Clear Sky Science · de
Ein hybrides Vorhersagemodell für PM2.5-Konzentration basierend auf hochfrequenten und niederfrequenten IMFs mit EMD-Zerlegung
Warum genauere Luftqualitätsvorhersagen den Alltag beeinflussen
Feinstaubpartikel in der Luft, bekannt als PM2.5, sind so klein, dass sie tief in unsere Lungen eindringen und sogar ins Blut gelangen können. In Nordchina, wo Schwerindustrie und Winterheizungen konzentriert sind, erreichen diese Partikel oft Werte, die Gesundheitswarnungen auslösen, den Verkehr stören und sogar Fabriken und Schulen schließen können. Diese Studie stellt eine sehr praktische Frage: Können wir die stündlichen PM2.5-Werte genauer vorhersagen, damit Städte und Bürger frühere und verlässlichere Warnungen erhalten, bevor die Luft gefährlich wird?
Ein genauerer Blick auf die verschmutzte Luft in Nordchina
Die Forschenden konzentrierten sich auf sechs Großstädte in Nordchina: Beijing, Tianjin, Shijiazhuang, Taiyuan, Jinan und Zhengzhou. Diese Städte stehen stellvertretend für dicht besiedelte, industrialisierte Regionen, in denen Verschmutzungsvorfälle besonders im Winter häufig sind. Mithilfe amtlicher Messdaten sammelte das Team stündliche PM2.5-Werte für das gesamte Jahr 2021, was für jede Stadt 8.760 Messpunkte ergibt. Sie fanden, dass die Belastung zwischen den Städten stark variierte; Taiyuan wies beispielsweise den höchsten mittleren PM2.5-Wert auf, während Beijing den niedrigsten hatte. Extreme Ereignisse waren auffällig: In Taiyuan stiegen die Konzentrationen während einer Staub- und Verschmutzungsperiode im März auf 652 Mikrogramm pro Kubikmeter an, wodurch der Luftqualitätsindex sein Maximum erreichte – ein deutliches Zeichen sehr schlechter Luft.
Warum die Vorhersage von PM2.5 so schwierig ist
PM2.5-Werte werden von vielen Faktoren gleichzeitig beeinflusst – lokale Emissionen aus Verkehr und Industrie, regionaler Transport von Staub und Rauch, Windgeschwindigkeit, Luftfeuchte und mehr. In der Folge verhält sich die Verschmutzungszeitreihe weniger wie eine glatte Kurve und mehr wie ein unruhiger, gezackter Herzschlag. Traditionelle statistische Werkzeuge oder selbst moderne neuronale Netze tun sich mit solchen Daten schwer: Sie erfassen vielleicht den allgemeinen Trend, verpassen aber plötzliche Spitzen, oder sie funktionieren in einer Stadt gut, versagen jedoch in einer anderen. Frühere Studien versuchten, Vorhersagen entweder durch mehr physikalische Details (zum Beispiel chemische Transportmodelle) zu verbessern oder allein auf ausgeklügelte maschinelle Lernverfahren zu setzen. Dieses Papier kombiniert stattdessen mehrere Methoden, von denen jede dafür gewählt wurde, einen anderen „Rhythmus“ in den Daten zu behandeln.
Das Signal in schnelle und langsame Rhythmen aufteilen
Der Schlüssel ist eine Technik namens Empirical Mode Decomposition (EMD), die die ursprüngliche PM2.5-Zeitreihe in mehrere einfachere Komponenten zerlegt. Einige dieser Komponenten schwanken schnell und erfassen kurzzeitige Spitzen und Rauschen; andere verändern sich langsam und spiegeln den zugrundeliegenden Trend wider. Die Autoren gruppieren die ersten fünf Komponenten als „hochfrequente“ Teile und die verbleibenden Komponenten plus einen Residualtrend als „niederfrequente“ Teile. Hochfrequente Anteile, die unregelmäßiger und stark nichtlinear sind, werden in ein Long Short-Term Memory (LSTM)-Netz eingespeist, eine Art Deep-Learning-Modell, das gut dazu geeignet ist, zeitliche Muster zu erlernen. Die ruhigeren, niederfrequenten Komponenten werden einem klassischen Zeitreihenverfahren namens ARIMA übergeben, das effektiv ist, wenn sich die Daten regelmäßiger und nahezu linear verhalten.
