Clear Sky Science · de
Ein tiefes Reinforcement-Learning-Verfahren zur Analyse von Tanzbewegungen
Computern beibringen, Tanz so zu sehen wie wir
Von Ballett bis Hip-Hop steckt Tanz voller feiner Verschiebungen in Rhythmus und Haltung, die das menschliche Auge sofort erfasst — für Computer sind diese aber schwer zu erkennen. Diese Studie stellt einen neuen Weg vor, wie künstliche Intelligenz Tanzvideos eher wie ein menschlicher Experte „anschauen“ kann, indem sie routinemäßige Sequenzen überspringt und sich auf kurze, aussagekräftige Momente konzentriert, die einen Stil definieren. Das Ergebnis ist ein System, das Tanzgenres genauer erkennt, während es deutlich weniger Videomaterial betrachtet — ein möglicher Vorteil für digitale Archive sowie Sport- und Unterhaltungstechnologien.
Warum Tanzvideos für Maschinen schwierig sind
Auf den ersten Blick scheint es einfach, einen Computer zum Erkennen von Tanzstilen zu trainieren: Videos einspeisen und Deep Learning die Muster finden lassen. In Wirklichkeit verschwenden die meisten bestehenden Systeme jedoch Aufwand. Übliche Videomodelle verarbeiten entweder jedes Einzelbild oder sampeln Clips in festen Intervallen und nehmen an, alle Momente seien gleich wichtig. Tanzstile unterscheiden sich aber oft in winzigen Details — wie ein Fuß sich dreht, wann ein Partner pivotiert oder das Timing einer Drehung — statt in durchgehender Bewegung. Das bedeutet, viele Frames sind repetitiv oder wenig informativ, und entscheidende Posen können zwischen festen Stichproben liegen, was zu Verwechslungen zwischen etwa Walzer und Foxtrott führt.
Ein klügerer Weg, Videos zu durchforsten
