Clear Sky Science · de
Intentklassifikation für universitäre Verwaltungsdienste mithilfe eines bidirektionalen rekurrenten neuronalen Netzes, modifiziert durch einen entwickelten Kepler-Optimierungsalgorithmus
Intelligentere digitale Hilfe für alltägliche Campusfragen
Studierende erwarten heute rund um die Uhr schnelle und präzise Antworten—sei es bei der Zulassung, der Kursanmeldung oder bei Fragen zur finanziellen Unterstützung. In diesem Beitrag wird eine neue Art von KI-gestütztem Chatbot untersucht, der speziell für universitäre Verwaltungsdienste entwickelt wurde, mit dem Schwerpunkt auf Englisch und Griechisch. Indem ein einziges System darin geschult wird, besser zu verstehen, was Studierende meinen und welche Details wichtig sind, wollen die Autorinnen und Autoren digitale Servicedesks schneller, zuverlässiger und einfacher betreibbar machen.
Warum heutige Chatbots noch verwirrt sind
Die meisten modernen Chatbots basieren auf dem Bereich des Natural Language Understanding, der eine Frage der Studierenden in zwei Hauptteile zerlegt. Ersteres ist die Intention: was die Person erreichen möchte, etwa „für einen Kurs anmelden“ oder „nach einer Frist fragen“. Zweitens sind da die Entitäten: konkrete Informationsstücke in der Frage, wie Kursnummer, Semester oder Studiengangsname. Traditionelle Systeme verwenden getrennte Modelle für diese beiden Aufgaben. Diese Trennung verschwendet Speicher und Rechenleistung und kann zu inkonsistenten Antworten führen—zum Beispiel wenn eine Kursnummer korrekt erkannt, aber nicht der richtigen Aktion zugeordnet wird. Diese Probleme verschärfen sich in mehrsprachigen Umgebungen, in denen dieselbe Idee in verschiedenen Sprachen auf vielerlei Weise ausgedrückt werden kann.
Ein gemeinsames Gehirn statt zwei
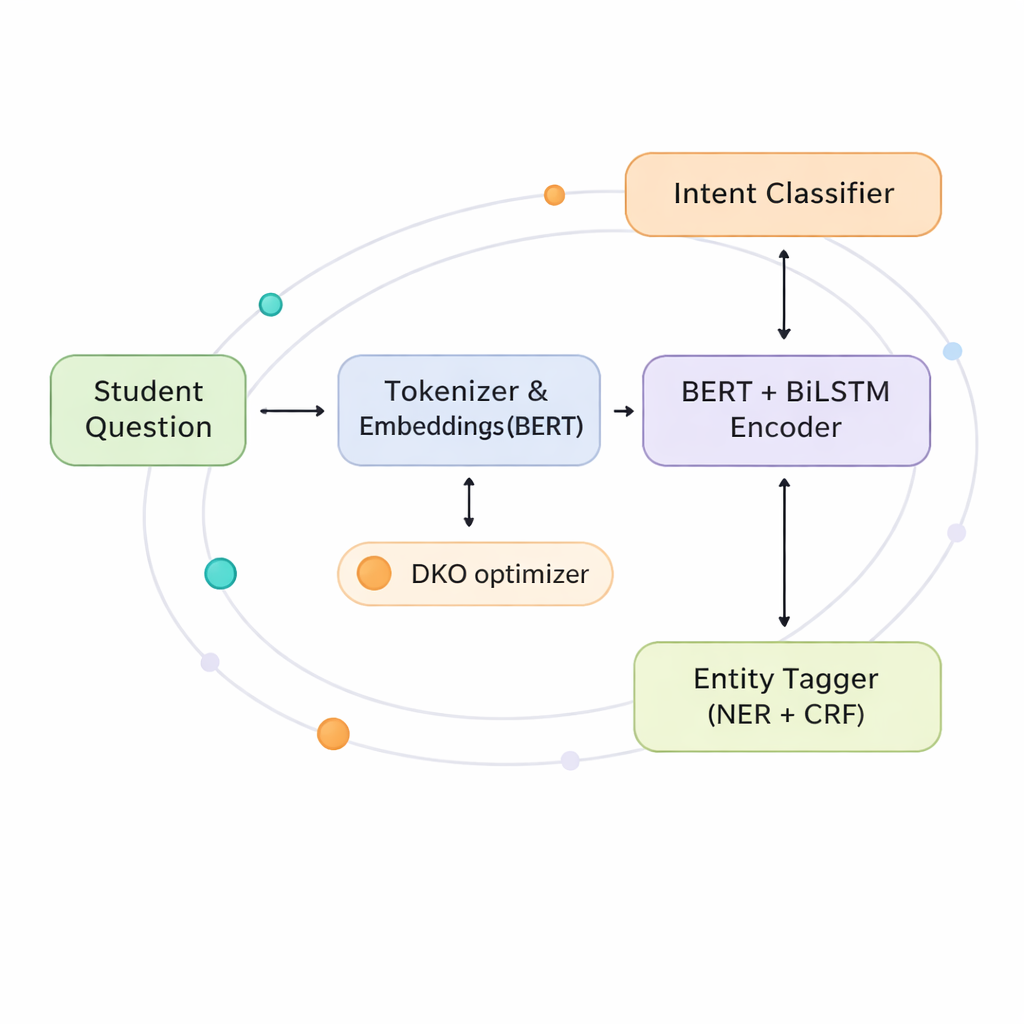
Die Autorinnen und Autoren schlagen ein gemeinsames Modell vor, das Intentionen und Entitäten gleichzeitig erkennt und dabei ein geteiltes „Gehirn“ statt zwei separater verwendet. Im Kern kombiniert es zwei leistungsfähige Techniken. Die erste, BERT, betrachtet einen gesamten Satz auf einmal, um seine übergeordnete Bedeutung zu erfassen. Die zweite, ein bidirektionales LSTM-Netzwerk, achtet besonders auf die Wortreihenfolge von links nach rechts und von rechts nach links, was hilft, lokale Zusammenhänge zu verfolgen—beispielsweise welcher Kurs zu welchem Semester gehört. Auf dieser gemeinsamen Repräsentation baut das System zwei Ausgänge auf: einer sagt die Intention der Studierenden vorher, der andere kennzeichnet jedes Wort danach, ob es eine Entität ist oder nicht.
