Clear Sky Science · de
Bewertung der Genauigkeit maschinell gelernter Kernreaktordaten in vollständigen Kern‑Monte‑Carlo‑Neutronik‑ und Effizienz‑Analysen
Warum schnellere Reaktorsimulationen wichtig sind
Kernkraftwerke verlassen sich auf detaillierte Computermodelle, um vorherzusagen, wie sich Brennstoff über Monate und Jahre Betrieb verhält. Diese Modelle sind entscheidend für Sicherheit, Effizienz und das Design neuer Reaktoren, sind aber berüchtigt langsam und speicherintensiv. Diese Arbeit untersucht, ob Maschinelles Lernen die umfangreichen Kernreaktordaten, die diese Simulationen antreiben, stark reduzieren kann — und zwar ohne die physikalische Genauigkeit zu opfern, auf die Ingenieure angewiesen sind.
Die Daten hinter der Physik verkleinern
Jedes Mal, wenn ein simuliertes Neutron durch einen virtuellen Reaktorkern wandert, fragt der Code große Tabellen ab, die beschreiben, wie wahrscheinlich es ist, dass es gestreut, absorbiert oder eine Spaltung auslöst. Diese Tabellen, genannt Kernreaktordatenbanken, kodieren Wahrscheinlichkeiten über tausende Energiepunkte für viele Isotope im Brennstoff und seinen Zerfallsprodukten. Die Autoren bauen auf einer früheren Methode des Maschinellen Lernens auf, die diese Tabellen „verdünnt“: sie entfernt redundante Energiepunkte, während scharfe Merkmale wie Reaktionsschwellen und Resonanzpeaks erhalten bleiben, an denen sich Wahrscheinlichkeiten schnell ändern. Anstatt die Daten durch eine lange, traditionelle Verarbeitungskette neu zu erzeugen, bearbeitet die Methode OpenMCs native HDF5‑Dateien direkt und behält nur etwa 10–50 % der ursprünglichen Gitterpunkte für 23 besonders wichtige Nuklide.
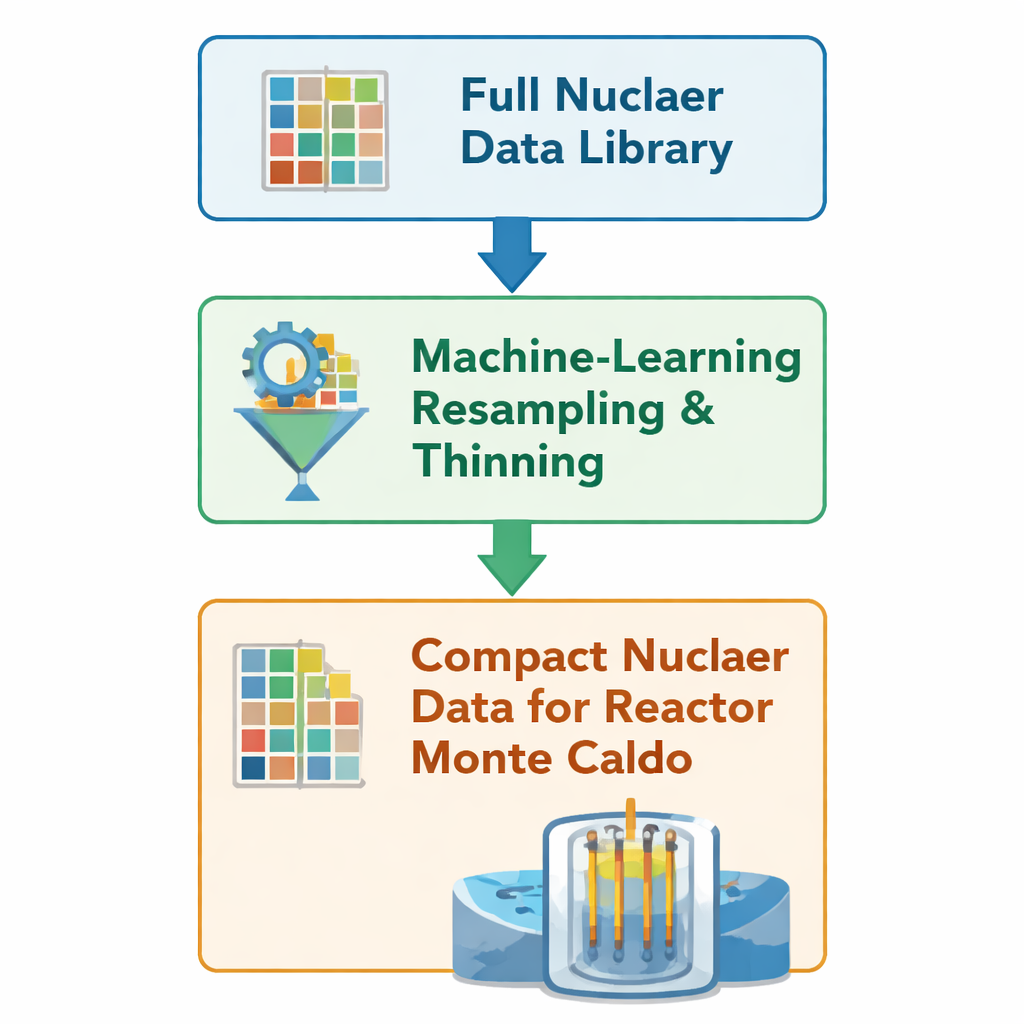
Die Idee an vollständigen Reaktorkernen testen
Um zu prüfen, ob diese schlankeren Daten in realistischen Szenarien noch vertrauenswürdige Ergebnisse liefern, führen die Forschenden jahr‑lange Simulationen zweier großer Druckwasserreaktoren durch: eines European Pressurized Reactor (EPR) und eines VVER‑1000, und nutzen dabei den Open‑Source‑Monte‑Carlo‑Code OpenMC. Für jeden Kern führen sie zwei ansonsten identische Kampagnen durch: eine mit der vollständigen Kernreaktordatenbank und eine mit der maschinell verdünnten Version. Geometrie, Betriebsbedingungen und numerische Einstellungen bleiben unverändert; nur die Datentabellen hinter der Physik unterscheiden sich. Weitere Beschleunigungsfunktionen innerhalb von OpenMC werden abgeschaltet, sodass jede Veränderung in Geschwindigkeit oder Speicherverbrauch direkt auf die reduzierten Daten zurückgeführt werden kann und nicht auf Änderungen in Algorithmen oder Einstellungen.