Die Forschenden schlagen ein Framework namens Reinforcement-based Attentive Temporal Sampling (RATS) vor, das Videoanalyse als aktive Suche statt passives Betrachten behandelt. Statt Frame für Frame abzuarbeiten, zerlegt das System ein Tanzvideo in kurze Clips und wandelt jeden Clip zunächst in eine kompakte Beschreibung der Bewegung mithilfe eines spezialisierten 3D-Convolutional-Netzwerks um. Diese Bewegungszusammenfassungen werden dann im Speicher abgelegt. Darauf aufbauend durchschreitet ein Entscheidungsagent die Clipfolge und wählt jeweils, ob er mit einem kleinen Sprung, einem größeren Sprung weitermacht oder anhält und eine Stilvorhersage trifft. Effektiv lernt das System, wie es zeitlich browsen sollte, bei aussagekräftigen Mustern zu verweilen und weniger nützliche Abschnitte zu überspringen.
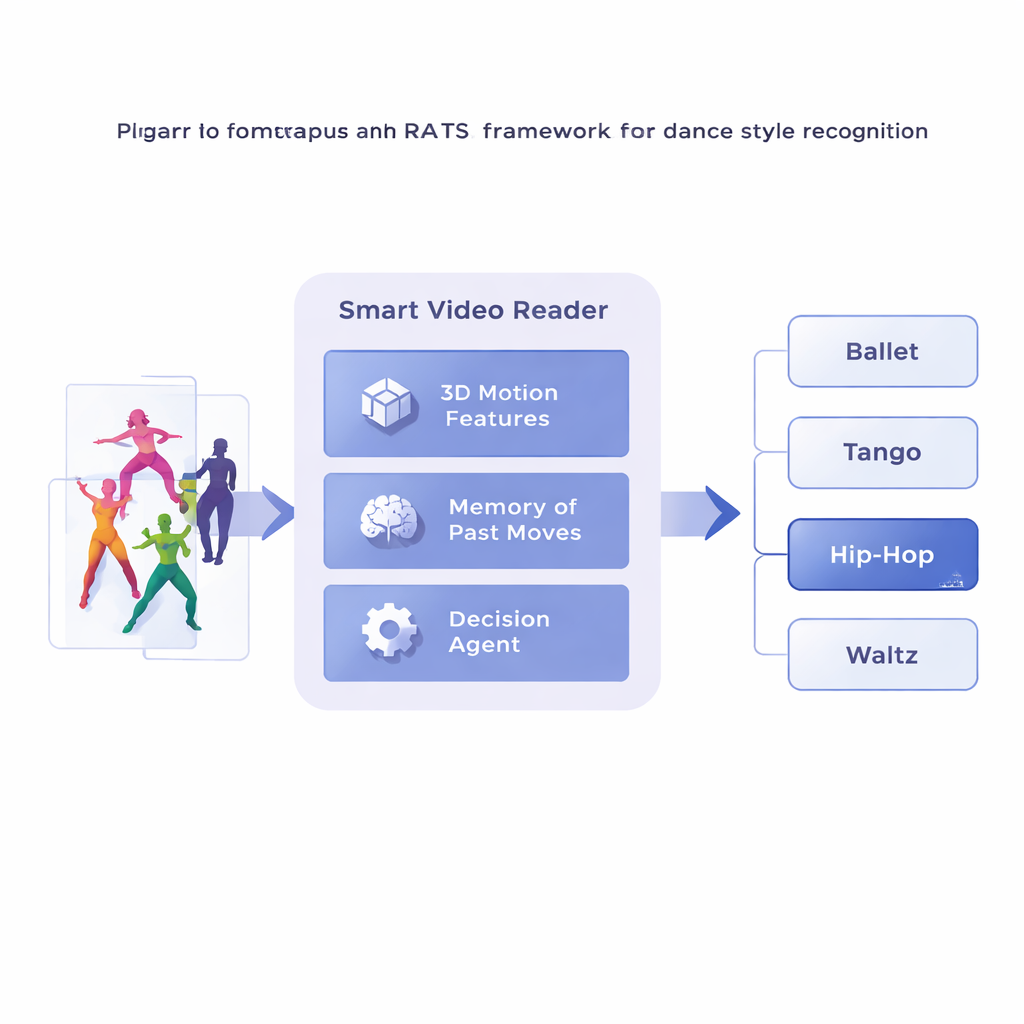
Lernen, wann man hinschaut und wann man entscheidet
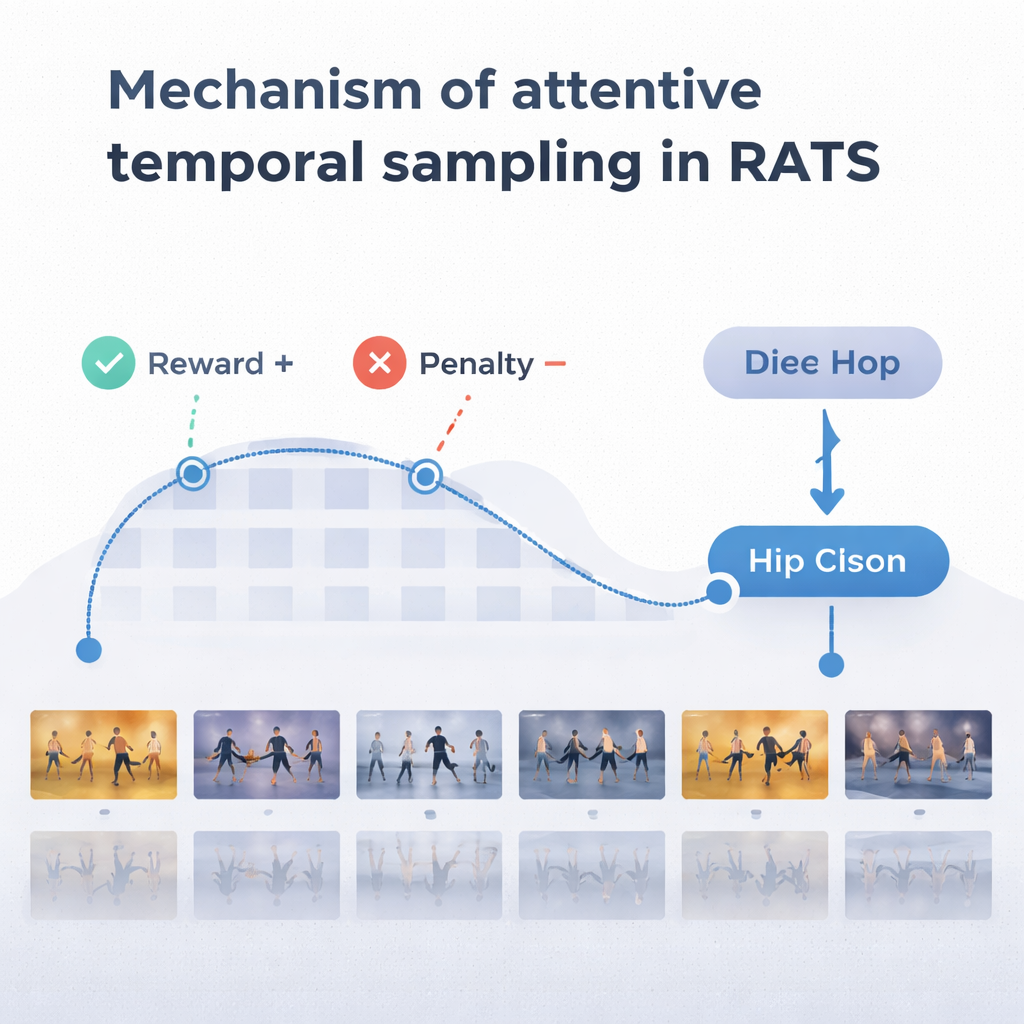
Um sinnvolle Entscheidungen zu treffen, stützt sich der Agent auf eine Form von Gedächtnis, die davon inspiriert ist, wie wir sowohl vergangene als auch aufkommende Bewegungen erinnern. Ein bidirektionales rekurrentes Netzwerk verfolgt, was das System bereits „gesehen“ hat und wie aktuelle Clips zu dieser Historie stehen. In jedem Schritt wägt der Agent drei Optionen ab: einen kurzen Sprung, um feinere Details wie Fußarbeit zu untersuchen, einen längeren Satz über repetitive Bewegungen hinweg oder anhalten und die Tanzklasse bestimmen. Das System wird mit Belohnungen und Strafen trainiert: Es erhält eine große positive Belohnung für eine richtige Entscheidung, eine große negative bei einer falschen und eine kleine Strafe jedes Mal, wenn es vorwärts springt. Dieses Gleichgewicht fördert Genauigkeit und Effizienz zugleich — warten, bis genügend Belege vorliegen, aber nicht das ganze Video durchwandern.
Konventionelle Tanzklassifizierer übertreffen
