Clear Sky Science · de
QPSODRL: ein verbessertes, quanteninspiriertes Partikelschwarm-Optimierungs- und Deep‑Reinforcement‑Learning‑basiertes intelligentes Clustering‑ und Routing‑Protokoll für drahtlose Sensornetzwerke
Smarte Sensornetzwerke für eine vernetzte Welt
Von präziser Landwirtschaft bis hin zu Katastrophenwarnsystemen überwachen drahtlose Sensornetzwerke unsere Umwelt unauffällig und sammeln Daten von Hunderten oder Tausenden winziger Geräte, die über große Flächen verteilt sind. Ihre größte Schwäche ist zugleich ihr prägendes Merkmal: Jeder Sensor wird von einer kleinen Batterie mit Strom versorgt, die schwer oder gar nicht auszutauschen ist. Dieses Paper stellt eine neue Methode vor, um die Organisation und Steuerung des Datenflusses in solchen Netzwerken zu verbessern, sodass Batterien länger halten, Informationen zuverlässiger übertragen werden und sich das Netzwerk an veränderte Bedingungen anpasst.
Warum winzige Geräte große Intelligenz brauchen
In einem drahtlosen Sensornetz kann jeder Knoten messen, rechnen und kommunizieren, aber Energie ist kostbar. Wenn einige Knoten zu viel Arbeit leisten, sterben sie früh und erzeugen „tote Zonen“, in denen keine Daten mehr gesammelt werden können. Um dies zu vermeiden, gruppieren Designer Knoten typischerweise in Cluster. Innerhalb jedes Clusters wird ein Knoten zum Cluster‑Head: Er sammelt Messwerte von seinen Nachbarn und leitet sie zur zentralen Basisstation weiter. Die Auswahl, welche Knoten Cluster‑Heads sein sollten und wie Daten durch das Netzwerk weitergereicht werden, ist ein komplexes Puzzle, das sich mit dem Entladen der Batterien ändert. Traditionelle regelbasierte oder einzelne Algorithmus‑Lösungen neigen dazu, zu schnell auf suboptimale Muster festzulegen oder versagen, wenn sich die Form und die Energieniveaus des Netzwerks im Laufe der Zeit verändern.
Verschmelzung quanteninspirierter Schwärme mit lernenden Systemen
