Clear Sky Science · de
Chinesisches Modell zur Extraktion räumlicher Beziehungen durch Integration geographischer semantischer Merkmale
Computern beibringen, zu verstehen, wo Orte liegen
Jeden Tag beschreiben wir Standorte in einfachen Wendungen: Eine Stadt liegt südlich eines Flusses, ein Park ist in der Nähe einer Universität, eine Autobahn verläuft durch eine Provinz. Solche alltäglichen Formulierungen in präzises digitales Wissen zu überführen, ist für intelligente Karten, Navigationsapps und geografische Forschung entscheidend. Dieses Paper stellt eine neue Methode vor, PURE‑CHS‑Attn, die Computern hilft, chinesische Texte zu lesen und die räumlichen Beziehungen zwischen Orten genauer als bisher zu bestimmen.
Warum räumliche Sprache wichtig ist
Räumliche Beziehungen sind Wörter und Wendungen, die beschreiben, wie Orte im Raum zueinander stehen, etwa „innerhalb“, „neben“, „nördlich von“ oder „30 Kilometer entfernt“. Sie schlagen eine Brücke zwischen der realen Welt auf Karten und den Konzepten in unserem Kopf. In Geoinformationssystemen (GIS) bilden diese Relationen die Grundlage dafür, wie Daten organisiert, durchsucht und analysiert werden. Sie sind auch in anderen Bereichen zentral: etwa beim Kombinieren von Satellitenbildern, beim Verfolgen von Bewegungen in Videos, bei der Planung von Industrieanlagen oder beim Studium, wie Klima und Landformen die Biodiversität prägen. Da viele dieser Informationen in natürlicher Sprache verfasst sind, werden zuverlässige Werkzeuge, die Texte lesen und räumliche Relationen automatisch extrahieren, zunehmend wichtig.
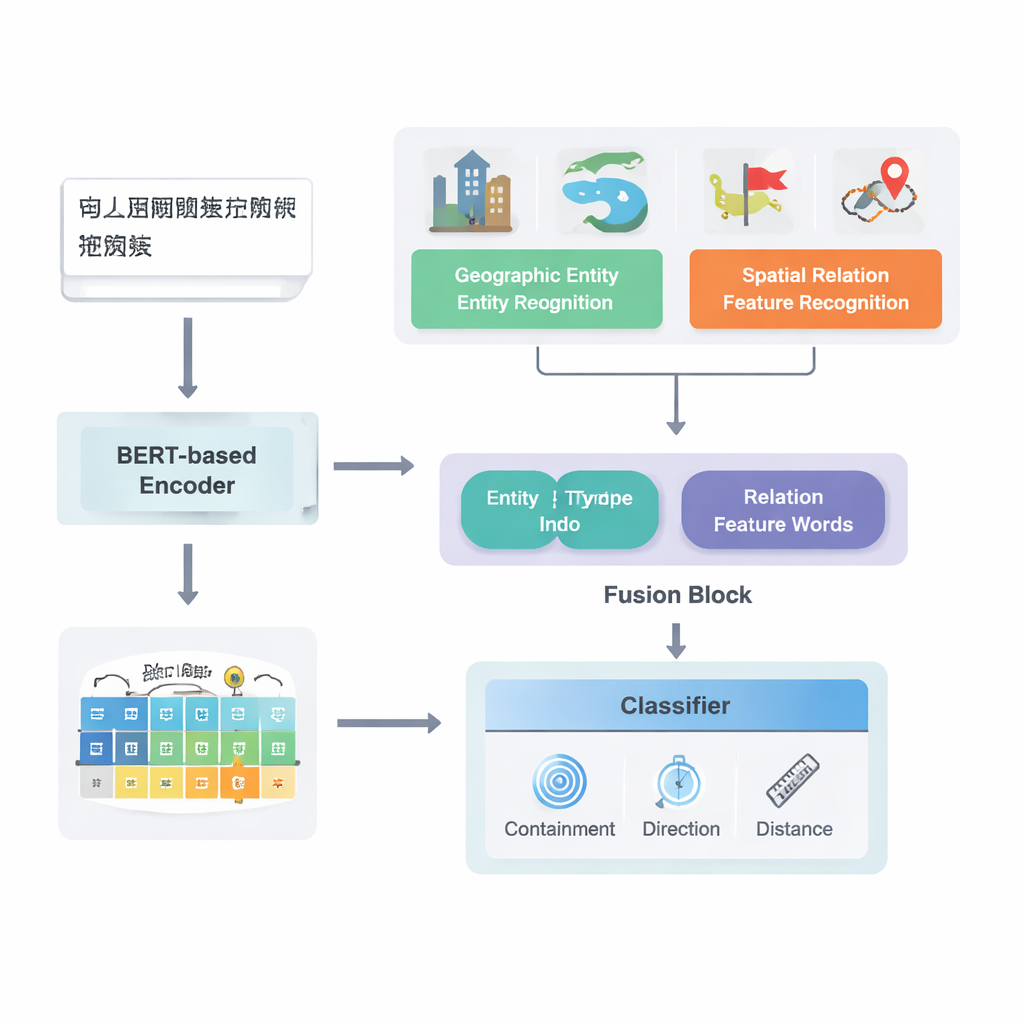
Vom Rohtext zu kartierten Beziehungen
