Clear Sky Science · de
Uneinigkeit zwischen menschlicher und KI-Bewertung von Behandlungsplänen
Warum das für die alltägliche medizinische Versorgung wichtig ist
Wenn KI-Werkzeuge Ärztinnen und Ärzten zunehmend bei der Auswahl von Behandlungen helfen, stellt sich eine zentrale Frage: Wem vertrauen wir mehr – Menschen oder Maschinen? Diese Studie untersucht eine einfache, aber beunruhigende Möglichkeit: Ärztinnen und Ärzte und KI-Systeme könnten nicht nur darin auseinandergehen, welche Behandlung die beste ist, sondern auch darin, was überhaupt als ein „guter“ Behandlungsplan gilt. Dieses Verständnis ist wesentlich, wenn KI die reale medizinische Entscheidungsfindung unterstützen statt unbemerkt verzerren soll.
Ein direkter Vergleich von Behandlungsratschlägen
Die Forschenden konzentrierten sich auf die Dermatologie, ein Fachgebiet, in dem Ärztinnen und Ärzte langfristige Hauterkrankungen behandeln, die selten eine einzige „richtige“ Lösung haben. Zehn erfahrene Dermatologinnen und Dermatologen und zwei große Sprachmodelle (LLMs) – ein allgemeines Modell und ein auf Schlussfolgern ausgerichtetes Modell – sollten jeweils Behandlungspläne für fünf herausfordernde, erfundene Fälle schreiben, etwa schweres Ekzem, Psoriasis mit Begleiterkrankungen und schwangerschaftsbedingte Akne. Um Fairness zu wahren, wurden alle 60 Pläne in ein gemeinsames Format gebracht: ähnliche Länge, Struktur und Tonalität. Offensichtliche Hinweise darauf, ob ein Mensch oder eine KI den Plan verfasst hatte, wurden entfernt, damit spätere Bewerter den Inhalt und nicht den Stil bewerten.
Wie Menschen und KI das Bewerteten
Die Pläne durchliefen dann zwei Runden blindbewerteter Scoring-Vorgänge mit demselben Bewertungsraster. Zuerst beurteilte dieselbe Gruppe von zehn Dermatologinnen und Dermatologen jeden Plan auf einer Skala von 0 bis 10 hinsichtlich Gesamtqualität unter Berücksichtigung von Wirksamkeit, Sicherheit, Praktikabilität und Patientenorientierung. Danach bewertete ein separates KI-Modell – nur als Gutachter, nicht als Autor – dieselben Pläne mit denselben Instruktionen. Entscheidend war, dass weder die menschlichen Bewerter noch das KI-Gutachtermodell wussten, wer einen bestimmten Plan geschrieben hatte. Dieses Vorgehen erlaubte den Autorinnen und Autoren, einen zentralen Faktor zu isolieren: ob der Bewertende ein Mensch oder eine KI war.
Menschen bevorzugen Menschen, KI bevorzugt KI
Die Ergebnisse zeigten einen klaren „Bewertereffekt“. Als Menschen die Pläne bewerteten, vergaben sie höhere Noten an die von ihren Kolleginnen und Kollegen verfassten Pläne als an jene der beiden KI-Systeme. Von Menschen erstellte Pläne erzielten im Durchschnitt geringfügig höhere Werte und belegten die fünf Spitzenplätze im Ranking. Eines der KI-Modelle, das fortschrittliche Schlussfolgerungsmodell, landete nahe dem unteren Ende. Als jedoch das KI-Gutachtermodell übernahm, kehrte sich das Bild um. Nun stiegen die beiden KI-verfassten Pläne an die Spitze des Rankings, und jeder menschliche Dermatologieplan rangierte darunter. Im Mittel bewertete die KI die von KI generierten Pläne höher als die von Menschen erstellten, obwohl sie exakt denselben, standardisierten Text las wie die Dermatologinnen und Dermatologen.