Diese Studie stellt QPSODRL vor, ein Protokoll, das zwei starke Ideen verbindet: eine quanteninspirierte Schwarmmethode zur Clusterbildung und eine Deep‑Reinforcement‑Learning‑Engine für das Routing. In der ersten Phase erkunden virtuelle „Partikel“ verschiedene Möglichkeiten, Cluster‑Heads und Mitglieder zuzuweisen. Ihr Verhalten wird durch ein Maß dafür geleitet, wie gleichmäßig die Energie im Netzwerk verteilt ist, bekannt als Entropie. Bei unausgewogener Energienutzung fördert der Algorithmus eine breite Exploration neuer Cluster‑Layouts; bei stabileren Zuständen verfeinert er vielversprechende Konfigurationen. Ein spezieller „Elite‑Perturbations“-Schritt stößt gelegentlich die besten Kandidaten in neue Richtungen, was der Suche hilft, lokalen Sackgassen zu entkommen und die wiederholte Nutzung derselben energieintensiven Knoten zu vermeiden. 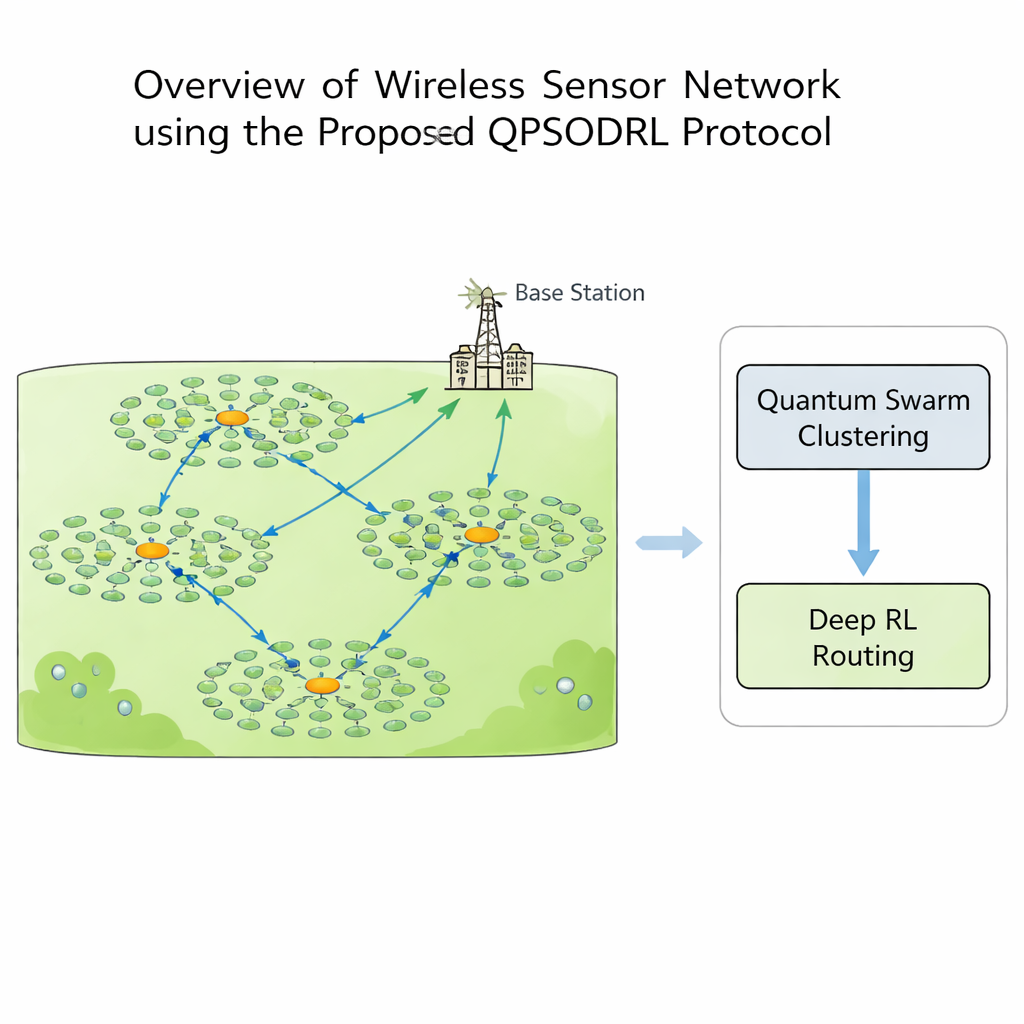
Dem Netzwerk beibringen, bessere Pfade zu finden
Sobald Cluster gebildet sind, entscheidet die zweite Phase, wie jeder Cluster‑Head seine Daten zur Basisstation senden sollte. Statt festen Routen zu folgen, behandelt QPSODRL jeden Cluster‑Head als Agenten in einem Lernprozess. In jedem Schritt beobachtet der Agent seine verbleibende Energie, die Energie und Entfernung benachbarter Heads sowie geschätzte Verzögerungen und wählt dann den nächsten Hop. Eine spezialisierte Form des Deep Q‑Learning, genannt Dueling Double Deep Q‑Network, schätzt, wie gut jede Wahl langfristig ist. Die Autoren fügen einen „Entropie“-Term hinzu, um zu verhindern, dass das System zu schnell zu selbstsicher wird, sodass es weiterhin alternative Routen erkundet. Außerdem entwerfen sie einen verbesserten Experience‑Replay‑Mechanismus, der das Lernen gezielt auf die informationsreichsten Situationen konzentriert — etwa wenn die Energie niedrig ist oder Verzögerungen ansteigen — sodass das Modell in den wichtigsten Szenarien schneller lernt. 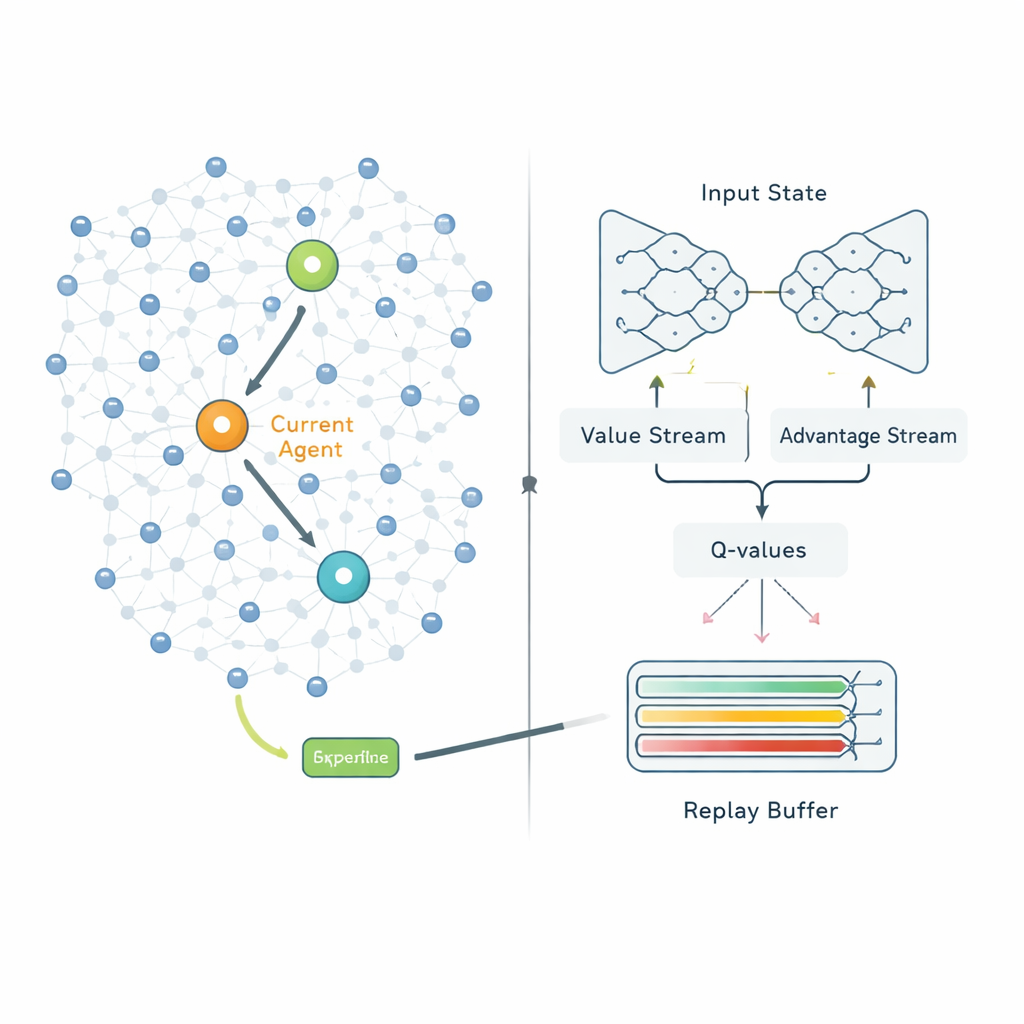
Der Ansatz im Praxistest
