppen: Nur-Inhalts-Methoden durchsuchten Worte und Hashtags, um Standorte zu schätzen. Nur-Netzwerk-Methoden bauten auf der Tatsache auf, dass Menschen tendenziell mit geografisch nahen Nutzern interagieren. Eine dritte, leistungsfähigere Familie kombinierte beide Perspektiven, hatte aber weiterhin blinde Flecken — insbesondere für Menschen in dünn besiedelten Gebieten und für Nutzer, deren Online-Verbindungen große Entfernungen überspannen.
Intelligente geografische Gruppierung mit echten Nutzerzentren
Ein zentrales Problem ist, wie die stetige Erdoberfläche in Regionen unterteilt wird, die ein Computer vorhersagen kann. Viele Systeme zerschneiden die Karte in ein festes Gitter. Das funktioniert in Städten recht gut, versagt aber in ländlichen Regionen, wo riesige Zellen Hunderte von Kilometern abdecken. Die neue Methode ersetzt starre Gitter durch K-Medoids-Clustering, ein Verfahren zur Gruppierung von Nutzern, sodass jede Region auf einem tatsächlichen Nutzer statt einem künstlichen Punkt zentriert ist. Dadurch werden die Regionen kompakter und weniger anfällig für Ausreißer, besonders dort, wo Nutzer dünn verteilt sind. In Tests auf drei großen Twitter-Datensätzen, die die USA und die Welt abdecken, verringerte diese adaptive Partitionierung die typischen Fehler im Vergleich zu gitterbasierten Schemata und lieferte realistischere „Heimregionen“ für Nutzer.
Das Netzwerk auf nahe, ähnliche Nutzer fokussieren lassen
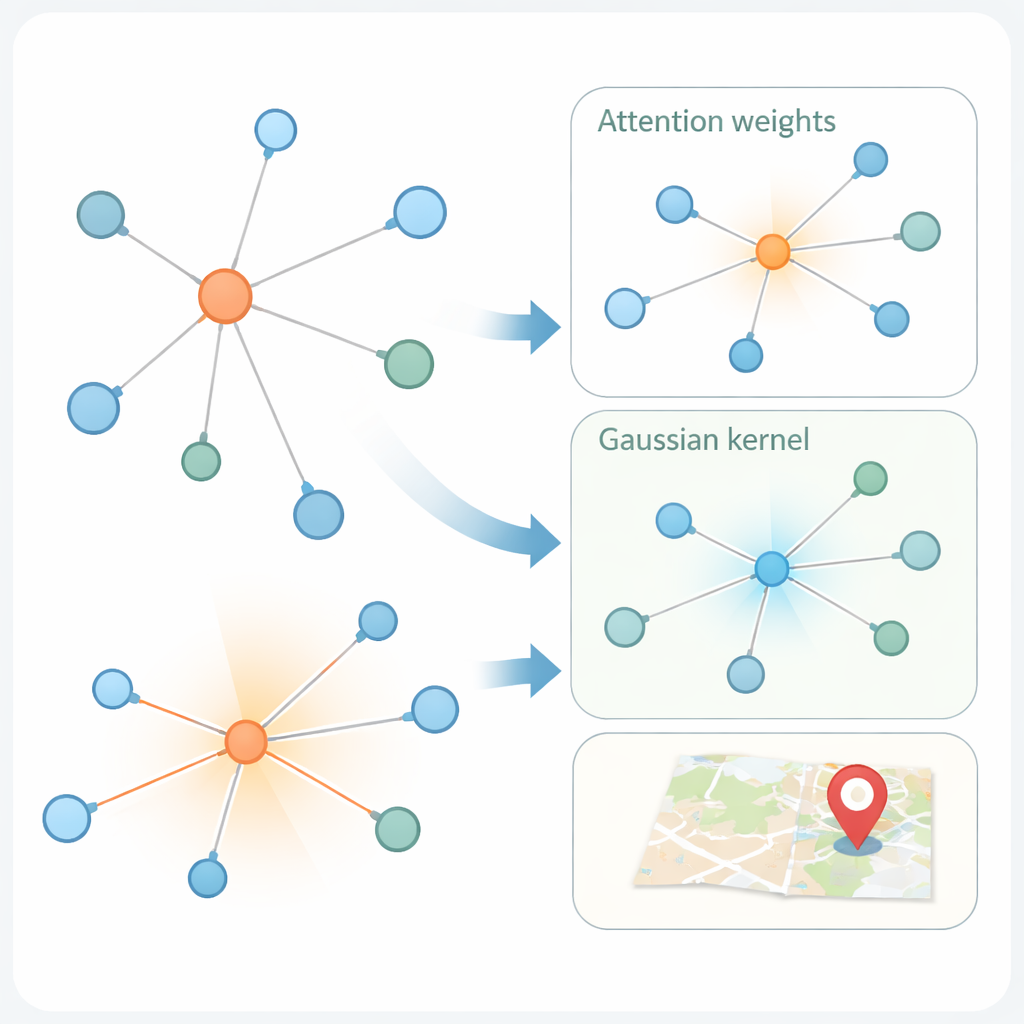
Die zweite Innovation betrifft, wie das Modell aus dem sozialen Graph lernt. Moderne „Graph-Attention-Netzwerke“ gewichten bereits die Nachbarn eines Nutzers unterschiedlich, je nachdem, wie ähnlich ihre Merkmalsdarstellungen sind. Doch Ähnlichkeit allein kann irreführend sein: Ein Konto in New York und ein anderes in London können ähnliche Sprache verwenden und geografisch weit auseinanderliegen. KMKGAT ergänzt die Attention um einen Gaußschen Kernel, einen mathematischen Filter, der Nachbarn bevorzugt, deren erlernte Merkmale dem Zielnutzer nahe sind, und die Einflüsse entfernterer Nachbarn dämpft. Mehrere solche Kernel, kombiniert wie ein Gemisch aus Linsen, erlauben es dem Modell, Lokalität in verschiedenen Skalen abzubilden. Das respektiert das einfache, aber mächtige Prinzip, dass Online-Interaktionen oft unter physisch näher stehenden Menschen am stärksten sind.
