Clear Sky Science · de
Wissensintegration für physikgeleitete symbolische Regression mithilfe vortrainierter großer Sprachmodelle
Computern beibringen, die Formeln der Natur zu erraten
Viele der großen Ideen in der Wissenschaft lassen sich in prägnanten Gleichungen ausdrücken: vom Fall eines Balls bis zu den Wellen des Lichts im Raum. Dieses Paper untersucht eine neue Methode, um Computern zu helfen, solche Gleichungen automatisch aus Rohdaten wiederzuentdecken, indem sie ein großes Sprachmodell — die gleiche Art von KI, die moderne Chatbots antreibt — zu Rate ziehen, sodass ihre Vermutungen nicht nur genau, sondern auch physikalisch sinnvoll sind.
Von Rohdaten zu menschenlesbaren Gesetzen
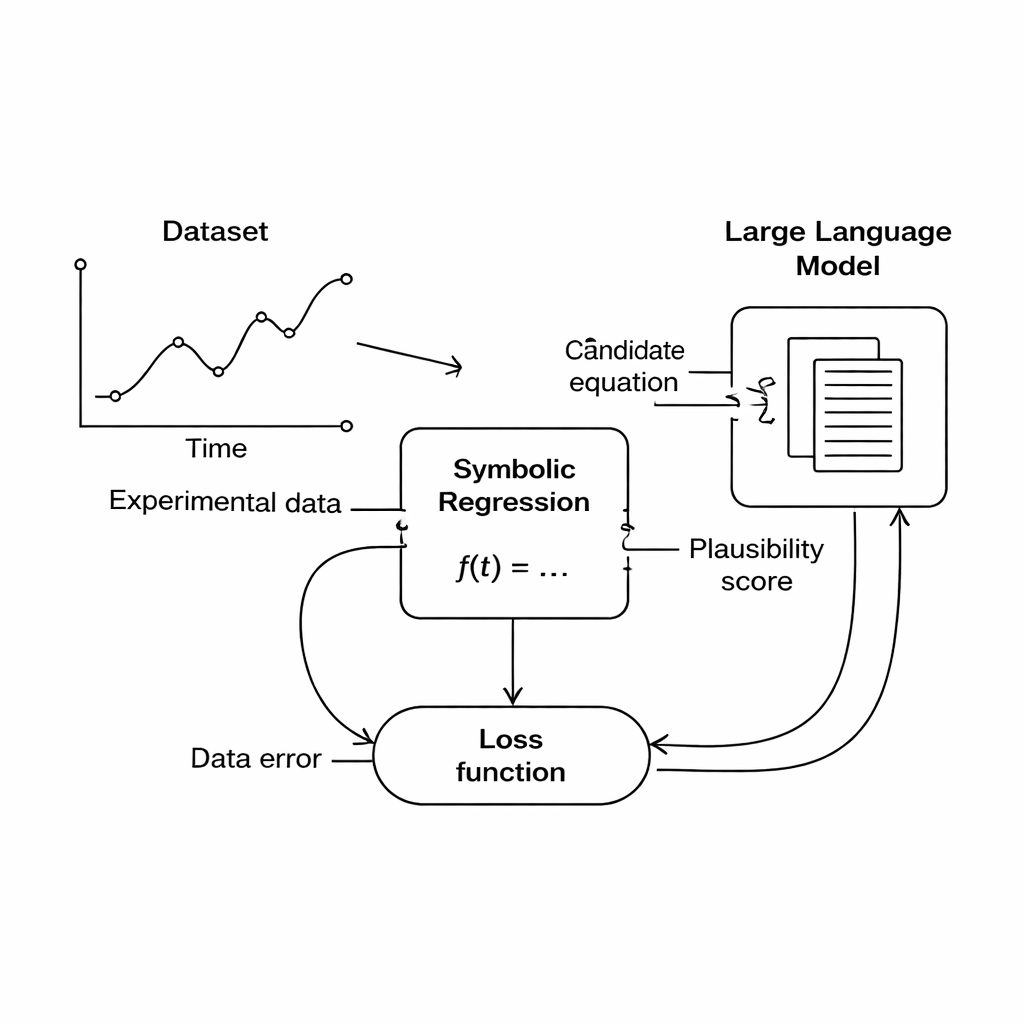
Die Autorinnen und Autoren konzentrieren sich auf eine Technik namens symbolische Regression, die nach einer mathematischen Formel sucht, die gemessene Eingangs- und Ausgangsgrößen verknüpft. Im Unterschied zur üblichen Kurvenanpassung beginnt die symbolische Regression nicht mit einer festen Form; stattdessen erzeugt und entwickelt sie Kandidatengleichungen, bis eine gut zu den Daten passt. Das macht sie zu einem vielversprechenden Werkzeug für wissenschaftliche Entdeckungen, weil sie potenziell neue Zusammenhänge finden kann, die bislang niemand formuliert hat. Es gibt jedoch einen Haken: Eine Gleichung, die die Daten perfekt beschreibt, kann aus physikalischer Sicht trotzdem Unsinn sein — etwa Entfernungen zu Zeiten addieren oder Einheiten erzeugen, die zu keiner realen Größe passen.
