Clear Sky Science · de
Maschinelles Lernen zur Identifikation von Weizensorten anhand Einzelkornsaufnahmen
Warum intelligentere Saatgut-Sortierung wichtig ist
Für Landwirte und Saatgutunternehmen ist es entscheidend, eine Weizensorte von einer anderen zu unterscheiden. Die Aussaat der falschen Sorte kann geringere Erträge, schlechtere Krankheitsresistenz und Pflanzen zur Folge haben, die nicht an Boden oder Klima vor Ort angepasst sind. Für das bloße Auge sind verschiedene Weizensorten jedoch oft praktisch identisch. Diese Studie untersucht, wie künstliche Intelligenz und digitale Fotos einzelner Körner zuverlässig eng verwandte Sorten auseinanderhalten können und damit schnellere, günstigere und objektivere Qualitätskontrollen von Saatgut ermöglichen.
Vom Expertenblick zur kameragestützten Prüfung
Heute verlassen sich viele Saatgutprüfverfahren noch auf menschliche Expertinnen und Experten, die Samen visuell auf Sorte und Reinheit beurteilen. Dieser Prozess ist langsam, teuer und anfällig für Meinungsverschiedenheiten, zumal sich viele Weizensorten nur durch subtile Unterschiede in Form oder Oberflächenmuster unterscheiden. Die Autorinnen und Autoren wollten diesen subjektiven Ansatz durch ein automatisiertes System ersetzen, das Bilder einzelner Weizenkörner verwendet, aufgenommen in einer kleinen, lichtkontrollierten Box. Durch sorgfältige Standardisierung von Beleuchtung, Abstand und Hintergrundfarbe schufen sie eine klare visuelle Aufzeichnung von sechs verbreiteten iranischen Weizensorten und erzeugten Zehntausende Samenfotos zum Trainieren und Testen von Computermodellen.
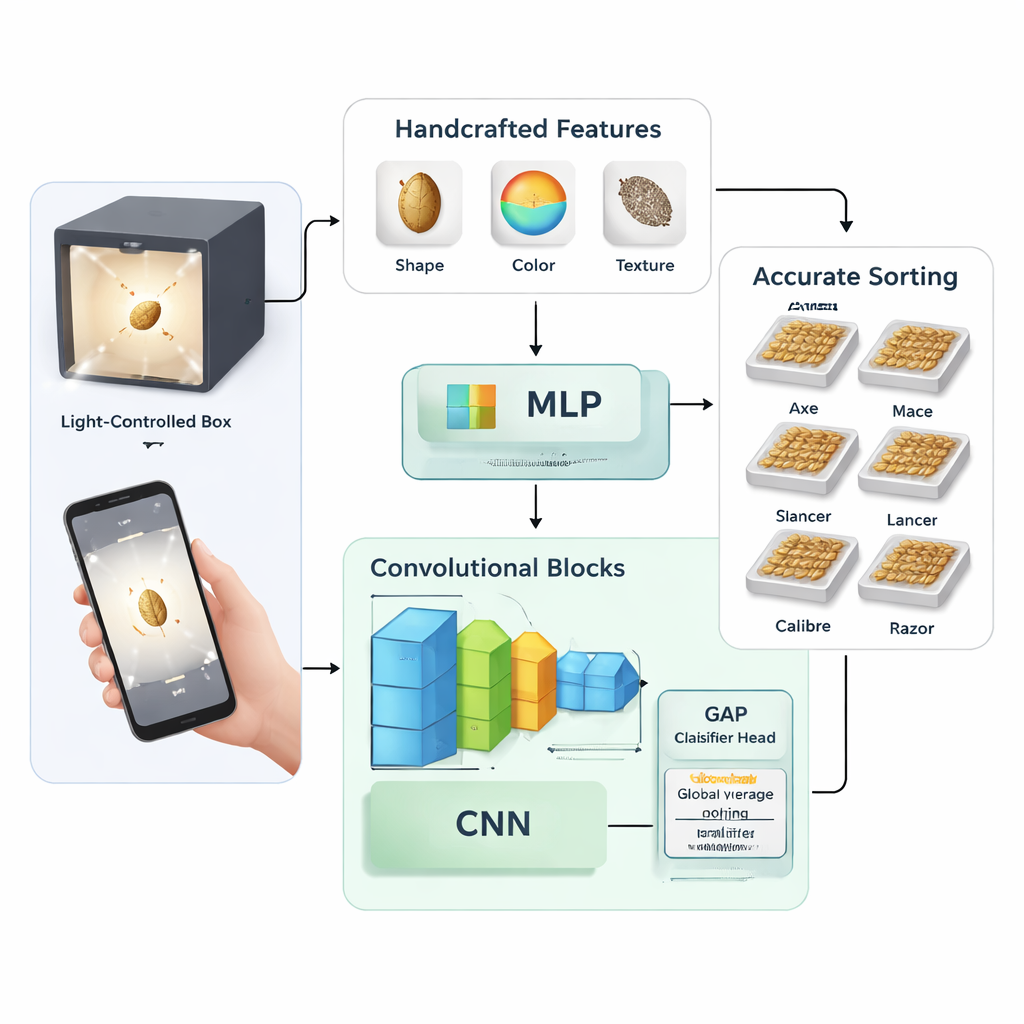
Zwei Wege, einem Computer das Sehen beizubringen
