Clear Sky Science · de
Kombination von Parameterfragmentierung und Gruppenumverteilung zum Schutz vor einem unzuverlässigen Server im föderierten Lernen
Warum der Schutz gemeinsamer Modelle wichtig ist
Unsere Telefone, Krankenhäuser und Banken werden zunehmend von künstlicher Intelligenz angetrieben. Oft möchten mehrere Organisationen gemeinsam ein Modell trainieren, dürfen ihre Rohdaten aus gesetzlichen oder vernünftigen Gründen aber nicht an einem Ort zusammenführen. Das föderierte Lernen wurde entwickelt, um dieses Spannungsfeld zu lösen: Jede Teilnehmerin trainiert auf ihrem eigenen Gerät und teilt nur Modell‑Updates. Diese Arbeit zeigt jedoch, dass selbst diese Updates private Informationen preisgeben können, wenn der zentrale Server neugierig oder unehrlich ist — und stellt dann eine neue Methode vor, um sowohl unsere Daten als auch unsere Identitäten besser zu schützen.
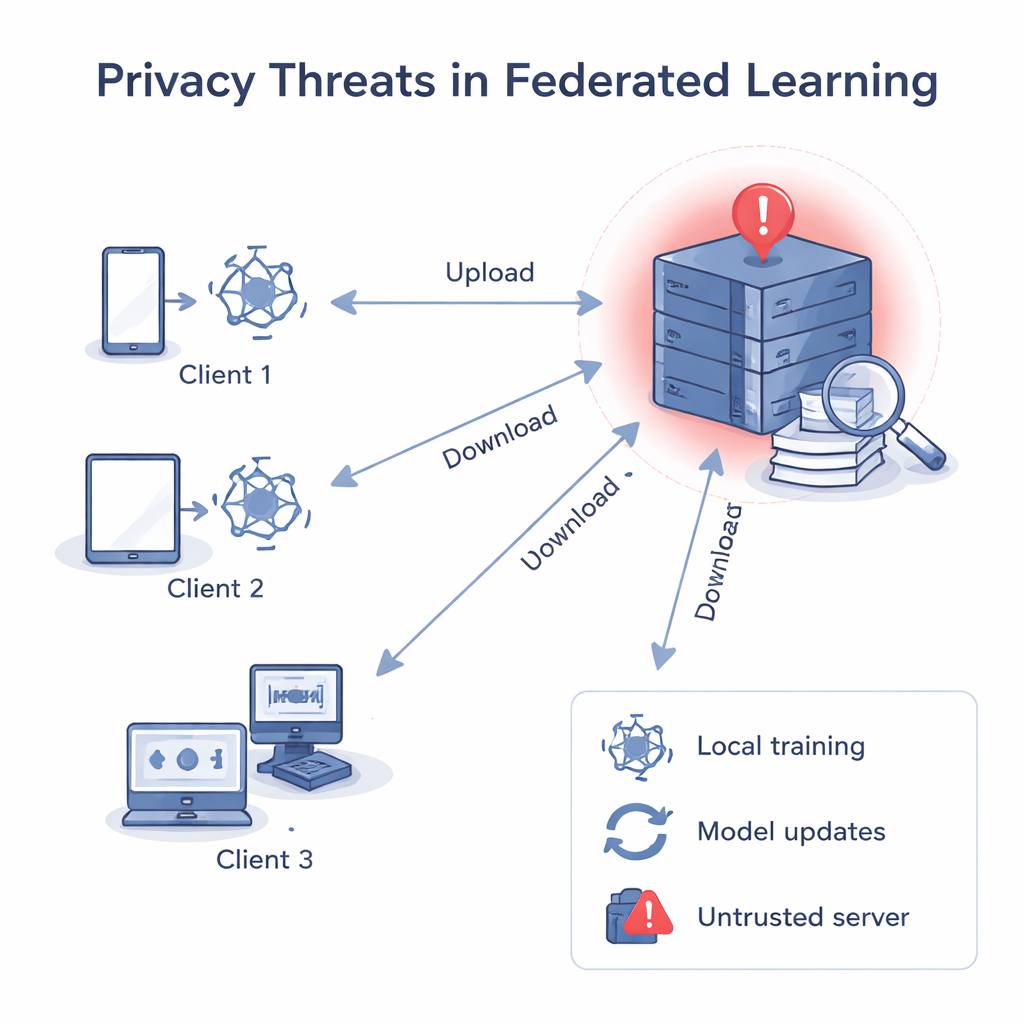
Wenn der Server nicht vertrauenswürdig sein sollte
Beim klassischen föderierten Lernen sendet ein zentraler Server ein gemeinsames Modell aus, jede Client‑Instanz verbessert es mit ihren eigenen Daten und schickt das aktualisierte Modell zurück. Der Server mittelt diese Updates zu einem besseren globalen Modell. Obwohl rohe Daten die Geräte nie verlassen, hat frühere Forschung gezeigt, dass Gradienten und Gewichte — die Zahlen im Modell — „rückwärts betrieben“ werden können, um private Daten wie Bilder oder Text zu rekonstruieren oder zu erraten, ob ein bestimmter Datensatz beim Training verwendet wurde. Ist der zentrale Server unzuverlässig, kann er jedes Client‑Update einzeln analysieren, etwas über die lokalen Daten dieses Clients lernen und sogar ein Update einer bestimmten Person oder Organisation zuordnen.