Die Autorinnen und Autoren konzentrieren sich auf chinesische Texte und bauen auf einer starken existierenden Deep‑Learning‑Pipeline namens PURE auf. Ihr erweitertes Modell PURE‑CHS‑Attn arbeitet in mehreren Stufen. Zuerst durchsucht es Sätze nach geografischen Entitäten wie Bergen, Flüssen, Städten und Verwaltungseinheiten und kennzeichnet jede mit einem Typ (z. B. Landfläche, Gewässer, öffentliche Einrichtung, historischer Ort oder Verwaltungseinheit). Anschließend erkennt es räumliche „Merkworter“ wie „grenzt an“, „durchfließt“, „südlich von“ oder „in der Nähe von“, die anzeigen, wie zwei Orte zusammenhängen. Ein leistungsfähiges Sprachmodell, BERT‑wwm‑ext, wandelt die Zeichen in jedem Satz in numerische Vektoren um, die Bedeutung und Kontext erfassen. Diese Vektoren speisen getrennte Komponenten, die Entitäten und Relationswörter erkennen und ihre Ergebnisse an ein Fusionsmodul weitergeben.
Menschliches Wissen mit maschinellem Lernen verbinden
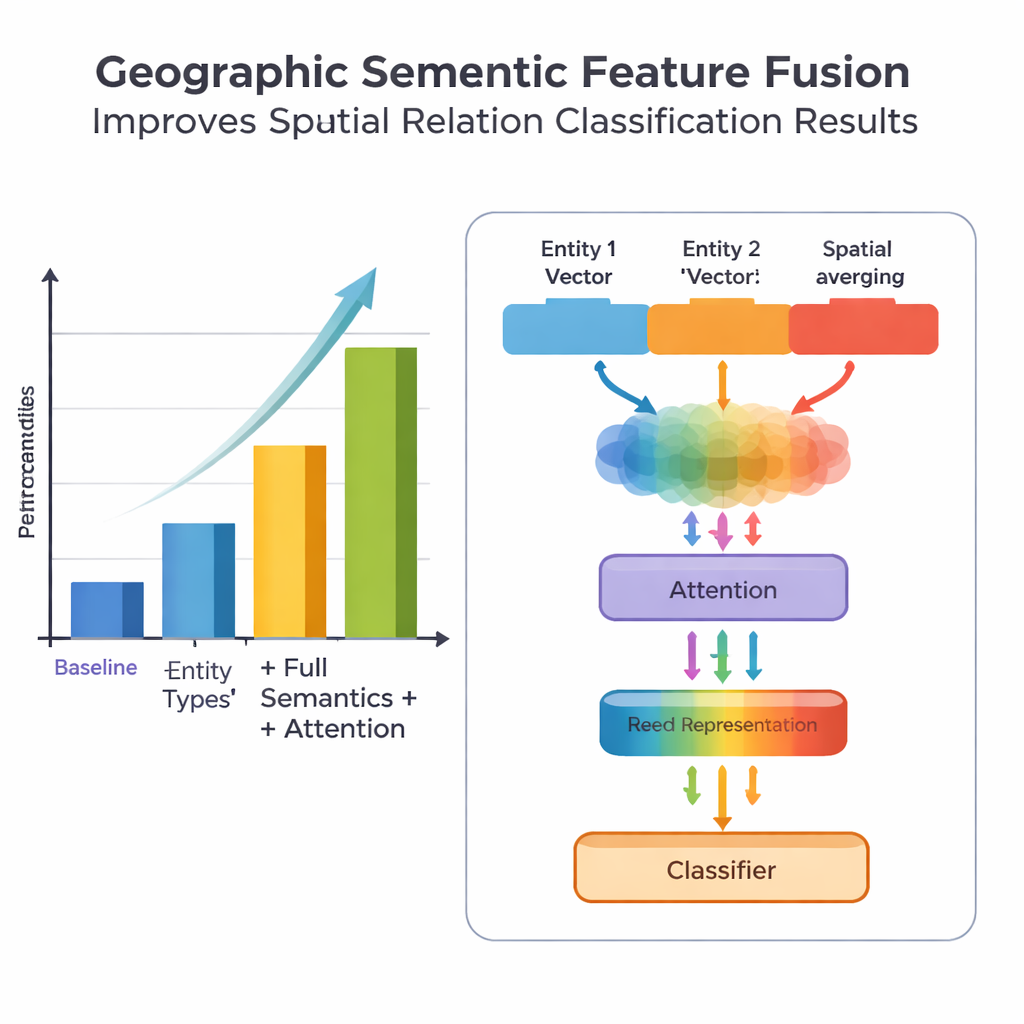
Eine wesentliche Neuerung der Arbeit liegt in der Verbindung geographischen Wissens mit erlernten Textmustern. Statt jedes Wort gleich zu behandeln, nutzt das Modell zwei Arten semantischer Informationen, die Menschen natürlich verwenden: den Typ jeder geografischen Entität und die speziellen räumlichen Merkwoerter, die sie verbinden. Das Fusionsmodul kombiniert zunächst die Vektoren der beiden Entitäten mit Gewichtungen, die davon abhängen, wie häufig verschiedene Ortstypen (etwa zwei Verwaltungseinheiten gegenüber einem Fluss und einem Kreis) an bestimmten Relationstypen beteiligt sind. Anschließend werden die Vektoren der räumlichen Merkwoerter einbezogen. Auf diese „Grundfusion“ setzen die Autorinnen und Autoren einen Aufmerksamkeitsmechanismus (Attention), der dem Modell erlaubt, dynamisch die informationsreichsten Teile der Entitäts–Wort‑Kombination zu fokussieren. Die abschließend verschmolzene Repräsentation wird an einen Klassifikator übergeben, der jeweils ein oder mehrere Relationstypen zuweisen kann — topologische (z. B. Einschluss oder Adjazenz), richtungsbezogene (Nord, Süd usw.) oder distanzbasierte — zwischen jedem Paar von Orten im Satz.
