Clear Sky Science · de
Automatisierte Identifikation kontextuell relevanter biomedizinischer Entitäten mit geerdeten LLMs
Warum klügere Verschlagwortung medizinischer Artikel wichtig ist
Jedes Jahr erscheinen Tausende biomedizinischer Studien, jede voll mit Details zu Genen, Zelltypen, Krankheiten und Therapien. Doch die meisten dieser Informationen bleiben in langen PDFs verborgen, was es anderen Forschenden erschwert, genau die Daten zu finden, die sie benötigen. Dieser Artikel untersucht, wie moderne künstliche Intelligenz — große Sprachmodelle (LLMs) — automatisch diese wichtigen biomedizinischen Begriffe aus Forschungspublikationen extrahieren kann, um verstreute Artikel in gut organisierte, durchsuchbare Ressourcen zu verwandeln.
Von unübersichtlichen Artikeln zu durchsuchbaren Bausteinen
Biomedizinische Forschungszentren, etwa die deutschen Sonderforschungsbereiche, sind auf klare, strukturierte Daten angewiesen, damit Studien über Jahre wiederverwendbar bleiben. Klassisch mussten Forschende ihre Datensätze manuell mit wichtigen Entitäten wie Organismen, Zelllinien und Genen taggen — eine mühsame und zeitaufwändige Aufgabe. LLMs können ganze Artikel lesen und Kontext erfassen, was sie zu vielversprechenden Werkzeugen für die Automatisierung dieser Verschlagwortung macht. Es gibt jedoch einen Haken: Welche Begriffe tatsächlich relevant sind, hängt von der wissenschaftlichen Fragestellung und der geplanten Wiederverwendung der Daten ab. Die Autorinnen und Autoren arbeiten innerhalb eines sorgfältig entworfenen Metadatenschemas des nephrologisch ausgerichteten SFB „NephGen“, das der KI vorgibt, nach welchen Entitätstypen gesucht werden soll und wie diese zu organisieren sind.
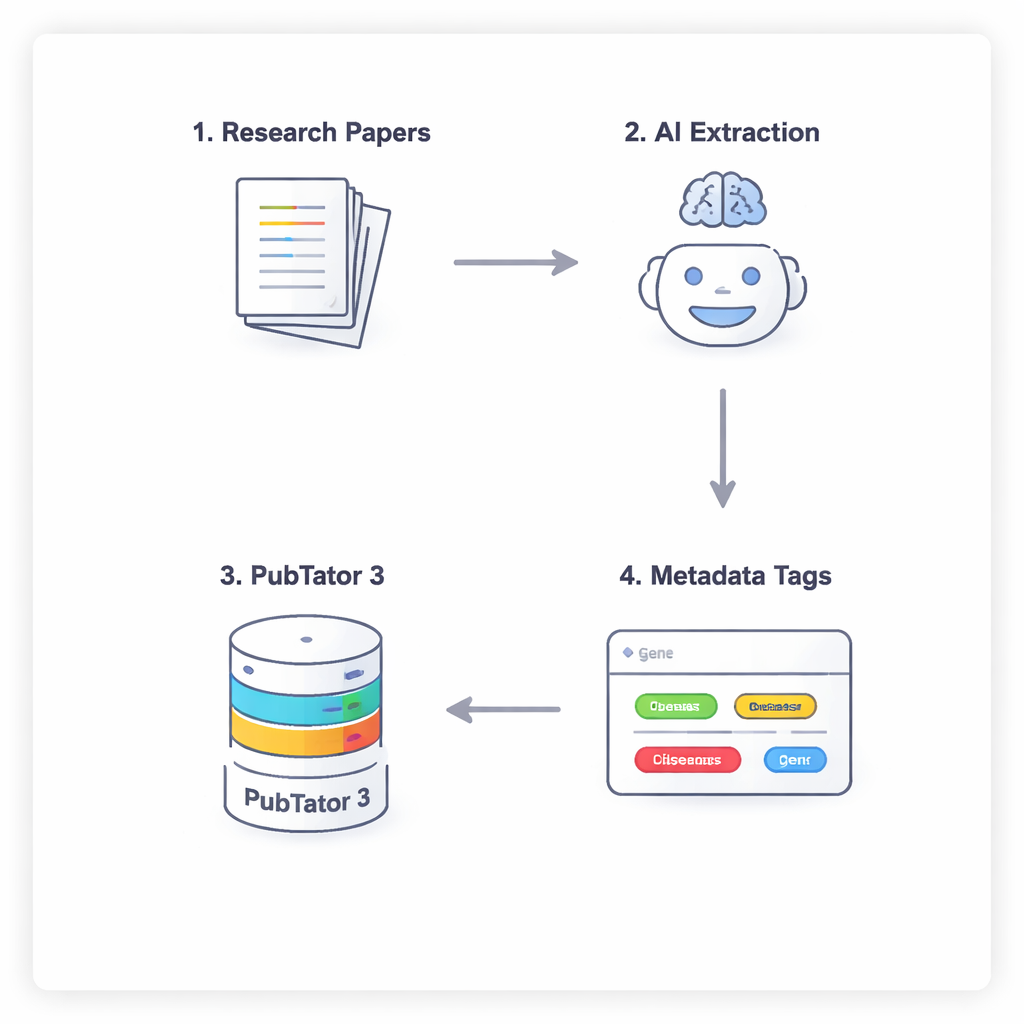
Ein vierstufiges Gespräch zwischen KI und einer Biologie-Datenbank
Um zu verhindern, dass die KI biomedizinische Fakten einfach errät oder „halluziniert“, nutzen die Forschenden einen vierstufigen Prozess, der die Modelle zum sorgfältigen Nachdenken und Überprüfen zwingt. Zuerst scannt das Modell den Volltext eines Artikels (ohne Diskussion und Literaturverzeichnis) und schlägt potenziell relevante Entitäten vor. Zweitens muss es ein externes Werkzeug, PubTator 3 — eine große biomedizinische Datenbank — konsultieren, um zu bestätigen, dass jeder