Clear Sky Science · de
Automatische Diagnose der altersbedingten Makuladegeneration mittels maschinellem Lernen und Bildverarbeitungstechniken
Warum das für Ihr Sehvermögen wichtig ist
Da Menschen länger leben, sind immer mehr von uns von der altersbedingten Makuladegeneration (AMD) betroffen, einer Erkrankung, die das zentrale Sehen langsam zerstört und Lesen, Autofahren oder das Erkennen von Gesichtern erschweren oder unmöglich machen kann. Augenärzte können frühe Warnzeichen auf Fotos des Augenhintergrunds erkennen, aber das manuelle Auswerten von Tausenden Patientenaufnahmen ist zeitaufwendig und erfordert spezialisierte Fachkräfte. Diese Studie untersucht, wie ein transparentes, auf maschinellem Lernen basierendes Werkzeug helfen kann, AMD frühzeitig aus Routineaugenfotos zu erkennen, ohne auf fragile, kaum erklärbare Deep‑Learning‑„Blackboxen“ angewiesen zu sein.
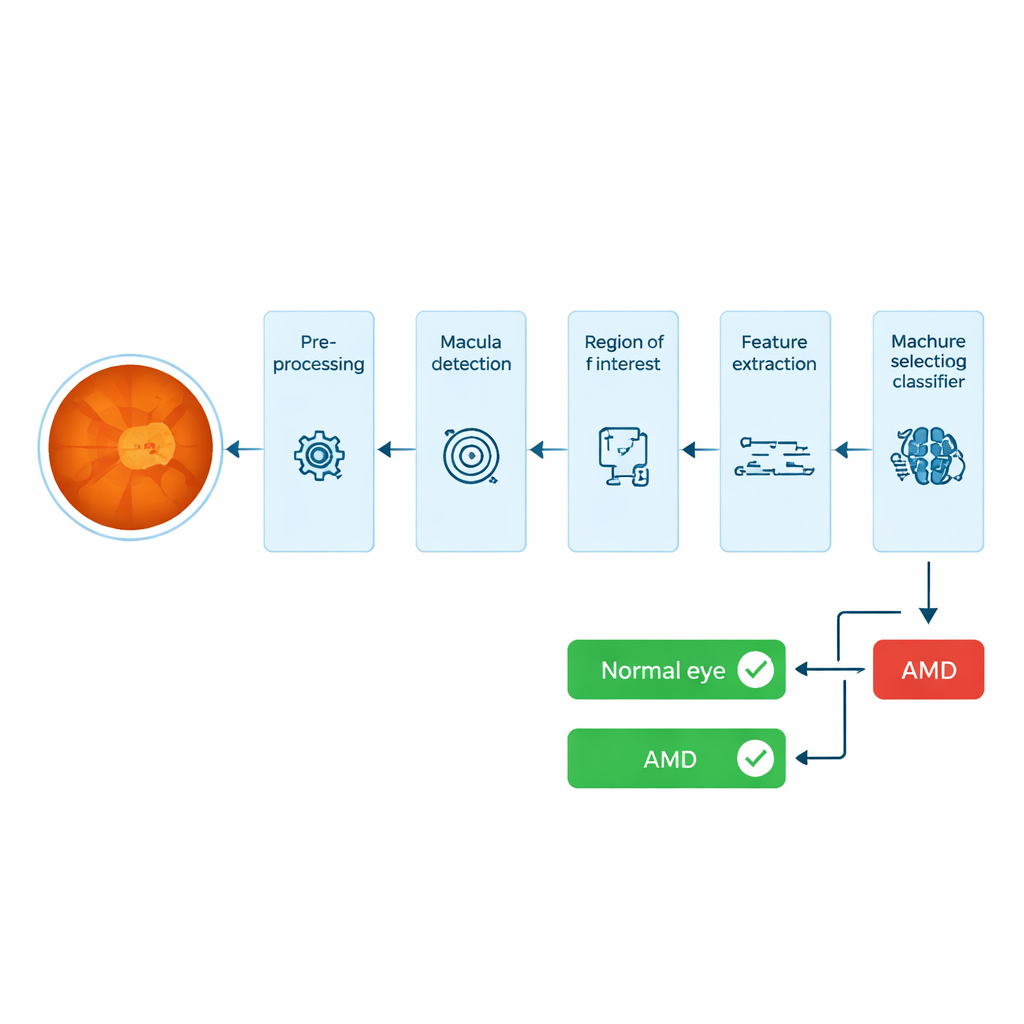
Auf der Suche nach Auffälligkeiten in der Zone für scharfes Sehen
AMD befällt die Makula, einen kleinen dunklen Fleck nahe der Mitte der Netzhaut, der scharfes, detailreiches Sehen ermöglicht. Viele automatisierte Systeme versuchen, winzige Fettablagerungen, sogenannte Drusen, in Ganzaugenbildern zu finden, doch Drusen lassen sich leicht mit anderen hellen Flecken wie kleinen Blutungen verwechseln und variieren stark in Form und Größe. Das macht ihre zuverlässige Erkennung für Computer schwierig, und selbst Experten müssen die Ergebnisse sorgfältig überprüfen. Die Autoren wählen einen anderen Weg: Statt im gesamten Netzhautbild direkt nach Drusen zu suchen, konzentrieren sie sich auf die Makularegion selbst und messen, wie sich deren Textur und Farbe bei AMD verändern.