Updates in harmlose Stücke zerlegen
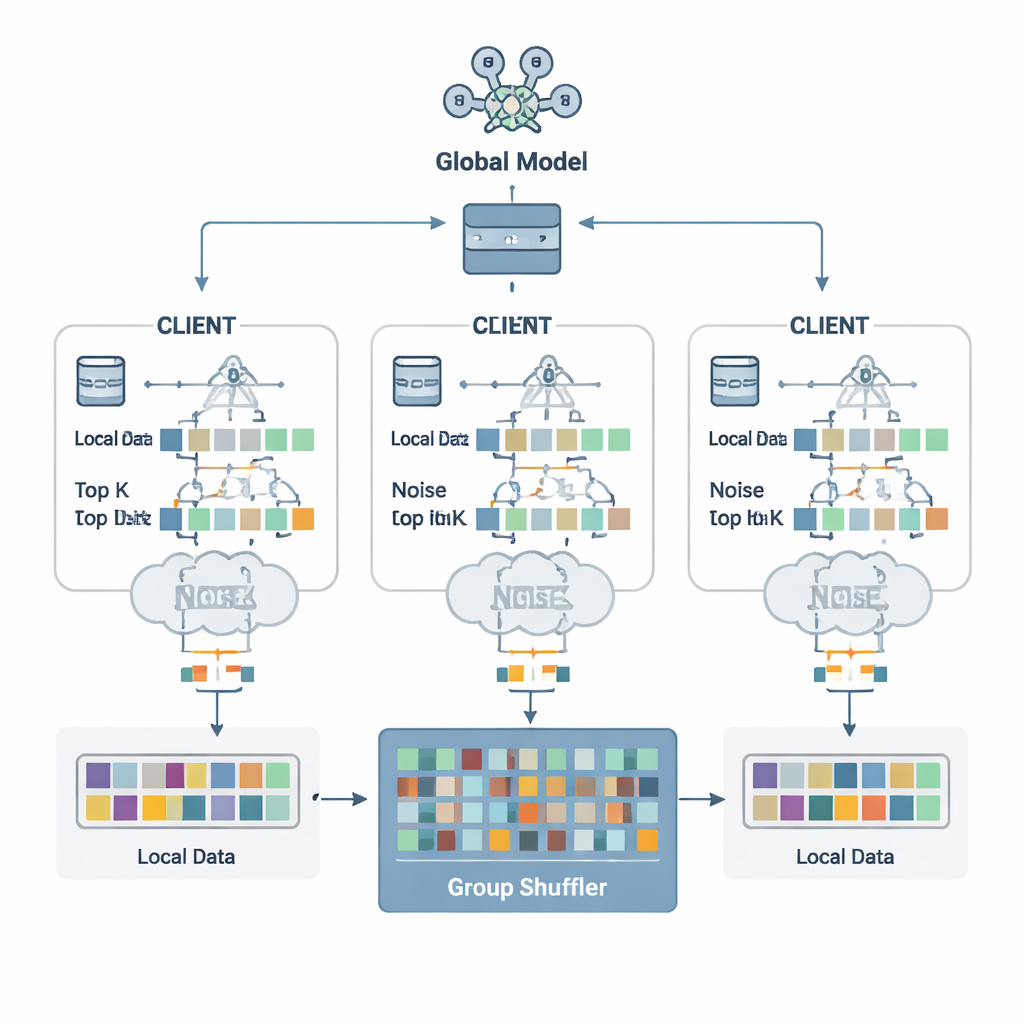
Die Autorinnen und Autoren schlagen ein Verteidigungsschema namens Security Defense based on Parameter Fragmentation Group Shuffling (SDPFGS) vor. Die erste Idee ist simpel, aber wirkungsvoll: Nie ein vollständiges Update senden. Stattdessen teilt jeder Client sein Modell‑Update in mehrere künstliche „Fragmente“. Die meisten dieser Fragmente werden mit Zufallswerten gefüllt, und nur das letzte wird so angepasst, dass alle Fragmente zusammen weiterhin das echte Update ergeben. Jedes einzelne Fragment — oder selbst mehrere davon — sieht wie Rauschen aus und verrät so gut wie nichts über die Originaldaten. Dieser mathematische Trick ähnelt dem Secret Sharing: Nur durch das Zusammenführen aller Teile lässt sich das Ganze wiederherstellen.