Aufgaben gegenseitig miteinander sprechen lassen
Damit das gemeinsame „Gehirn“ optimal genutzt wird, enthält das Modell eine „co-interactive transformer“-Schicht, die es den beiden Aufgaben erlaubt, sich gegenseitig in Echtzeit zu informieren. Wenn das System eine Intention entscheidet, kann es auf die Entitäten schauen, die es vermutet; wenn es Entitäten labelt, kann es sich an der wahrscheinlichsten Intention orientieren. Dieser Austausch hilft, Mehrdeutigkeiten zu klären—etwa ob „drop“ bedeutet, einen Kurs zu verlassen oder eine Bewerbung zurückzuziehen—und ist besonders im Griechischen wertvoll, wo Wortformen und Wortstellung flexibler sind als im Englischen. Durch das Teilen von Repräsentationen und Aufmerksamkeit reduziert das Modell die Parameteranzahl im Vergleich zum Betrieb zweier großer Modelle fast um die Hälfte, was es für IT-Abteilungen an Universitäten praktischer macht.
Ein kosmosinspiriertes Trainingsverfahren
Das Training eines derart umfangreichen Modells ist anspruchsvoll: Standardoptimierer können langsam sein und empfindlich auf fein abgestimmte Einstellungen reagieren. Die Autorinnen und Autoren führen den Developed Kepler Optimization (DKO)-Algorithmus ein, inspiriert von der Art, wie Planeten die Sonne umkreisen. In dieser Analogie sind verschiedene Modellversionen wie Planeten, die den Raum möglicher Parameterkonfigurationen erkunden, während sie zur leistungsfähigsten „Sonne“ hingezogen werden. DKO startet diese Kandidaten in einer diverseren Verteilung als üblich und passt dann kontinuierlich ihre „Orbits“ an, je nachdem, wie gut sie abschneiden. Dieser Ansatz beschleunigt das Lernen um etwa 42 Prozent gegenüber einer populären Methode namens Adam und macht das Training gleichzeitig stabiler, insbesondere bei komplexen, mehrsprachigen Daten.
Tests in der Praxis mit Studierenden
Das Team evaluiert sein System an mehreren Datensätzen, darunter UniWay, einer Sammlung englischer und griechischer Fragen zu universitären Diensten, und xSID, einem bekannten Benchmark für das Verständnis kurzer Anweisungen. Über alle Datensätze hinweg übertraf das gemeinsame Modell konsequent regelbasierte Systeme, ältere neuronale Netze und sogar starke Transformer-Baselines. In Feldtests an zwei Universitäten—einer rein englischsprachigen und einer bilingualen—identifizierte der Chatbot Intentionen und Entitäten der Studierenden in etwa neun von zehn Fällen korrekt, und die Zufriedenheit lag bei etwa 4,5 von 5. Die Leistung blieb auch bei reduzierten Trainingsdaten stabil, was darauf hindeutet, dass die Methode robust in ressourcenärmeren Sprachen und Domänen ist.
Was das für Studierende und Universitäten bedeutet
Für Laien lautet die Kernbotschaft, dass die Autorinnen und Autoren eine effizientere und genauere „Zuhör-Engine“ für Universitäts-Chatbots entworfen haben. Durch die Vereinheitlichung von Intent-Erkennung und Detailextraktion sowie durch ein orbitinspirertes Trainingsverfahren kann ihr System besser erfassen, was Studierende fragen, und dabei weniger Speicher und Trainingszeit benötigen. Das könnte in schnellere Antworten, weniger Missverständnisse und mehrsprachige Unterstützung rund um die Uhr münden, ohne das Personal zu überlasten. Obwohl Herausforderungen bleiben—etwa die Anpassung an neue Richtlinien, weitere Sprachen und langfristige Nutzungsmuster—weist die Arbeit auf Campus-Hilfesysteme hin, die reaktionsschneller, fairer und skalierbarer erscheinen.
Zitation: Yang, Z., Lu, M. & Huang, S. Intent classification for university administrative services using a bidirectional recurrent neural network modified by a developed Kepler optimization algorithm. Sci Rep 16, 6263 (2026). https://doi.org/10.1038/s41598-026-35504-7
Schlüsselwörter: Universitäts-Chatbots, Intentklassifikation, Named-Entity-Recognition, mehrsprachige KI, Optimierungsalgorithmen