Vom Rohfoto zum „Fingerabdruck" der Makula
Das System beginnt mit einem Farbfoto des Augenhintergrunds, einem sogenannten Fundusbild. Zunächst erhöht es den Kontrast mithilfe standardisierter Bildverarbeitungsschritte, sodass dunkle und helle Bereiche leichter zu unterscheiden sind. Anschließend lokalisieren die Algorithmen automatisch die Sehnervenscheibe — den hellen, kreisförmigen Bereich, an dem die Nerven das Auge verlassen — und nutzen deren bekannte geometrische Beziehung zur Makula, um entlang eines schmalen Streifens nach der dunkelsten Region zu suchen, die der erwarteten Größe und Position der Makula entspricht. Um diesen Punkt herum schneidet das System ein kleines Rechteck aus: dies ist die Region of Interest, die das Gewebe enthält, das am ehesten frühe AMD‑bedingte Veränderungen zeigt.
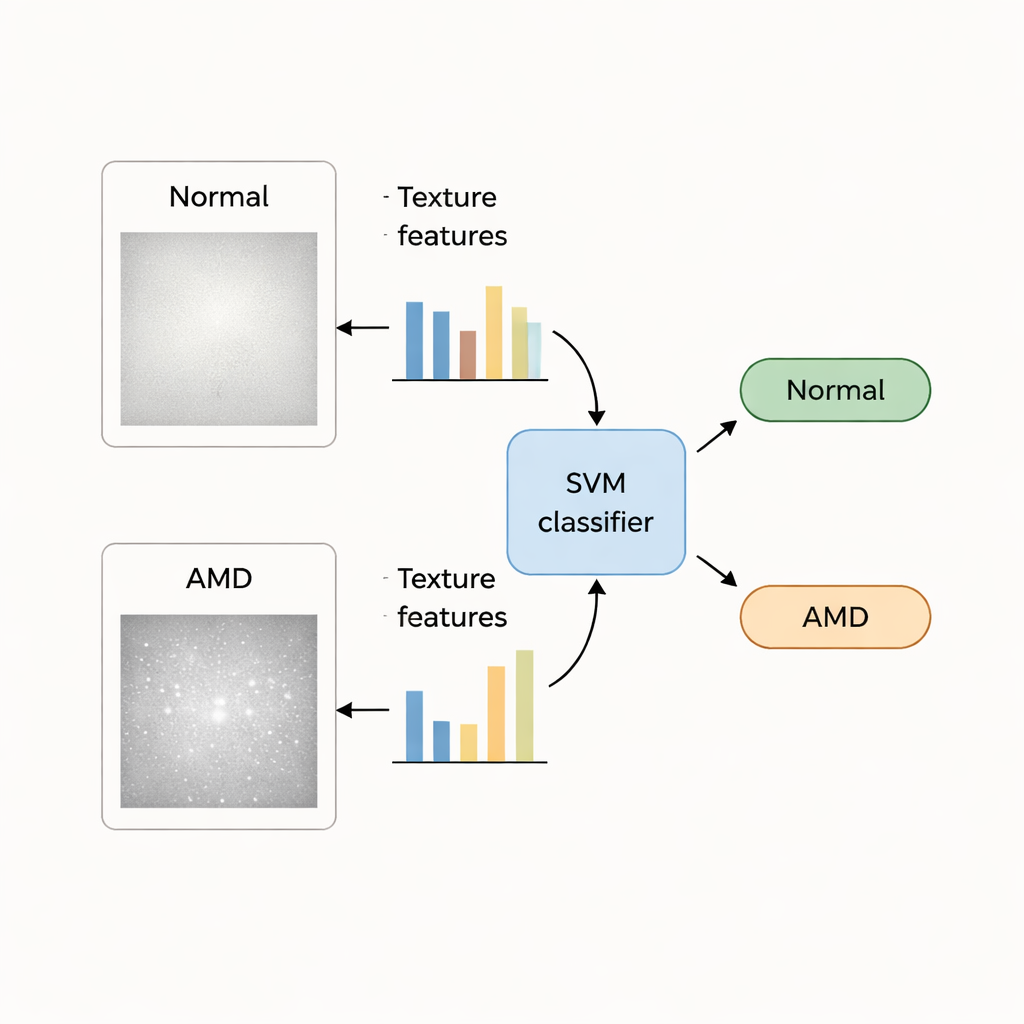
Aus Mustern und Farben werden Zahlen
Innerhalb dieses Makulafeldes berechnen die Forschenden eine große Menge numerischer Beschreibungen, sogenannter „handcrafted features“. Texturmerkmale erfassen, wie Pixelintensitäten angeordnet sind — ob die Oberfläche glatt, gesprenkelt oder unregelmäßig wirkt —, während Farbmerkmale Helligkeits‑ und Farbtonverschiebungen erfassen, die auf Veränderungen in Pigmenten und Gewebegesundheit hinweisen können. Insgesamt werden für jedes Augenbild 140 Textur‑ und 48 Farbwerte gemessen. Da nicht alle diese Zahlen gleichermaßen nützlich sind, wendet das Team statistische Tests und ein Merkmalsrankingverfahren an, um eine kleinere Teilmenge auszuwählen, die gesunde von AMD‑betroffenen Augen am besten trennt, und entfernt redundante oder rauscharme Messwerte.
Die Maschinen darauf trainieren, „AMD“ oder „normal“ zu sagen
Mit diesen ausgewählten Merkmalen trainieren die Autoren mehrere bekannte maschinelle Klassifikatoren — Support Vector Machine (SVM), k‑Nearest Neighbor, Naïve Bayes und ein einfaches neuronales Netz —, um den Unterschied zwischen normalen und von AMD betroffenen Augen zu lernen. Sie verwenden zwei öffentliche Sammlungen von Netzhautbildern: den STARE‑Datensatz, der 35 normale und 74 AMD‑Bilder enthält, und den größeren ODIR‑Datensatz mit Hunderten gelabelter Fälle. Zur Überprüfung der Zuverlässigkeit teilen sie jeden Datensatz wiederholt in Trainings‑ und Testanteile auf, rotieren die Bilder so, dass jedes Auge mindestens einmal als Test dient, und messen dann Genauigkeit, Fehlerrate und wie oft AMD korrekt erkannt wird.