Rauschen hinzufügen und die Stücke mischen
Das Versenden vieler Fragmente könnte dennoch ineffizient sein und, wenn sie gemeinsam betrachtet werden, einem Angreifer mehr Informationen liefern. Um das zu vermeiden, wählt jeder Client nur die wichtigsten Fragmentwerte aus — die Top‑K Einträge, die für das Lernen am wichtigsten sind — und fügt ihnen sorgfältig kalibriertes Zufallsrauschen nach den Prinzipien der differenziellen Privatsphäre hinzu. Dieses Rauschen macht es statistisch schwer nachzuweisen, ob die Daten einer einzelnen Person einen bestimmten Wert beeinflusst haben. Dann kommt die zweite Schlüsselkomponente: Gruppenumverteilung (Group Shuffling). Anstatt Fragmente direkt an den Server zu senden, leiten Clients sie an einen vertrauenswürdigen „Shuffler“ weiter, der Fragmente vieler Clients in Gruppen mischt, bevor er sie weiterleitet. Nach dieser Durchmischung kann der Server nicht mehr feststellen, welches Fragment von welchem Client stammt, wodurch die Verbindung zwischen Updates und Identitäten gekappt wird.
Genauigkeit bewahren und Lecks reduzieren
Das Team testete SDPFGS an gängigen Bild‑ und Textbenchmarks, darunter handgeschriebene Ziffern (MNIST), Kleidungsfotos (Fashion‑MNIST) und Farbbilder (CIFAR‑10 und CIFAR‑100) sowie eine Nachrichtentextklassifikation. Sie verglichen ihre Methode mit mehreren modernen Datenschutztechniken, die nur Rauschen, nur Shuffling oder einfache Gradientenkodierung verwenden. In diesen Experimenten erreichte SDPFGS durchweg eine gleichwertige oder bessere Genauigkeit als konkurrierende Methoden und benötigte dabei weniger Kommunikation und Trainingszeit als viele davon. Besonders bemerkenswert war: Bei Modell‑Inversionsangriffen — bei denen ein Angreifer versucht, Trainingsbeispiele zu rekonstruieren — hatte SDPFGS die geringste Erfolgsrate der Angriffe, also die geringsten Lecks bezüglich der zugrundeliegenden Daten.
Was das für alltägliche Nutzerinnen und Nutzer bedeutet
Für Laien lautet die Kernaussage: „Die Daten zu verbergen“ allein reicht nicht; wir müssen auch verbergen, was unsere Geräte während des Trainings senden. SDPFGS erreicht das, indem es jedes Modell‑Update in verrauschte, gemischte Fragmente verwandelt, die einzeln nutzlos sind, sich aber dennoch zu einem hochwertigen globalen Modell kombinieren lassen. Das Ergebnis ist ein stärkerer Schutz gegen einen neugierigen oder kompromittierten Server, bei nur geringen Einbußen bei Genauigkeit und Effizienz. Wenn sich föderiertes Lernen in Gesundheitswesen, Finanzwesen und bei intelligenten Geräten weiter verbreitet, könnten Techniken wie SDPFGS dafür sorgen, dass Menschen von leistungsfähigen gemeinsamen Modellen profitieren, ohne die Schlüssel zu ihrem Privatleben preiszugeben.
Zitation: Guo, H., Chen, W., Li, J. et al. Combining parameter fragmentation and group shuffling to defend against the untrustworthy server in federated learning. Sci Rep 16, 5097 (2026). https://doi.org/10.1038/s41598-026-35420-w
Schlüsselwörter: föderiertes Lernen, Datenprivatsphäre, differenzielle Privatsphäre, Modell-Inversionsangriffe, sichere Aggregation