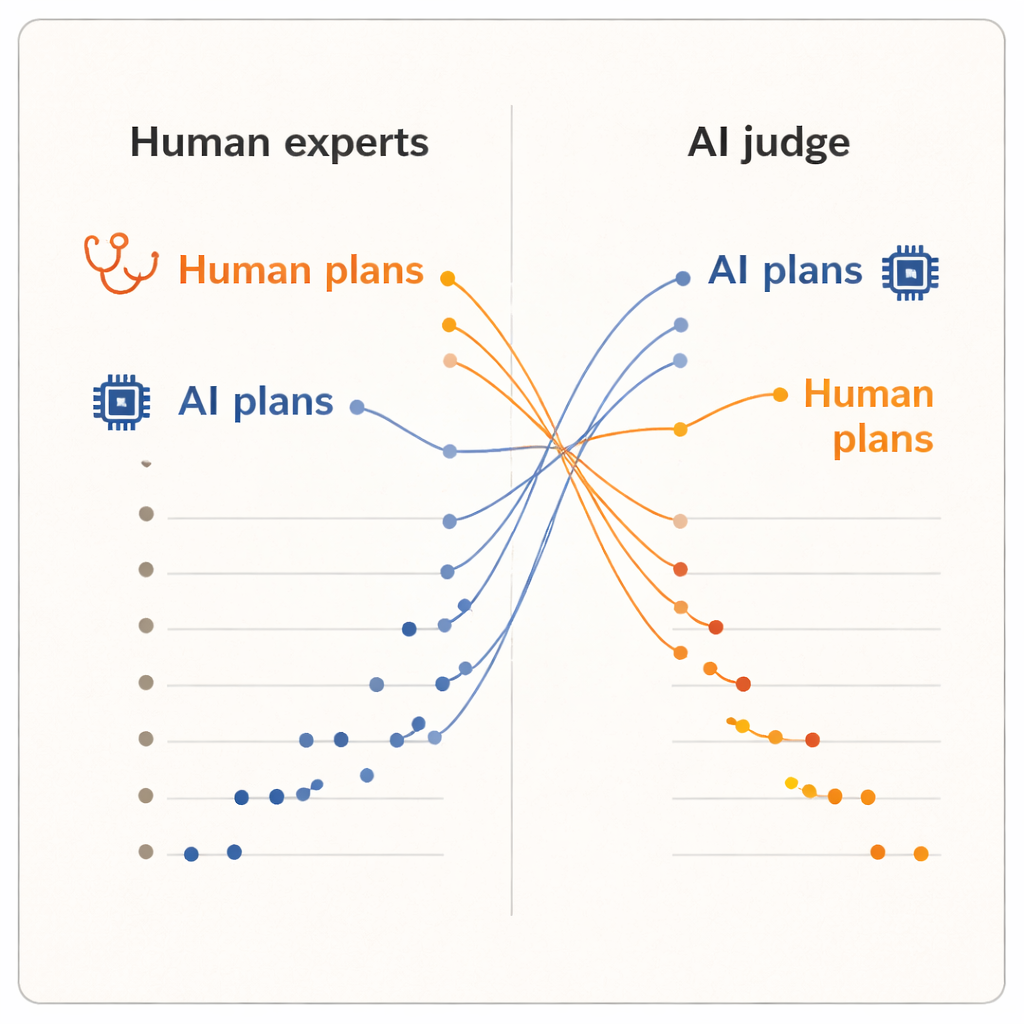
Unterschiedliche Vorstellungen davon, was einen „guten“ Plan ausmacht
Weil die Pläne hinsichtlich Formulierung vereinheitlicht wurden und die Bewerter die Herkunft nicht kannten, argumentieren die Autorinnen und Autoren, dass diese Spaltung nicht durch oberflächlichen Feinschliff erklärbar ist. Stattdessen legt sie nahe, dass Menschen und KI-Systeme unterschiedliche innere Maßstäbe anlegen. Klinikerinnen und Kliniker stützen sich wahrscheinlich stärker auf Praxiswissen: was in ihren Kliniken machbar ist, wie Patientinnen und Patienten reagieren und welche Kompromisse in der Praxis akzeptabel erscheinen. Dagegen könnte ein KI-Gutachter, der auf großen Textsammlungen trainiert wurde, Pläne bevorzugen, die Mustern in der medizinischen Literatur oder Leitlinien entsprechen, auch wenn diese Muster lokale Beschränkungen oder Patientenpräferenzen nicht vollständig abbilden. Die Studie ist klein – nur zehn Klinikerinnen und Kliniker, fünf Fälle und ein einzelnes KI-Gutachtermodell – und sie misst wahrgenommene Qualität, nicht tatsächliche Patientenergebnisse. Dennoch ist die Umkehrung auffällig genug, um tiefere Fragen darüber aufzuwerfen, wie wir klinische KI bewerten.
Neudenken von Testverfahren und Nutzung klinischer KI
Aus diesen Befunden ziehen die Autorinnen und Autoren zwei weitreichende Lehren. Erstens erfassen traditionelle „richtige-Antwort“-Tests für medizinische KI vieles von dem, was in der realen Versorgung zählt, nicht: Dort müssen Pläne Wirksamkeit, Sicherheit, Kosten, Logistik und Patientenwünsche gegeneinander abwägen. Sie plädieren für reichhaltigere, mehrdimensionale Bewertungsrahmen, die diese Dimensionen explizit punkten, mehrere menschliche und KI-Bewerter einbeziehen und analysieren, wo und warum Meinungsverschiedenheiten auftreten, statt alles in eine einzige Punktzahl zu pressen. Zweitens schlagen sie vor, dass Unterschiede zwischen menschlichen und KI-Urteilen eher eine Chance als nur ein Fehler sein können. Sorgfältig eingesetzt könnten KI-erstellte Pläne als durchdachte Zweitmeinung dienen, die Ärztinnen und Ärzte dazu anregt, ihre Annahmen zu überdenken, während die Klinikerinnen und Kliniker den realen Kontext und die ethische Urteilskraft beisteuern, die der KI fehlen. Vertrauenswürdige, transparente Schnittstellen zu entwickeln, die Annahmen offenlegen, Klinikern erlauben, Prioritäten anzupassen und kritische Überprüfung einladen, könnte helfen, diese Spannung zwischen menschlichen und KI-Perspektiven in sicherere, ausgewogenere Entscheidungen zu verwandeln.
Zitation: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
Schlüsselwörter: klinische Entscheidungshilfe, künstliche Intelligenz in der Medizin, mensch-KI-Zusammenarbeit, Behandlungsplanung, Bewertungsbias