Das Team testete RATS am Let’s Dance-Datensatz, einer herausfordernden Sammlung von 1.000 Videos mit zehn Stilen, von Flamenco und Tango bis Swing und Square Dance. Im Vergleich zu mehreren bestehenden Methoden, darunter Standard-Deep-Netzwerke und andere auf Tanz fokussierte Modelle, erzielte RATS die höchste Genauigkeit — etwa 92 % — und das beste Gleichgewicht von Präzision und Trefferquote. Es zeigte sich auch statistisch besser als starke Konkurrenz, nicht nur durch Zufall leicht unterschiedlich. Wichtig ist, dass das System diese Ergebnisse erzielte, während es im Mittel nur etwa 38 % der Videoframes analysierte. Gleichmäßiges Sampeln alle paar Frames war zwar schneller, verpasste aber entscheidende Momente und verschlechterte die Leistung; die Verarbeitung jedes Frames war langsamer und dennoch weniger genau als der zielgerichtete Ansatz.
Was das über die Tanzfläche hinaus bedeutet
Für Nicht-Fachleute ist die Kernbotschaft einfach: Computer können besser arbeiten, wenn sie lernen, selektive Zuschauer zu sein. Indem man einer KI beibringt, sich auf die „Goldenen Momente“ in der Zeit zu konzentrieren, zeigt diese Arbeit, dass Maschinen komplexe menschliche Bewegungen genauer erkennen können und dabei weniger Ressourcen benötigen. Obwohl die Studie sich auf Tanz konzentriert, könnte dieselbe Idee Systemen helfen, Schlüsselmomente in Sportabläufen, Sicherheitsaufnahmen oder jedem langen Video zu finden, in dem wichtige Ereignisse kurz und verstreut auftreten. Anders gesagt: klügeres Beobachten — nicht mehr Beobachten — könnte die Zukunft des Videoverstehens sein.
Zitation: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
Schlüsselwörter: Tanzerkennung, Videoanalyse, Deep Learning, Reinforcement Learning, menschliche Bewegung