Clear Sky Science · de
Effiziente Erkennung von KI-generierten wissenschaftlichen Abstracts mit einem leichten Transformer
Warum das Erkennen von KI-verfasstem Wissenschaftstext wichtig ist
Da künstliche Intelligenz immer besser im Schreiben wird, kann sie nun wissenschaftliche Zusammenfassungen verfassen, die kaum noch von menschlichen Texten zu unterscheiden sind. Das wirft schwierige Fragen auf: Wie können Zeitschriften, Universitäten und Leser sicher sein, dass ein Abstract wirklich die Arbeit einer Wissenschaftlerin oder eines Wissenschaftlers widerspiegelt und nicht die Erfindung einer Maschine ist? Dieses Paper geht das Problem an, indem es ein schnelles, kompaktes Werkzeug entwickelt, das KI-verfasste wissenschaftliche Abstracts mit sehr hoher Zuverlässigkeit erkennt und damit einen praktikablen Schutz für die akademische Integrität bietet.
Aufbau eines Testdatensatzes aus realen und synthetischen Abstracts
Um KI-Text-Erkennung zu messen und zu verbessern, brauchten die Autor:innen zunächst verlässliche Daten. Sie sammelten 5.000 wissenschaftliche Abstracts von dem Preprint-Server arXiv aus fünf Bereichen: Computer Vision, Signalverarbeitung, quantitative Biologie, Physik und weiteren Informatikthemen. Zu jedem menschlich verfassten Abstract erzeugten sie mit einem großen Sprachmodell eine KI-Version anhand des Titels des Papers, prüften sorgfältig auf nahezu identische Texte und entfernten offensichtliche Hinweise wie Webadressen oder Code-Snippets. Sie sorgten außerdem dafür, dass KI- und Menschentexte ähnliche Längen hatten, damit der Detektor nicht einfach auf grobe Statistiken wie Wortzahl zurückgreifen konnte.
Ein kompaktes Modell für die reale Welt
Statt ein sehr großes und teures KI-Modell zu verwenden, entschieden sich die Forschenden für ein kleineres System namens DistilBERT, eine gestraffte Version eines bekannten Sprachmodells. Sie feinjustierten es so, dass es für jedes Abstract entscheidet, ob es von einer Person geschrieben oder von KI erzeugt wurde. Das Modell liest bis zu 256 Tokens — ungefähr ein paar Absätze — und gibt eine Punktzahl zwischen null und eins aus, interpretiert als Wahrscheinlichkeit, dass der Text maschinell geschrieben ist. Das Training und die Evaluation folgten einem strengen Protokoll: Die Daten wurden in Trainings-, Validierungs- und Testmengen ohne Überlappung aufgeteilt, und das Team berichtete nicht nur die Genauigkeit, sondern auch, wie sich das Modell verhält, wenn die zulässige Fehlalarmrate sehr niedrig gehalten wird — ein Bereich, der wichtig ist, wenn man reale Autor:innen des KI-Einsatzes beschuldigt.
Wie gut der Detektor funktioniert
Bei Abstracts aus dem Bereich Computer Vision, dem Haupttestfeld, war der Detektor bemerkenswert präzise. Er klassifizierte 499 von 500 KI-generierten Texten korrekt und 495 von 500 menschlichen Texten korrekt, erreichte damit etwa 99,4 % Genauigkeit und einen nahezu perfekten Wert auf einer standardmäßigen Performance-Kurve. Wenn die Autor:innen das System zwangen, maximal einen Fehlalarm pro hundert Fälle zuzulassen, fing es dennoch etwa 90 % der KI-Texte; bei einer etwas höheren Toleranz von fünf Fehlalarmen pro hundert erkannte es rund 97 %. Im Vergleich zu einer Reihe von Alternativen — einschließlich einfacherer statistischer Werkzeuge und anderer Transformer-Modelle — schnitt der kompakte Detektor besonders in anspruchsvolleren Szenarien durchweg am besten ab.