Die Studie vergleicht zwei grundlegende Strategien, einer Maschine das Erkennen von Weizensorten beizubringen. In der ersten extrahierten die Forschenden manuell 58 numerische Messgrößen aus jedem Samenbild, darunter grundlegende Formmerkmale (wie Länge und Fläche), Farbstatistiken in verschiedenen Farbräumen und Texturmuster. Mit Hilfe der Hauptkomponentenanalyse reduzierten sie diese Messwerte auf 27 Schlüsselmerkmale, die einem klassischen neuronalen Netzwerk, einem Multilayer-Perzeptron, zugeführt wurden. In der zweiten Strategie übersprangen sie das manuelle Feature‑Design und trainierten Faltungsnetzwerke (Convolutional Neural Networks) — bildfokussierte KI‑Modelle — die nützliche Muster direkt aus den Rohpixeln lernen.
Ein schlankes, aber leistungsfähiges Deep‑Learning‑Modell
Der Deep‑Learning‑Ansatz wurde in mehreren Varianten getestet. Die Autorinnen und Autoren entwarfen ein eigenes vergleichsweise kleines Netzwerk mit zwei bis vier gestapelten Faltungsblöcken und experimentierten mit verschiedenen Trainingsparametern wie Lernrate, Dropout‑Level und Batch‑Größe. Außerdem verglichen sie zwei Abschlussstrategien: eine klassische voll verknüpfte Schicht versus eine kompaktere Methode namens Global Average Pooling, die große dichte Schichten durch einen einfachen Durchschnittsschritt vor der finalen Klassifikation ersetzt. Zum Vergleich feinabstimmten sie zwei leistungsstarke, weit verbreitete Architekturen — Inception‑ResNet‑v2 und EfficientNet‑B4 — auf demselben Weizendatensatz, um zu sehen, wie sich ein maßgeschneidertes kleines Modell gegenüber tiefen, allgemeingültigen Netzen schlägt.
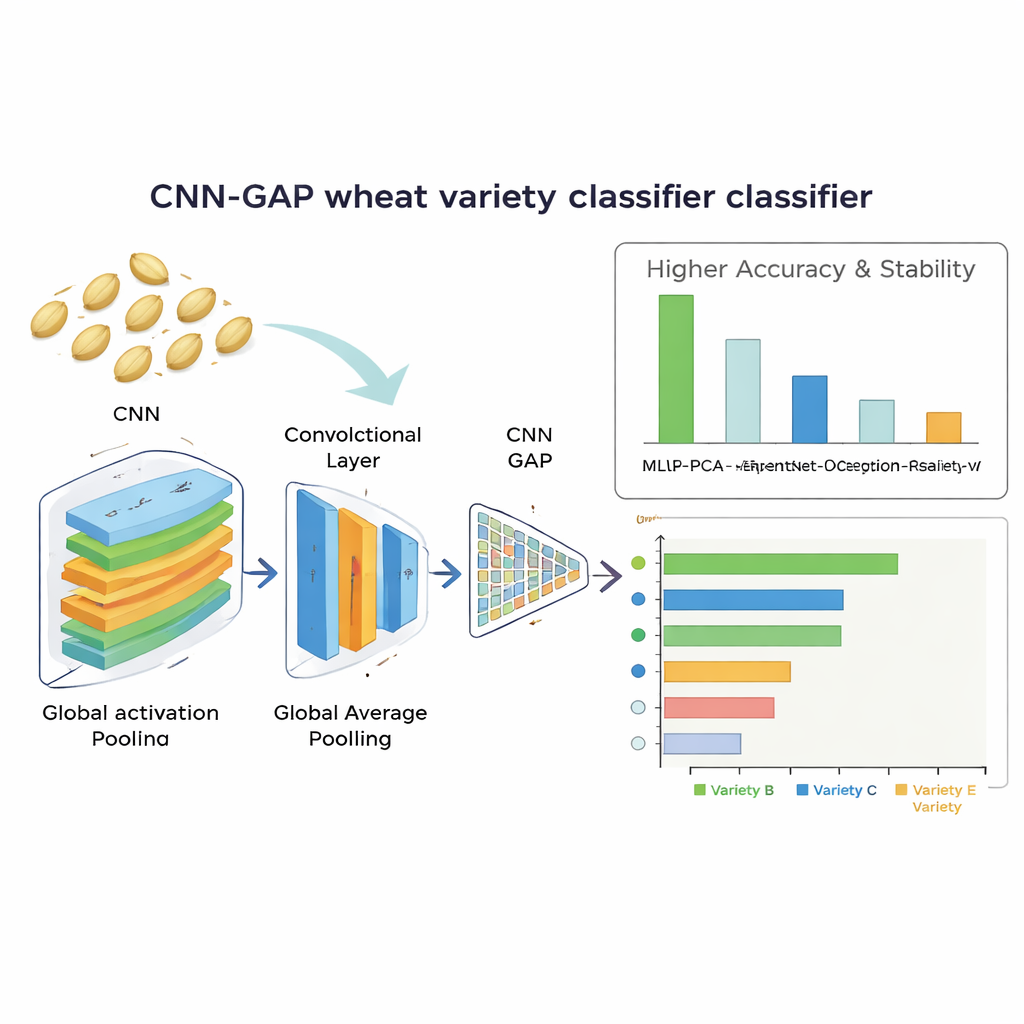
Wie zuverlässig das System die Körner erkennt
Bestes Ergebnis erzielte das maßgeschneiderte Faltungsnetz mit Global Average Pooling. Es identifizierte Weizensorten in etwa 92 % der Fälle korrekt und zeigte dabei sehr stabile Ergebnisse über mehrere Trainingsläufe. Dieses Modell übertraf nicht nur die großen vortrainierten Netze, sondern auch den Ansatz mit handgefertigten Merkmalen, der nach der Dimensionsreduktion