Klare Ergebnisse und nachvollziehbare Begründung
Über alle Tests hinweg sticht der SVM‑Klassifikator hervor, der Texturmerkmale aus der Makularegion verwendet. Im STARE‑Datensatz unterscheidet er AMD fast 99 % der Zeit korrekt von normalen Augen; im ODIR‑Datensatz liegt die Genauigkeit bei etwa 95 %. Texturinformationen erweisen sich als aussagekräftiger als Farbe allein, und die Kombination beider Merkmalstypen übertrifft die Leistung der Textur allein nicht. Während einige Deep‑Learning‑Systeme in der Literatur vergleichbare oder geringfügig höhere Werte erreichen, benötigen sie große Mengen gelabelter Daten und liefern wenig Einblick, auf welche Bildhinweise sie sich stützen. Im Gegensatz dazu entsprechen die hier verwendeten handgefertigten Textur‑ und Farbmerkmale erkennbaren Strukturen in der Netzhaut, was das System für Kliniker besser interpretierbar macht.
Was das für Patienten bedeutet
Alltagsverständlich zeigt die Studie, dass ein relativ einfaches, transparentes Computerprogramm ein Standardaugenfoto betrachten, in die Makula zoomen und mit sehr hoher Zuverlässigkeit anzeigen kann, ob wahrscheinlich AMD vorliegt, ohne vorher zu versuchen, jede winzige Ablagerung nachzuzeichnen. Ein solches Werkzeug könnte Augenkliniken und Screening‑Programmen helfen, große Bildmengen schnell zu sortieren, sodass Patienten mit frühen Erkrankungen schneller von Spezialisten gesehen werden, und den Ärzten gleichzeitig klarer aufzeigen, welche visuellen Muster die Maschine für ihre Entscheidung nutzt.
Zitation: Agarwal, D., Bhargava, A., Alsharif, M.H. et al. Automatic diagnosis of age-related macular degeneration using machine learning and image processing techniques. Sci Rep 16, 5037 (2026). https://doi.org/10.1038/s41598-026-35428-2
Schlüsselwörter: altersbedingte Makuladegeneration, Retinalbildgebung, maschinelles Lernen, früherkennung von Erkrankungen, Analyse medizinischer Bilder