Warum physikalische Einsicht weiterhin zählt
Um solchen Unsinn zu vermeiden, haben Forschende „physik-informierte“ Varianten der symbolischen Regression entwickelt, die bekannte Naturgesetze in die Suche einbinden. Diese Methoden belohnen Gleichungen, die beispielsweise Energie erhalten oder dimensionskonsistent sind. Das Einbetten dieses Wissens erforderte jedoch typischerweise, dass Expertinnen und Experten Constraints und spezielle Loss-Funktionen für jedes neue Problem von Hand entwerfen. Das macht den Ansatz zwar mächtig, aber schwer zu verallgemeinern. Jedes neue physikalische System kann eigene sorgfältige Gestaltungsarbeit brauchen, was die Zugänglichkeit dieser Werkzeuge für Nicht-Expertinnen und -Experten einschränkt.
Das Sprachmodell die Gleichungen bewerten lassen
Die Studie schlägt einen anderen Weg vor: Statt Domänenregeln hart zu kodieren, soll ein großes Sprachmodell (LLM) als flexibler Prüfer wissenschaftlicher Plausibilität dienen. Während der Suche erzeugt die symbolische-Regression-Engine Kandidatengleichungen, die die Daten bis zu einem gewissen Grad beschreiben. Jede Gleichung wird dann in Text übersetzt und zusammen mit einer kurzen Eingabeaufforderung gesendet, die die beteiligten Größen und bekannte physikalische Einschränkungen beschreibt. Das LLM gibt Bewertungen in drei Bereichen zurück: ob die Einheiten sinnvoll sind, wie einfach die Gleichung ist und ob sie physikalisch realistisch wirkt. Diese Bewertungen werden in die Hauptzielgröße eingearbeitet, sodass der Computer nun bei der Auswahl, welche Gleichungen weiter verbessert werden, zwischen „passt zu den Daten“ und „wirkt nach guter Physik“ abwägt.
Die Methode auf die Probe stellen
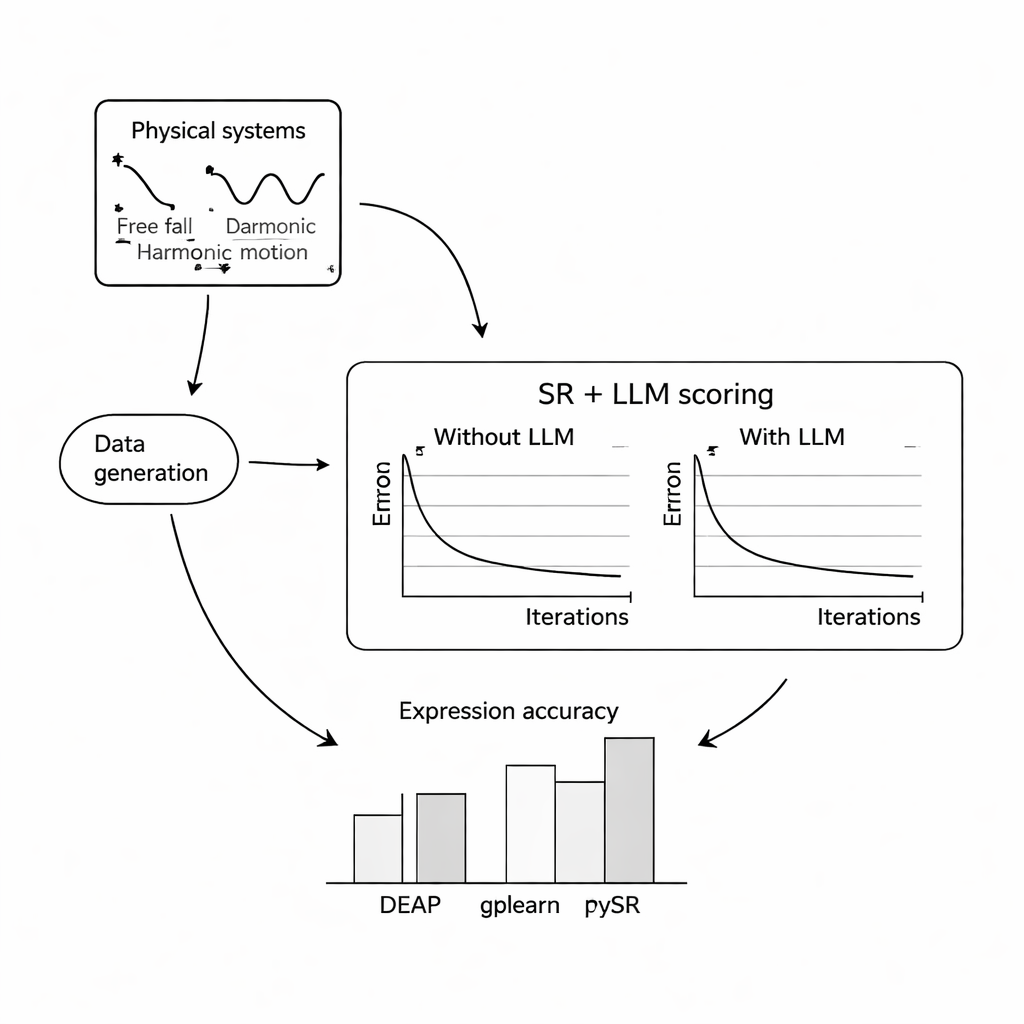
Um zu prüfen, wie gut das funktioniert, führten die Autorinnen und Autoren umfangreiche Computersimulationen an drei klassischen Problemen durch: dem freien Fall eines Balls in der Erdanziehung, der harmonischen Schwingung einer Masse an einer Feder und einer gedämpften elektromagnetischen Welle. Für jedes System simulierten sie Tausende verrauschte Messungen unter unterschiedlichen Bedingungen und baten dann drei gängige symbolische-Regression-Programme, die zugrundeliegenden Gleichungen entweder mit oder ohne Unterstützung eines LLM wiederzufinden. Sie testeten drei kompakte, quelloffene Sprachmodelle — Mistral, Llama 2 und Falcon — und untersuchten, wie verschiedene Prompt-Designs, von minimalem Kontext über vollständige Beschreibungen