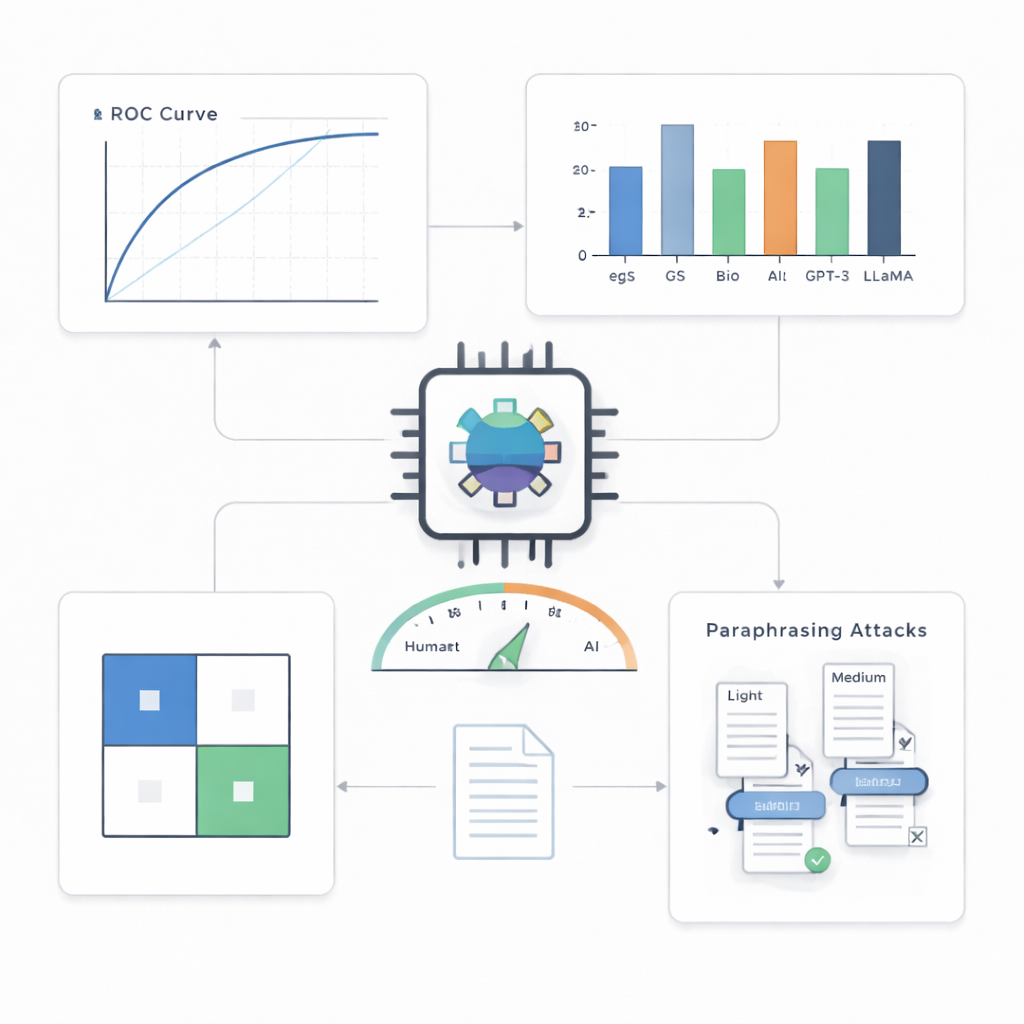
Über ein Fachgebiet, ein Modell und einfache Tricks hinaus
Eine zentrale Frage ist, ob ein solcher Detektor mit Schreibstilen und KI-Systemen zurechtkommt, die er nie zuvor gesehen hat. Die Autor:innen testeten ihn an Abstracts aus anderen wissenschaftlichen Feldern und an Texten, die von mehreren verschiedenen fortschrittlichen Sprachmodellen verfasst wurden. Über die Domänen hinweg blieb die Leistung stark, mit nur moderaten Einbußen, was darauf hindeutet, dass das System allgemeine Muster maschinellen Schreibens erfasst und nicht nur Besonderheiten eines Fachgebiets. Gegenüber unbekannten KI-Modellen funktionierte es ebenfalls gut, wenn auch nicht ganz so perfekt wie in seiner Heimkonfiguration. Die schwierigste Herausforderung kamen von Paraphrasierungsangriffen: Wenn eine andere KI maschinell erzeugte Abstracts so umschrieb, dass sie anders klingen, aber dieselbe Bedeutung behielten, wurde die Erkennung deutlich schwerer. Bei Umschreibungen mittlerer Stärke stieg der Anteil der durchrutschenden KI-Texte auf nahezu 30 % — ein Hinweis darauf, dass selbst ausgefeilte Detektoren durch gezielte Verschleierung getäuscht werden können.
Was das für die Wissenschaft und ihre Schutzmechanismen bedeutet
Die Studie zeigt, dass KI-verfasste wissenschaftliche Abstracts derzeit noch subtile Spuren hinterlassen, die ein gut gestaltetes Modell aufspüren kann, selbst wenn dieses Modell klein genug ist, um auf moderater Hardware zu laufen. Damit wird es für Verlage, Konferenzen und Universitäten möglich, große Mengen an Einreichungen zu prüfen, ohne enorme Rechenkosten. Zugleich macht die Anfälligkeit gegenüber Paraphrasierung deutlich, dass solche Werkzeuge keine Allheilmittel sind. Die Autor:innen plädieren dafür, die Erkennung von KI-Texten mit anderen Schutzmaßnahmen zu kombinieren — etwa redaktionellem Ermessen, Plagiatsprüfungen und Transparenzpflichten —, um die Vertrauenswürdigkeit wissenschaftlicher Kommunikation zu sichern, während sich KI-Systeme weiter verbessern.
Zitation: Zhang, C., Zhou, W. Efficient detection of AI-generated scientific abstracts with a lightweight transformer. Sci Rep 16, 4975 (2026). https://doi.org/10.1038/s41598-026-35203-3
Schlüsselwörter: Erkennung von KI-Texten, wissenschaftliche Abstracts, akademische Integrität, große Sprachmodelle, maschinell erzeugter Text