etwa 86 % Genauigkeit erreichte. Die Analyse der Verwechslungsmuster zeigte, dass das leichtere Modell besonders gut darin war, Sorten zu trennen, die visuell sehr ähnlich sind, während die tieferen Transfer‑Learning‑Modelle dazu neigten, bei dem begrenzten Datensatz zu überfitten. Wichtig ist auch, dass das Gewinnernetzwerk effizient war: Es verarbeitete jedes Samenbild in ungefähr 13,6 Millisekunden und enthielt nur rund 2,1 Millionen einstellbare Parameter, was es für den Einsatz in kostengünstiger, echtzeitfähiger Sortierhardware realistisch macht.
Beschränkungen, Praxiseinsatz und Ausblick
Wurde dasselbe Modell an einer völlig anderen Kultur getestet — Kichererbsensamen — sank die Genauigkeit stark, was zeigt, dass ein System, das auf feine Unterschiede zwischen Weizenkernen abgestimmt ist, nicht automatisch auf andere Arten übertragbar ist. Ebenso kann die Leistung abnehmen, weil alle Trainingsbilder aus einer sorgfältig kontrollierten Kammer stammten und unter variabler Feldbeleuchtung oder bei teilweise verdeckten Körnern schlechtere Ergebnisse möglich sind. Dennoch zeigt die Arbeit, dass ein kompaktes, gut gestaltetes Deep‑Learning‑Modell, das mit standardisierten Einzelkornaufnahmen gefüttert wird, zuverlässig Weizensorten unterscheiden kann, die mit bloßem Auge kaum zu trennen sind. Mit breiteren Trainingsdaten und variableren Aufnahmebedingungen könnten ähnliche Systeme zu praktischen Werkzeugen für automatisierte Saatgutzertifizierung werden und Landwirtinnen und Landwirten helfen, reinere Saatgutmengen und besser planbare Erträge zu sichern.
Zitation: Bagherpour, H., Shamohammadi, S. Machine learning approach for wheat variety identification using single-seed imaging. Sci Rep 16, 6472 (2026). https://doi.org/10.1038/s41598-026-35252-8
Schlüsselwörter: Weizensamen, Deep Learning, bildbasierte Klassifikation, Samenqualität, präzise Landwirtschaft