Um die Leistungsfähigkeit von QPSODRL zu prüfen, führen die Autoren detaillierte Computersimulationen von Netzwerken mit 100 und 200 Knoten durch, die über Gebiete unterschiedlicher Größe verteilt sind und unterschiedliche Anteile an Cluster‑Heads aufweisen. Das neue Protokoll wird mit vier aktuellen und fortschrittlichen Wettbewerbern verglichen, die Partikelschwärme, Wal‑Optimierung, Fuzzy‑Logik oder andere hybride und lernbasierte Schemata verwenden. In allen getesteten Konfigurationen hält QPSODRL das Netzwerk über mehr Kommunikationsrunden am Leben, liefert mehr Datenpakete zur Basisstation und verbraucht insgesamt weniger Energie. Es verteilt die Arbeitslast unter den Cluster‑Heads außerdem gleichmäßiger, wie eine geringere Variation in der von jedem Head bearbeiteten Verkehrslast zeigt. Diese Verbesserungen sind besonders ausgeprägt in anspruchsvolleren Layouts, in denen die Basisstation am Rand des Feldes platziert ist und einige Knoten zu längeren Hops zwingt.
Was das für reale Systeme bedeutet
Für Nicht‑Spezialisten lautet die Kernbotschaft, dass die Fähigkeit von Sensornetzwerken, sowohl ihre Struktur global zu optimieren als auch lokal aus Erfahrung zu lernen, ihre Nutzungsdauer deutlich verlängern kann. Das quanteninspirierte Clustering von QPSODRL hält den Energieeinsatz ausgeglichen, während das auf Deep Learning basierende Routing sich an veränderte Bedingungen anpasst, ohne ständige manuelle Nachjustierung. Obwohl die Ergebnisse auf Simulationen mit stationären, nicht beweglichen Knoten basieren, legen sie nahe, dass künftige Sensoreinsätze — von Smart Cities bis zu Umweltbeobachtungsstationen — durch ähnliche intelligente Steuerungsstrategien länger laufen, seltener ausfallen und die begrenzte Batterieleistung besser nutzen könnten.
Zitation: Guangjie, L. QPSODRL: an improved quantum particle swarm optimization and deep reinforcement learning based intelligent clustering and routing protocol for wireless sensor networks. Sci Rep 16, 5526 (2026). https://doi.org/10.1038/s41598-026-35365-0
Schlüsselwörter: drahtlose Sensornetzwerke, energieeffizientes Routing, Deep Reinforcement Learning, Schwarmoptimierung, Netzwerk‑Clustering