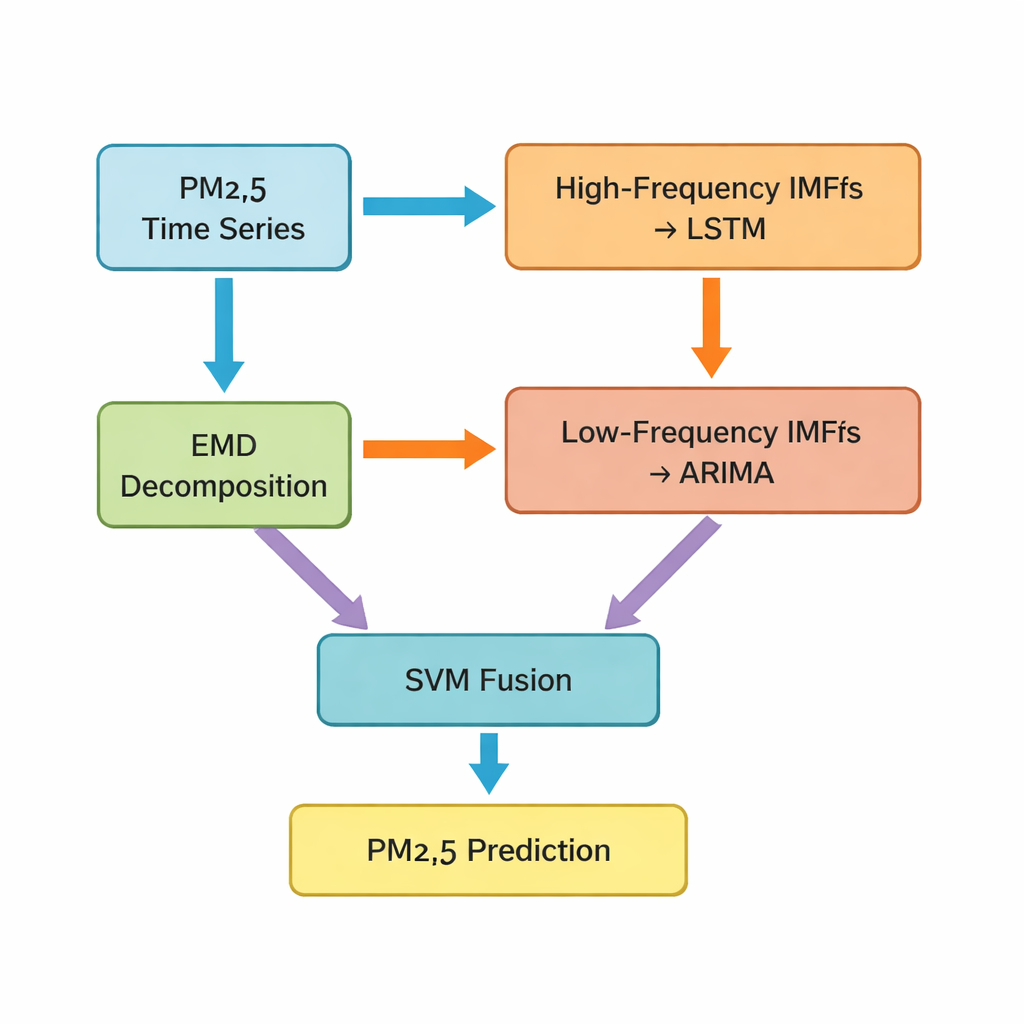
Verschiedene Modelle zu einer besseren Vorhersage verschmelzen
Nachdem LSTM- und ARIMA-Modelle jeweils eigene Teilvorhersagen erzeugt haben, steht die Studie vor einer weiteren Herausforderung: Wie verbindet man diese separaten Prognosen zu einem finalen, bestmöglichen PM2.5-Wert für die nächste Stunde? Dafür nutzen die Autoren eine Support Vector Machine (SVM), ein weiteres Verfahren des maschinellen Lernens, das lernt, wie die beiden Eingaben zu gewichten und zu kombinieren sind. Im Kern agiert die SVM wie ein Schiedsrichter, der entscheidet, wann die „schnelle“ Sicht (hochfrequente Muster) wichtiger ist und wann die „langsame“ Sicht (langfristige Trends) dominieren sollte. Das kombinierte System, das die Autoren Hybrid-EMDHL nennen, wird anschließend mit mehreren Leistungskennzahlen bewertet, darunter durchschnittlicher Fehler, Übereinstimmung von Vorhersagen und beobachteten Werten sowie die Fähigkeit des Modells, die Richtung der Änderung – ob die Werte steigen oder fallen – korrekt zu erfassen.
Klarere Warnungen und bessere Planung
Das hybride Modell übertrifft jede seiner Hauptkomponenten, wenn diese allein eingesetzt werden, in allen sechs Städten. Es reduziert nicht nur durchschnittliche und quadratische Fehler, sondern verbessert auch deutlich die Fähigkeit, korrekt vorherzusagen, ob PM2.5 in der nächsten Stunde steigen oder fallen wird – ein entscheidendes Merkmal für zeitnahe Gesundheitswarnungen. In vielen Fällen halbiert der hybride Ansatz die Fehlermetriken im Vergleich zu einem einzelnen neuronalen Netzwerk, und seine „Richtungsgenauigkeit‘‘ liegt über 0,69, was bedeutet, dass er in deutlich mehr als zwei Dritteln der Testfälle den Trend korrekt vorhersagt. Für Laien heißt das: luftqualitätsähnliche Vorhersagen, die schärfer und zuverlässiger sind. Für Stadtplaner und Gesundheitsbehörden bietet es ein praktisches Werkzeug, um gezielte, frühzeitige Maßnahmen zu unterstützen – etwa die Anpassung von Industrieaktivitäten oder Verkehrskontrollen – bevor ein Verschmutzungshoch erreicht wird, wodurch die Exposition verringert und das Alltagsleben in einigen von Chinas am stärksten verschmutzten städtischen Regionen geschützt werden kann.
Zitation: Wang, P., Wu, Q. & Zhang, G. A hybrid prediction model for PM2.5 concentration based on high-frequency and low-frequency IMFs with EMD decomposition. Sci Rep 16, 4969 (2026). https://doi.org/10.1038/s41598-026-35386-9
Schlüsselwörter: PM2.5-Vorhersage, Luftverschmutzung, Nordchina, maschinelles Lernen, Zeitreihenzerlegung