bis hin zur wahren Formel, die LLM-gesteuerte Bewertung veränderten. In den meisten Szenarien verbesserte die Hinzunahme der LLM-Bewertung, wie eng die wiederentdeckten Gleichungen den bekannten Gesetzen entsprachen, und machte sie robuster gegenüber Rauschen; die Kombination aus PySR (einer Bibliothek für symbolische Regression) und Mistral zeigte sich dabei meist am besten.
Wenn Worte die Mathematik lenken
Ein zentrales Ergebnis ist, dass die Formulierung des Prompts die Ergebnisse stark beeinflusst. Wenn Prompts klare Beschreibungen der Variablen, der Versuchsbedingungen und mitunter die exakte Zielformel enthielten, konvergierte die LLM-gestützte Suche zuverlässiger zur korrekten Struktur. In diesen reichhaltigeren Fällen waren die gefundenen Gleichungen oft strukturell identisch mit den Ground-Truth-Gesetzen, nicht nur numerisch ähnlich. Die Autorinnen und Autoren testeten auch, wie die Methode bei zunehmendem Messrauschen standhält. Während alle Methoden an Genauigkeit verloren, je rauschiger die Daten und je komplexer die zugrundeliegenden Gleichungen wurden, neigten die mit LLM erweiterten Versionen dazu, langsamer an Genauigkeit einzubüßen als ihre Standard-Pendants, was darauf hindeutet, dass das Plausibilitätsgefühl des Sprachmodells eine stabilisierende Wirkung haben kann.
Was das für zukünftige Entdeckungen bedeutet
Für ein allgemeines Publikum ist die Kernbotschaft: textbasierte KI kann mehr als Aufsätze schreiben oder Fragen beantworten — sie kann auch andere Algorithmen dabei leiten, wissenschaftliche Gleichungen zu finden, die sich nach unserem bestehenden Naturwissen „richtig anfühlen“. Die hier vorgestellte Methode garantiert nicht, dass jede gefundene Gleichung korrekt ist; sie benötigt weiterhin menschliche Aufsicht und sorgfältig formulierte Prompts. Aber sie zeigt, dass große Sprachmodelle, die auf Unmengen wissenschaftlicher Texte trainiert wurden, als wiederverwendbare Wissensquelle dienen können und automatisierten Werkzeugen helfen, vom blinden Anpassen von Daten hin zu Vorschlägen für Gesetze zu gelangen, die Forschende interpretieren, prüfen und weiterentwickeln können.
Zitation: Taskin, B., Xie, W. & Lazebnik, T. Knowledge integration for physics-informed symbolic regression using pre-trained large language models. Sci Rep 16, 1614 (2026). https://doi.org/10.1038/s41598-026-35327-6
Schlüsselwörter: symbolische Regression, physik-informierte KI, große Sprachmodelle, wissenschaftliche Entdeckung, Gleichungslernen