vorgeschlagene Begriff tatsächlich existiert und eine anerkannte Kennung hat. Drittens ordnet die KI jede bestätigte Entität einem Feld im NephGen-Metadatenschema zu, das Entitäten in einer hierarchischen, menschengemachten Struktur zusammenfasst. Schließlich konsolidiert das Modell all dies zu einer strukturierten JSON-Ausgabe, also einer sauberen maschinenlesbaren Zusammenfassung der wichtigsten biomedizinischen Entitäten im Artikel.
Test von acht KI-Modellen mit realer Nierenforschung
Das Team implementierte diesen Workflow über APIs für 14 verschiedene LLMs und stellte fest, dass nur acht davon zuverlässig die strengen Anforderungen erfüllen konnten, etwa gültiges JSON zurückzugeben und Werkzeuge korrekt zu verwenden. Diese acht Modelle wurden dann auf sechs nephrologische Forschungsartikel angewendet, und die Autorinnen und Autoren jedes Artikels wurden in kurzen persönlichen Interviews gebeten, die finale Liste der KI vorgeschlagenen Entitäten zu prüfen. Da es keine feste „korrekte“ Anzahl zu extrahierender Entitäten gibt, konzentrierten sich die Forschenden auf Präzision: welchen Anteil der vorgeschlagenen Entitäten die Wissenschaftlerinnen und Wissenschaftler als korrekt bewerteten. Mithilfe statistischer Metaanalysen, angepasst für Anteile nahe 100 %, schätzten sie die Präzision für jedes Modell und berücksichtigten dabei Unterschiede zwischen den Artikeln.
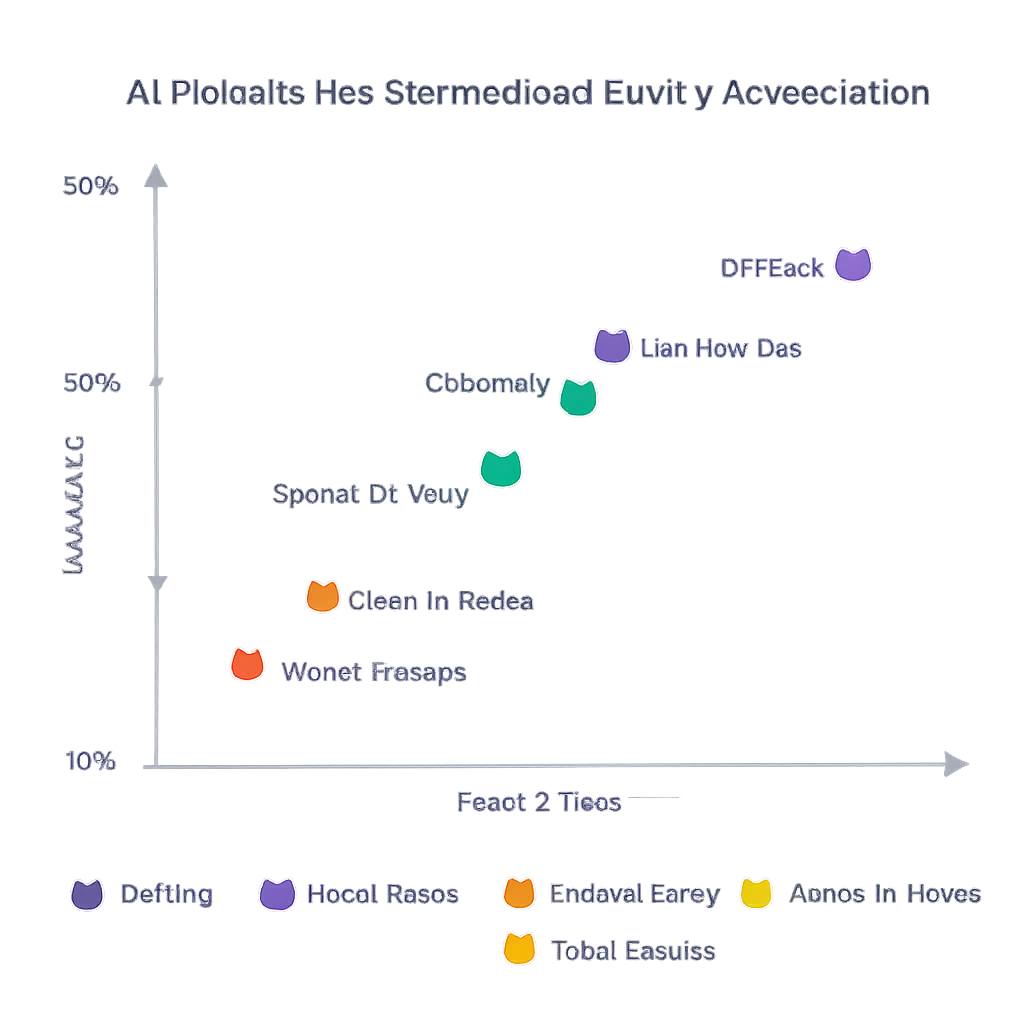
Hohe Genauigkeit, aber Kompromisse bei Aufwand, Kosten und Geschwindigkeit
Über alle Modelle hinweg erreichten die KI-Systeme eine Gesamtpräzision von etwa 91 %, das heißt die große Mehrheit der vorgeschlagenen Entitäten wurde als korrekt beurteilt. GPT-4.1, GPT-4o Mini und Gemini 2.0 Flash wiesen die höchste Präzision auf — ungefähr 94 % bis 98 % — wobei ihre Unterschiede statistisch nicht eindeutig waren. Gemini-Modelle neigten dazu, insgesamt mehr Entitäten vorzuschlagen, was zu mehr korrekten Tags, aber auch zu mehr Prüfarbeit für Menschen führte. Einige kleinere oder günstigere Modelle, etwa GPT-4.1 Nano, waren schneller und preiswerter, aber deutlich weniger genau. Die Autorinnen und Autoren visualisierten diese Spannungen mit Pareto-Fronten und identifizierten Modellkombinationen, die Präzision, Anzahl korrekter Entitäten, Kosten und Verarbeitungszeit ausbalancieren: Zum Beispiel erwies sich GPT-4o Mini als besonders attraktiv, wenn sowohl Genauigkeit als auch geringe Kosten Priorität haben.