Leichte Textmerkmale, die dennoch Standorthinweise tragen
Statt auf schwere Deep-Language-Modelle zu setzen, die mit dem lauten, slangreichen Stil von Tweets Schwierigkeiten haben können, nutzen die Autoren eine klassische Technik namens TF–IDF, um die Sammlung von Beiträgen jedes Nutzers in eine Menge gewichteter Schlüsselwörter zu verwandeln. Häufige Wörter wie „the“ oder „lol“ erhalten dabei wenig Gewicht, während seltenere, regionsspezifische Begriffe nach oben steigen. Diese Textmerkmale werden dann jedem Nutzer im sozialen Graph zugeordnet und durch das erweiterte Attention-Netzwerk geleitet. Interessanterweise erzielten die besten Ergebnisse, wenn während des Trainings die meisten Textmerkmale zufällig weggelassen wurden, was darauf hindeutet, dass nur ein kleiner Bruchteil der Wörter tatsächlich bei der Standortbestimmung hilft und der Rest meist Störgeräusch ist.
Den Stand der Technik in großem Maßstab übertreffen
Zur Bewertung der Leistung fragten die Forschenden, wie weit in Kilometern das vorhergesagte Regionszentrum von den bekannten Koordinaten jedes Nutzers entfernt war und welcher Prozentsatz der Nutzer innerhalb von 161 km (100 Meilen) ihres tatsächlichen Standorts platziert wurde. Über drei Benchmark-Twitter-Datensätze hinweg übertraf oder erreichte KMKGAT konstant starke bestehende Systeme und verbesserte die Genauigkeit innerhalb von 161 Kilometern um bis zu einige Prozentpunkte — ein bedeutsamer Gewinn auf diesem Reifegrad. Die Vorteile zeigten sich am deutlichsten in kleinen und mittelgroßen Netzwerken; in einem sehr großen globalen Graph war die Methode durch die Notwendigkeit begrenzt, während des Trainings nur unmittelbare Nachbarn zu sampeln.
Was das im Alltag bedeutet
Für Nicht-Fachleute lautet die Schlussfolgerung, dass es zunehmend möglich ist, den Standort von Social-Media-Nutzern zu schätzen, selbst wenn sie nie ein Standort-Tag teilen. Indem Nutzer in realistische Regionen anhand tatsächlicher Konten gruppiert und das Modell darauf trainiert wird, vor allem nahe, ähnliche Nachbarn im sozialen Netzwerk zu vertrauen, verengt KMKGAT die Wahrscheinlichkeit, wo jemand wohnt oder postet. Das kann Einsatzkräften helfen, Menschen bei Katastrophen zu finden, die lokale Suche und Empfehlungen verbessern und Studien darüber unterstützen, wie sich Informationen über Orte hinweg verbreiten. Gleichzeitig macht es deutlich, wie viel unsere alltäglichen Online-Interaktionen über unser Offline-Leben verraten können, und unterstreicht die Bedeutung eines verantwortungsvollen Umgangs mit Daten und von Datenschutzmaßnahmen.
Zitation: Jiao, A., Qiao, Y., Li, P. et al. Social user geolocation based on K-medoids and Gaussian Kernel graph attention network. Sci Rep 16, 5115 (2026). https://doi.org/10.1038/s41598-026-35532-3
Schlüsselwörter: Geolokalisierung in sozialen Medien, Twitter-Nutzerstandort, Graph-Neuronale Netze, standortbezogene Dienste, Online-Datenschutz