Geschwindigkeitsgewinne bei engen Fehlerschranken
Die Einsparungen sind erheblich. Im EPR‑Fall sinkt die gesamte Wand‑Uhrzeit um etwa 18 %, beim VVER‑1000 verkürzt sich die Laufzeit um rund 43 %. Der Speicherbedarf verändert sich moderater: die Spitzennutzung fällt im EPR um etwa 4 % und steigt im VVER‑1000 um etwa 5 %, was Unterschiede darin widerspiegelt, wie viel Zeit jedes Modell mit dem Abruf von Kernreaktordaten gegenüber der Verfolgung von Teilchenbahnen durch die Geometrie verbringt. Entscheidend ist, dass die wichtigsten reaktorweiten Kennwerte sehr nahe an den Originalen bleiben. Über ein volles Jahr im VVER‑1000 weicht der effektive Multiplikationsfaktor — im Wesentlichen, wie viele Neutronen jede Spaltung im Durchschnitt erzeugt — nie um mehr als etwa 100 Teile pro Million ab, typischerweise nur um wenige Dutzend Teile pro Million. Für relevante Reaktionskanäle wie Spaltung in Uran‑235 und Uran‑238 sowie Neutroneneinfang in Xenon‑135 und Samarium‑149 bleiben die mittleren Differenzen deutlich unter einem Zehntel Prozent.
Brennstoffentwicklung und Giftstoffe bleiben im Rahmen
Da das Langzeitverhalten eines Reaktors nicht nur von sofortigen Reaktionen abhängt, sondern auch davon, wie Brennstoff und Spaltprodukte sich aufbauen und abbrennen, verfolgen die Autoren außerdem die sich ändernden Inventare wichtiger Isotope. Sie untersuchen die Hauptisotope des Urans, eine Reihe von Plutoniumisotopen, die aus Uran‑238 gezüchtet werden, und starke „Giftstoff“‑Nuklide, die Neutronen aufnehmen, insbesondere Xenon‑135 und Samarium‑149. Selbst nach einem vollen Jahr sind die Unterschiede in diesen Beständen zwischen den Fällen mit vollständigen und reduzierten Daten winzig: in der Größenordnung weniger Hundertstel Prozent für Xenon und Samarium und allgemein unter einem Zehntel Prozent für die Plutoniumarten. Uran‑235 und Uran‑238, die die Energieerzeugung und das neutronische Gleichgewicht im Kern dominieren, werden deutlich feiner als ein Hundertstel Prozent reproduziert. Wo bei einigen Plutoniumisotopen relative Fehler kurzzeitig über ein Prozent liegen, geschieht dies früh im Zyklus, wenn ihre absoluten Mengen noch extrem gering sind, sodass die praktische Auswirkung auf das Reaktorverhalten vernachlässigbar ist.
Was das für zukünftige Reaktormodellierung bedeutet
Für Nicht‑Spezialisten ist die zentrale Botschaft: Ein sorgfältig trainiertes Verfahren des Maschinellen Lernens kann die nuklearen „Nachschlagetabellen“ in fortgeschrittenen Reaktorsimulationen deutlich kleiner und schneller nutzbar machen, während das simulierte Reaktorverhalten nahezu ununterscheidbar von der traditionellen Vorgehensweise bleibt. Die Studie zeigt dies für zwei Reaktorkerne in Industriegröße über ein volles Jahr Betrieb mit Fehlermargen, die im Vergleich zu anderen typischen Unsicherheiten in der Reaktoranalyse klein sind. Die Autoren betonen, dass ihre Schlussfolgerungen derzeit für stationäre Druckwasserreaktoren mit einer spezifischen Datenbank und Codesettings gelten und dass weitere Arbeit nötig ist, um andere Reaktortypen und transiente Bedingungen zu testen. Dennoch deuten die Ergebnisse auf einen vielversprechenden Weg zu schnelleren, effizienteren hochaufgelösten Kernsimulationen hin, der mehr Designstudien und Sicherheitsanalysen mit begrenzten Rechenressourcen ermöglichen könnte.
Zitation: Hashemi, A., Macián-Juan, R. & Ohlerich, M. Evaluating machine learned nuclear data precision in full core nuclear reactor Monte Carlo neutronics and computational efficiency analyses. Sci Rep 16, 1314 (2026). https://doi.org/10.1038/s41598-026-35227-9
Schlüsselwörter: Simulation von Kernreaktoren, Maschinelles Lernen, Monte‑Carlo‑Neutronik, Kernreaktordatenbanken, Druckwasserreaktoren