Das Modell im Test
Zur Bewertung ihres Ansatzes stellte das Team ein sorgfältig annotiertes Datenset aus der Enzyklopädie der China: Chinesische Geographie zusammen, das 1381 Sätze und 368 räumliche Relationspaare enthält. Sie verglichen mehrere Modellvarianten: ein Basismodell, das nur grobe Ortsinformationen nutzt, eine Version mit feineren Entitätstypen, eine Variante, die zusätzlich räumliche Merkwoerter einbezieht, und ihr vollständiges PURE‑CHS‑Attn‑Modell mit neuer Fusions‑ und Attention‑Architektur. Gemessen an Standardmetriken wie Präzision, Recall und F1 erzielte PURE‑CHS‑Attn gegenüber dem Baseline‑Modell Verbesserungen von etwa 7 % in Präzision, 6,5 % im Recall und 6,7 % in F1. Besonders stark war es bei der Erkennung topologischer und richtungsbezogener Relationen, und es bewältigte seltene „Few‑Shot“‑Relationstypen besser als einfachere Modelle. Im Vergleich mit drei aktuellen State‑of‑the‑Art‑Systemen, darunter eines auf Basis großer Sprachmodelle, landete PURE‑CHS‑Attn knapp auf dem zweiten Platz, blieb dabei jedoch deutlich leichter und einfacher einzusetzen.
Herausforderungen und zukünftige Richtungen
Trotz dieser Fortschritte hat das Modell weiterhin Schwierigkeiten mit Distanzrelationen, insbesondere wenn nur sehr wenige Trainingsbeispiele vorliegen. Die Autorinnen und Autoren zeigen, dass ihr Datensatz nur sehr wenige solche Fälle enthält, was die Lernfähigkeit datenhungriger Methoden einschränkt. Sie stellen außerdem fest, dass das blinde Mittelwertbilden vieler räumlicher Merkwoerter in einem Satz Rauschen einführen kann, das ihr Attention‑Mechanismus zwar lindert, aber nicht vollständig beseitigt. Für die Zukunft schlagen sie zwei vielversprechende Wege vor: das Erweitern und Ausbalancieren der Trainingsdaten durch Augmentation sowie die Kombination ihrer geographischen semantischen Fusion mit Techniken aus dem Bereich großer Sprachmodelle und Prompt‑basiertem Lernen, um die Leistung in datensparsamen Szenarien weiter zu verbessern und gleichzeitig die Effizienz des Systems zu erhalten.
Was das für alltägliche Kartierung bedeutet
Kurz gesagt: Diese Forschung lehrt Computer, räumliche Beschreibungen im Chinesischen menschlicher zu lesen, indem sie darauf achten, welche Arten von Orten erwähnt werden und wie genau deren Beziehungen formuliert sind. Das PURE‑CHS‑Attn‑Modell zeigt, dass die Verbindung strukturierter geographischer Kenntnisse mit modernem Deep Learning zu einer genaueren und robusteren Extraktion von „wer wo in Bezug auf was“ aus Texten führt. Das ebnet den Weg für intelligentere, stärker automatisierte GIS‑Systeme, reichere geographische Wissensgraphen und bessere Werkzeuge, um zu erforschen, wie Raum in Wissenschaft, Politik und Alltag beschrieben wird.
Zitation: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
Schlüsselwörter: Extraktion räumlicher Beziehungen, geodatenbasierte KI, geographische Semantik, chinesisches Text Mining, GIS‑Automatisierung