Warum Menschen weiterhin in der Schleife bleiben sollten
Trotz guter Leistungen hebt die Studie wichtige Einschränkungen hervor. Die Modelle vermischten manchmal Informationen aus dem veröffentlichten Artikel mit Details, die für den zugrunde liegenden Datensatz, den künftige Nutzerinnen und Nutzer wiederverwenden könnten, nicht wirklich relevant waren. Diese Verwechslung spiegelt eine grundsätzliche Herausforderung beim automatisierten Textmining wider: Wissenschaftliche Artikel behandeln weit mehr Themen, als am Ende in einem gemeinsamen Datensatz landen. Die Autorinnen und Autoren empfehlen deshalb, dass menschliche Expertinnen und Experten KI-erzeugte Annotationen vor ihrer Veröffentlichung weiterhin prüfen. Sie vermerken außerdem, dass ihre Auswertung nur sechs nephrologische Artikel umfasst, sodass breitere Tests über Fachgebiete hinweg nötig sind. Mit der Zeit könnte ein routinierter „Human-in-the-loop“-Workflow ein Konsens-Referenzset aufbauen, das es ermöglicht, nicht nur die Präzision, sondern auch die Anzahl der von der KI verpassten Entitäten zu messen.
Was das für die künftige gemeinsame Nutzung biomedizinischer Daten bedeutet
Die Studie zeigt, dass moderne LLMs, wenn sie sorgfältig angeleitet und in vertrauenswürdige Datenbanken eingebunden werden, zuverlässig bei der Annotation biomedizinischer Artikel helfen können und damit die manuelle Arbeit von Forschenden erheblich reduzieren. Die besten Modelle erreichen eine annähernd expertennahe Präzision und bieten dabei verschiedene Kompromisse zwischen Gründlichkeit, Kosten und Geschwindigkeit. Vorläufig bleibt die menschliche Prüfung essenziell, um sicherzustellen, dass Annotationen wirklich zu den Datensätzen und dem Forschungskontext passen. Mit fortschreitender Entwicklung von Werkzeugen und Open-Source-Modellen könnten Workflows wie dieser jedoch zum Standardgerüst werden, um die heutige Flut medizinischer Artikel in gut organisierte, wiederverwendbare Datenbestände zu überführen.
Zitation: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
Schlüsselwörter: biomedizinisches Textmining, große Sprachmodelle, Metadatenannotation, geerdete KI, Forschung in der Nephrologie